RSS 구글 AI 블로그
팔로우
차등 개인정보보호 파티션 선택을 통한 대규모 비공개 데이터 보안
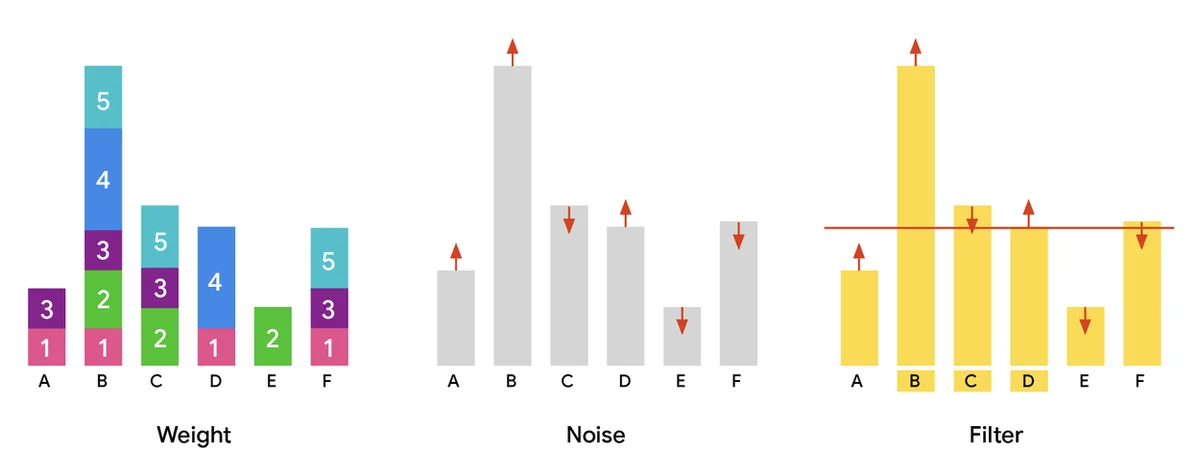
"AI 발전, 서비스 개선, 개인화를 위해 대규모 사용자 기반 데이터셋이 필수적입니다. 이러한 데이터셋을 공유하면 연구를 가속화하지만 프라이버시 위험을 초래합니다. 차등 프라이버시(DP) 파티션 선택은 개인 기여도를 보호하기 위해 노이즈를 추가하여 안전한 공통 데이터 하위 집합을 식별합니다. 이는 어휘 추출 및 프라이버시 데이터 분석과 같은 작업에 필수적입니다. 대규모 데이터셋을 처리하려면 속도뿐 아니라 엄청난 규모를 처리하는 병렬 알고리즘이 필요합니다. 우리의 출판물, "적응 가중치를 통한 확장 가능한 프라이버시 파티션 선택"에서는 DP 파티션 선택을 위한 효율적인 병렬 알고리즘을 소개합니다. 이 알고리즘은 수백억 개의 항목까지 확장할 수 있으며, 이전의 기능을 대폭 초과합니다. 목표는 사용자 프라이버시를 보존하면서 선택된 항목을 최대화하는 것입니다. 표준 접근 방식은 가중치 추가, 노이즈 추가 및 임계값에 기반한 항목 필터링입니다. 우리의 새로운 적응 가중치 알고리즘, MAD는 프라이버시 임계값 바로 아래에 있는 항목에 "과잉 가중치"를 재할당하여 유틸리티를 개선합니다. 이를 통해 프라이버시 또는 확장성을 손상시키지 않고 더 많은 항목을 포함할 수 있습니다. 실험 결과, 2회 반복 MAD 알고리즘은 동일한 프라이버시 보장을 가지고 다른 방법보다 더 많은 항목을 출력하는 최적의 결과를 달성합니다. 우리는 커뮤니티 혁신을 촉진하기 위해 알고리즘을 오픈 소스로 공개합니다."