ユーザーレベルの差分プライバシーを用いたLLM(大規模言語モデル)のファインチューニング
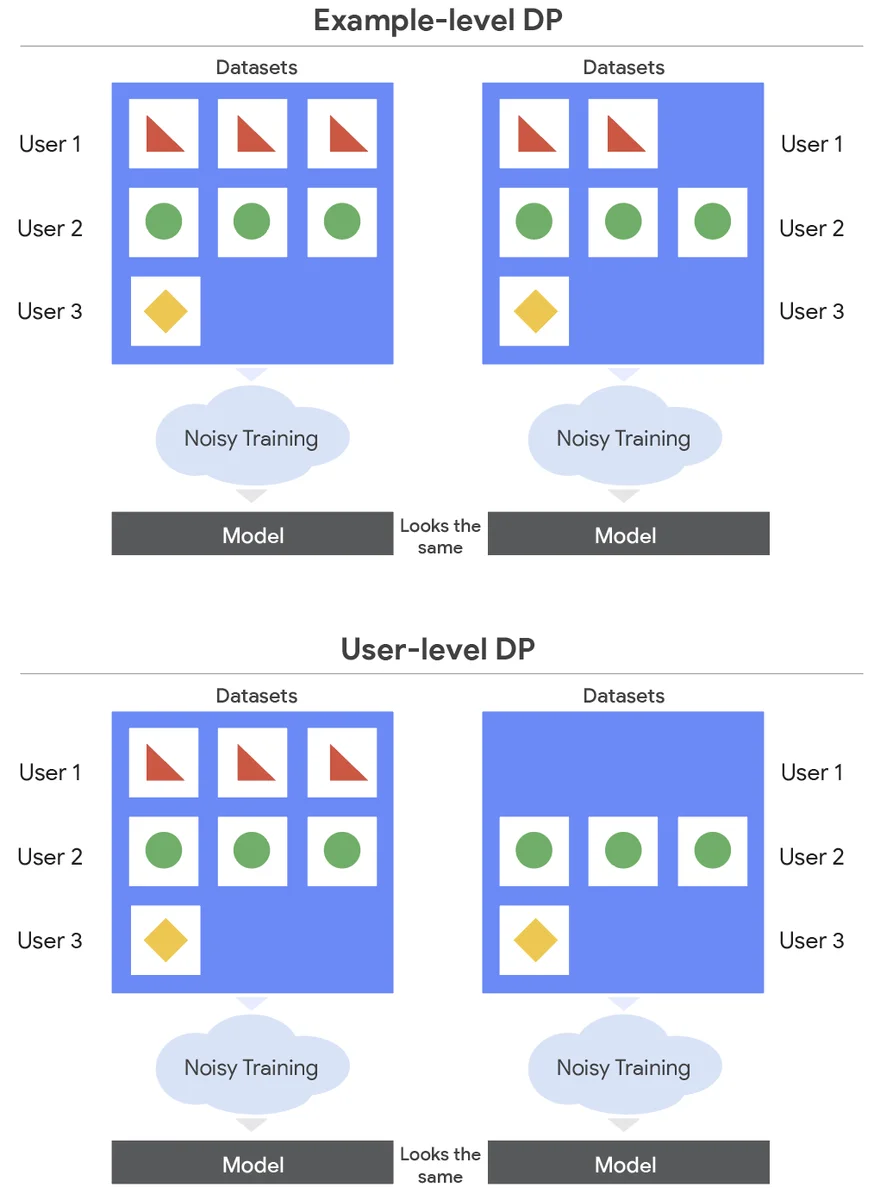
機械学習モデルは、ドメイン固有のデータでファインチューニングする必要がありますが、プライバシーに関する懸念により、これは問題となる可能性があります。差分プライバシー(DP)は、プライバシーを尊重しながらモデルをトレーニングすることを可能にしますが、ほとんどの研究は、欠点がある例レベルのDPに焦点を当てています。ユーザーレベルのDPは、攻撃者がユーザーのデータについて学ぶことができないことを保証する、プライバシーのより強い形式であり、フェデレーテッドラーニングで使用されます。ユーザーレベルのDPで学習することは困難であり、ノイズを追加する必要があり、これはモデルが大きくなるにつれて悪化します。この論文は、データセンターのトレーニングでユーザーレベルのDPを使用して大規模な言語モデルをファインチューニングすることに焦点を当てています。著者は、ノイズを追加し、各ユーザーがモデルに与える影響を制限するために、確率的勾配降下法(SGD)を変更します。著者は、データのサンプリング方法が異なる2つの方法、例レベルのサンプリング(ELS)とユーザーレベルのサンプリング(ULS)を比較します。著者は、これらのアルゴリズムを大規模な言語モデルに最適化し、一般にULSが優れていることを発見し、両方の方法は、厳格なプライバシー要件にもかかわらず、ファインチューニングを行わない場合よりも優れています。これらの最適化により、モデルトレーナーは、強力なユーザー保護を提供しながら、機密データセットにモデルをファインチューニングできます。