REGEN: 自然言語によるパーソナライズドレコメンデーションの強化
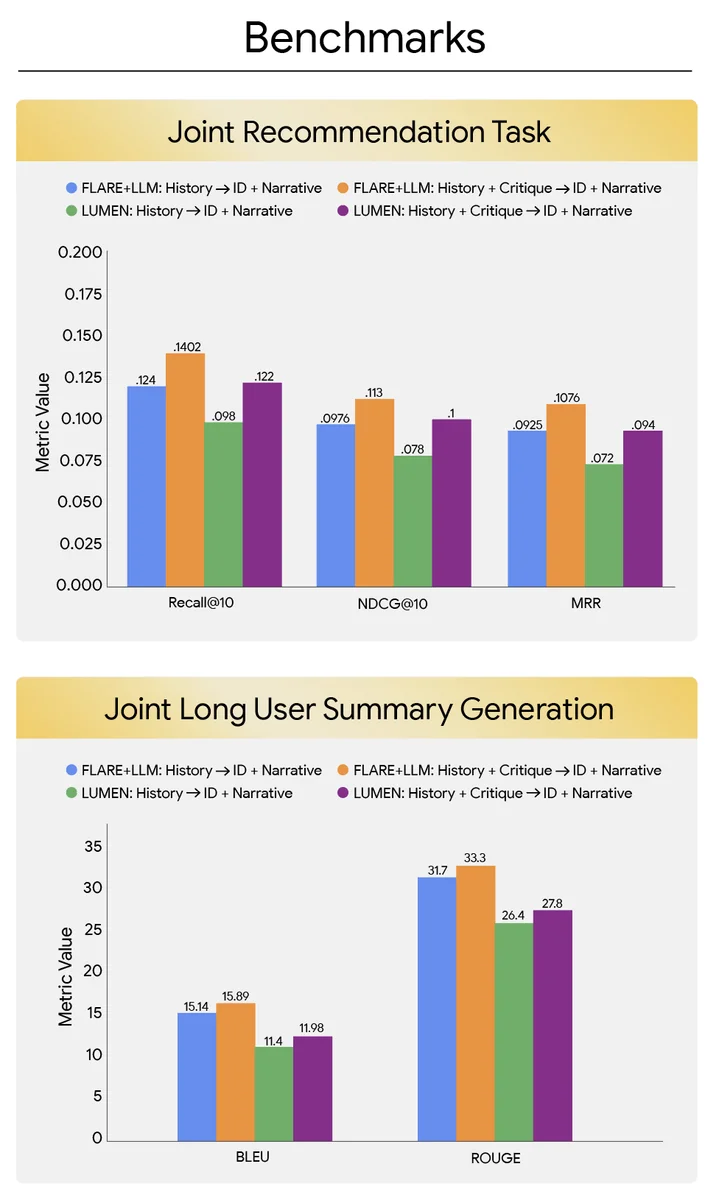
大規模言語モデルの出現により、レコメンダーシステムがユーザーとの相互作用を変革しています。ユーザーが次に好むアイテムを予測することを超えて、ユーザーのニーズを理解し、自然言語フィードバックに基づいて適応しています。ただし、これらの新しい機能を探索するためのデータセットが存在しません。そのため、新しいベンチマークデータセットであるReviews Enhanced with GEnerative Narratives(REGEN)が開発されました。REGENは、アイテムのレコメンデーション、自然言語の特徴、およびパーソナライズドなナラティブを組み合わせて、新しいレコメンダーアーキテクチャーの探索とベンチマークを可能にします。このデータセットは、Amazon Product ReviewsデータセットをGemini 1.5 Flashモデルを使用して生成された合成のユーザークリティクスとナラティブで拡張しました。REGENは、ユーザーフィードバックを組み込み、レコメンデーションに一致する自然言語を出力するモデルの評価を可能にします。実験結果によると、大規模言語モデルのREGENトレーニングは、レコメンデーションとコンテキストナルナラティブの両方を効果的に生成でき、最新のレコメンダーと言語モデルのパフォーマンスに匹敵します。このデータセットには、ユーザーの好みを表現するクリティクスと、推奨アイテムに関する豊富なコンテキスト情報を提供するナラティブが含まれています。2つのベースラインアーキテクチャーが、異なるモデリングアプローチを探索するために開発されました:ハイブリッドシステムと、完全に生成的なモデルであるLUMEN。結果は、REGENが、レコメンデーションと生成タスクの両方でモデルを有意に挑戦し、区別することができ、ユーザークリティクスの入力を組み込むことで、レコメンデーションメトリクスを一貫して改善することができることを示しています。REGENは、会話型レコメンダーモデルの能力を研究するための基本的なリソースを提供し、会話型レコメンデーションを推進するために言語を基本的な要素として統合しています。