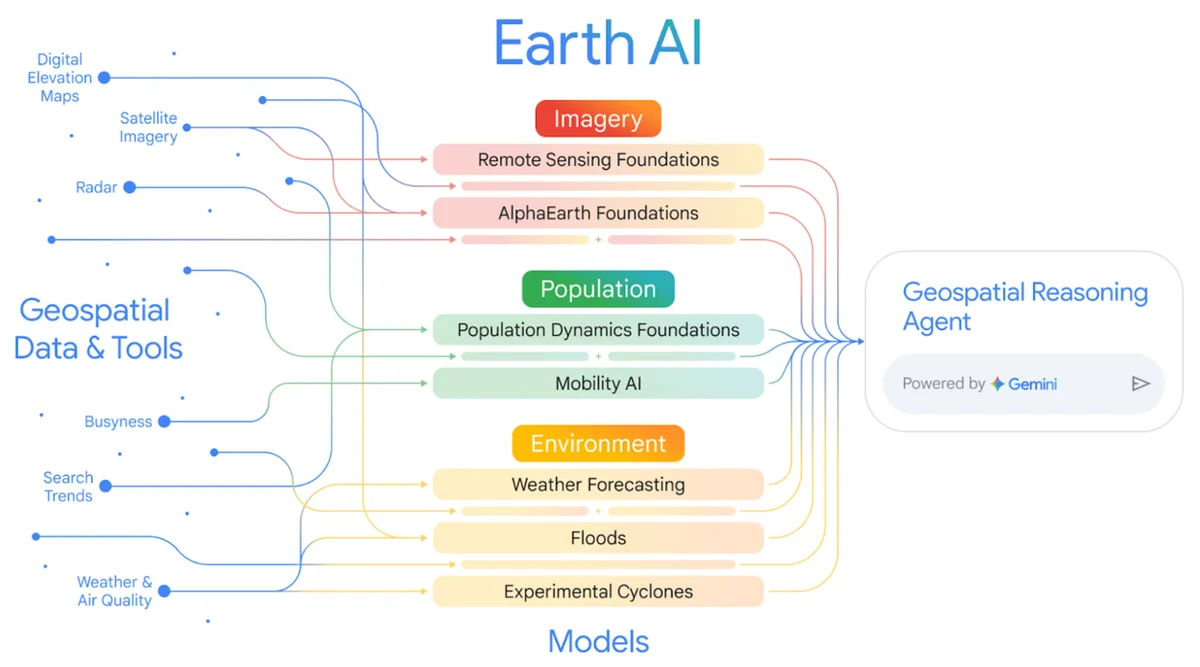
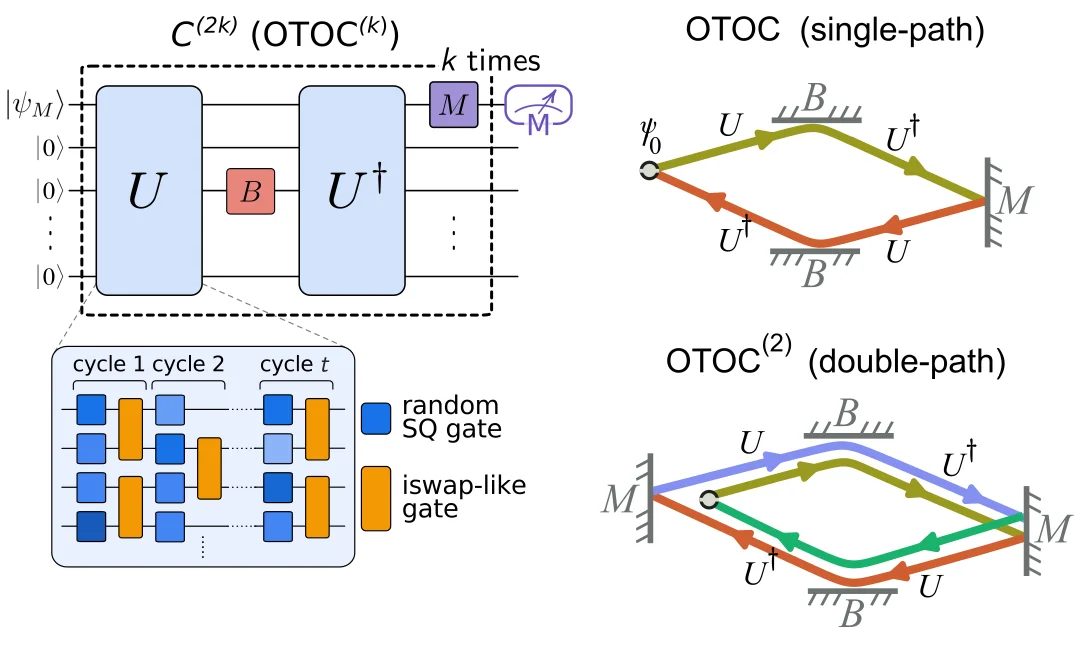
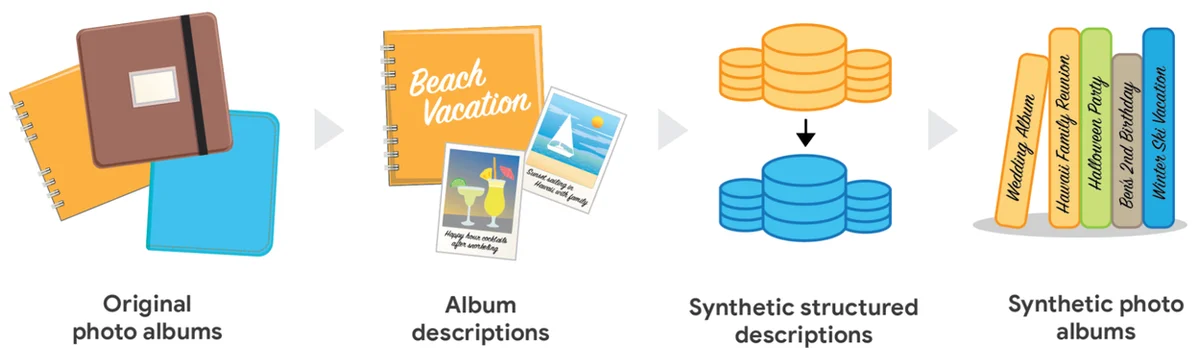
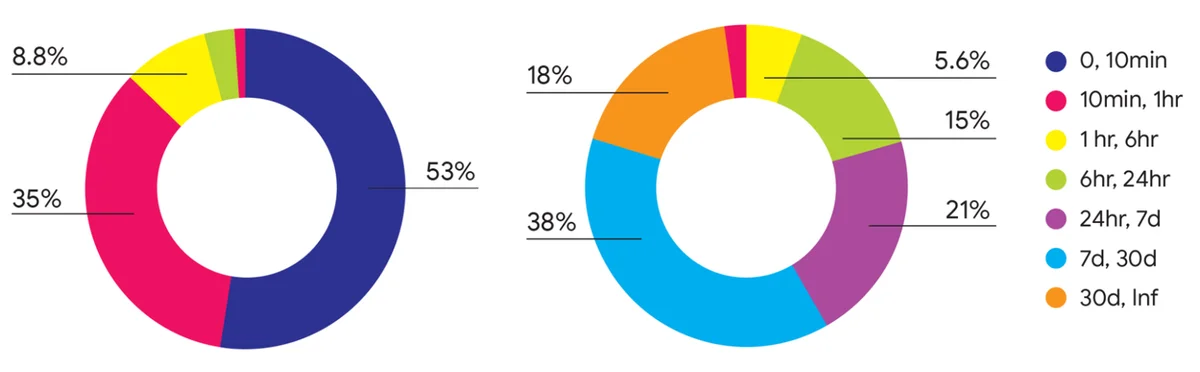
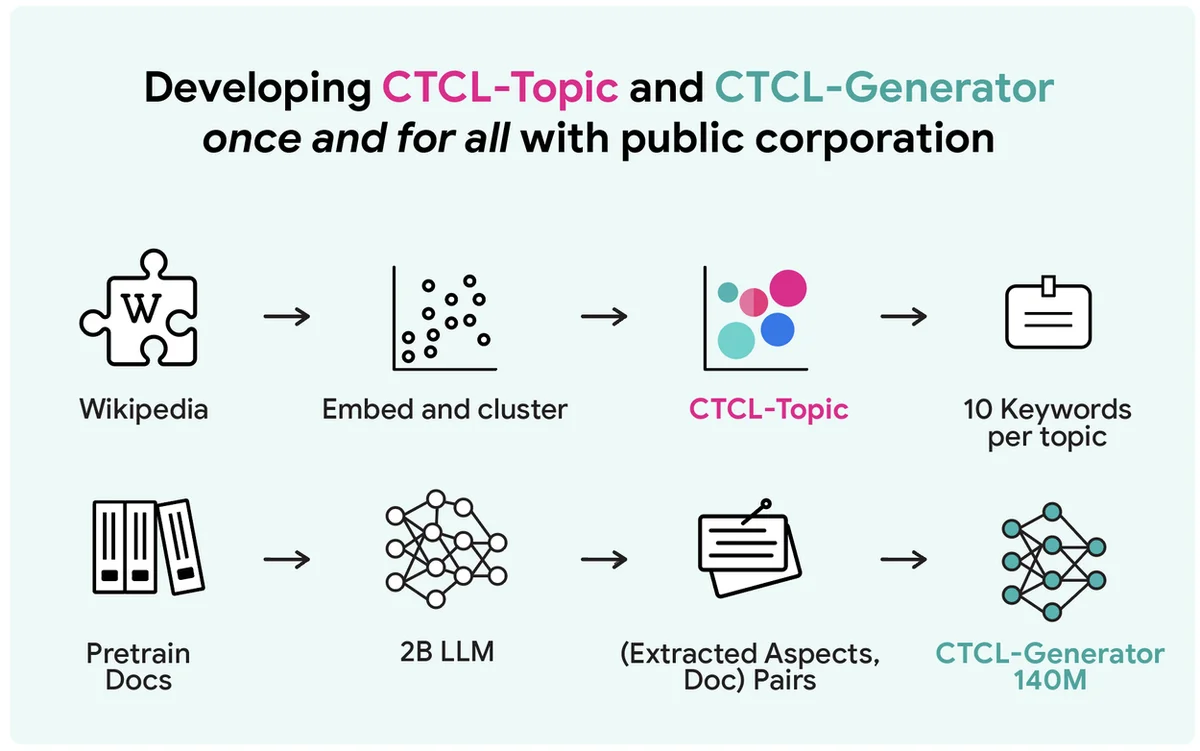
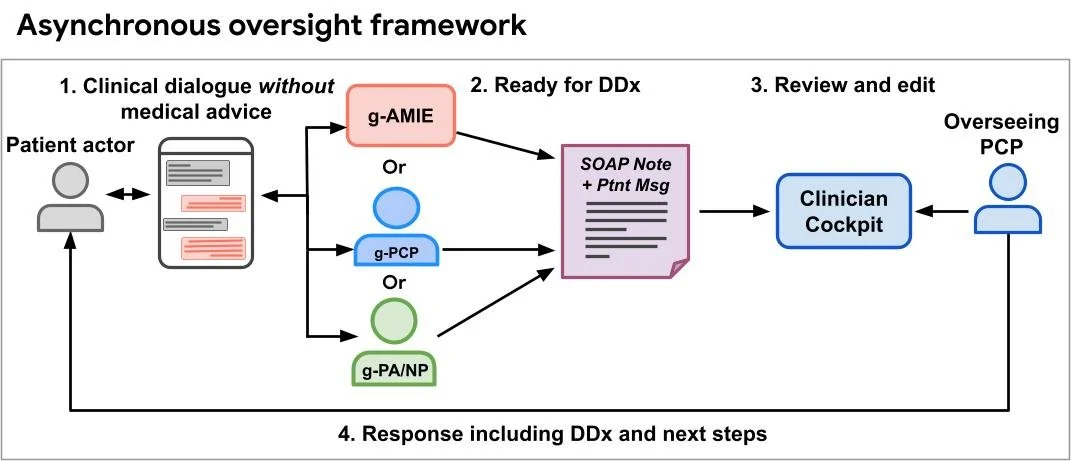
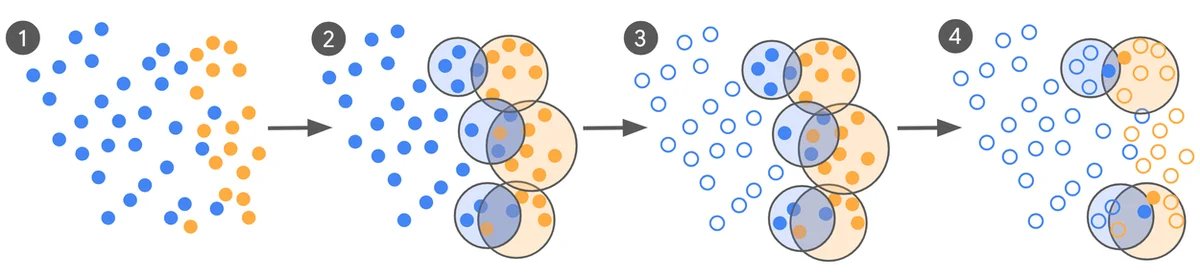
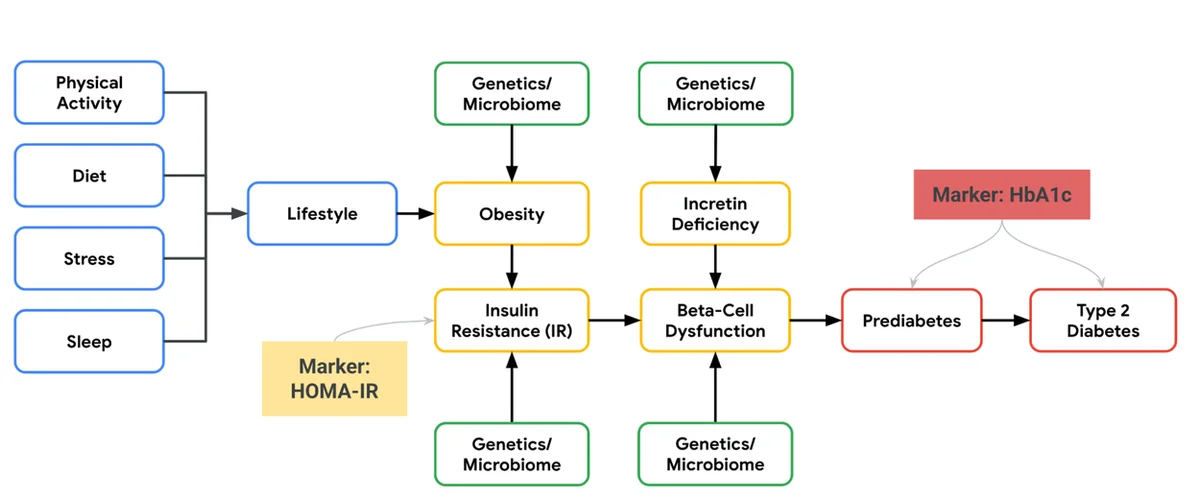
RSS 구글 AI 블로그 팔로우
Google Research는 Google Research의 과학 커뮤니티에서 최신의 돌파구와 통찰을 공유하는 블로그입니다. 이 플랫폼은 과학자들이 과학 원 밖의 사용자와 새로운 기술, 통찰, 혁신에 대해 대화하는 수단으로 작동합니다.
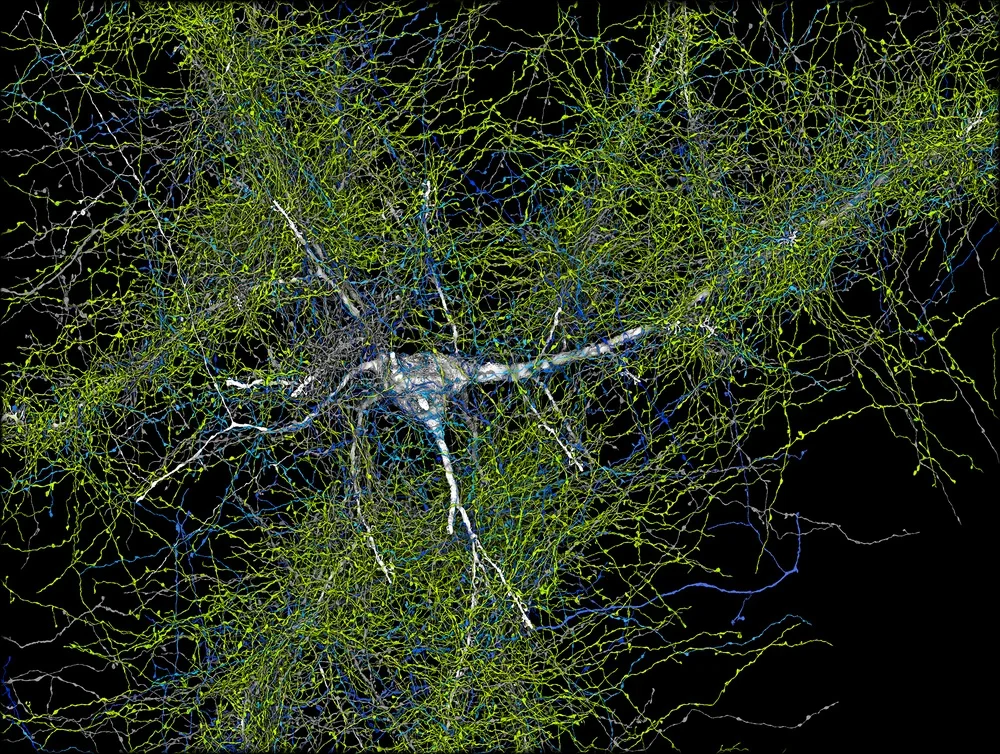
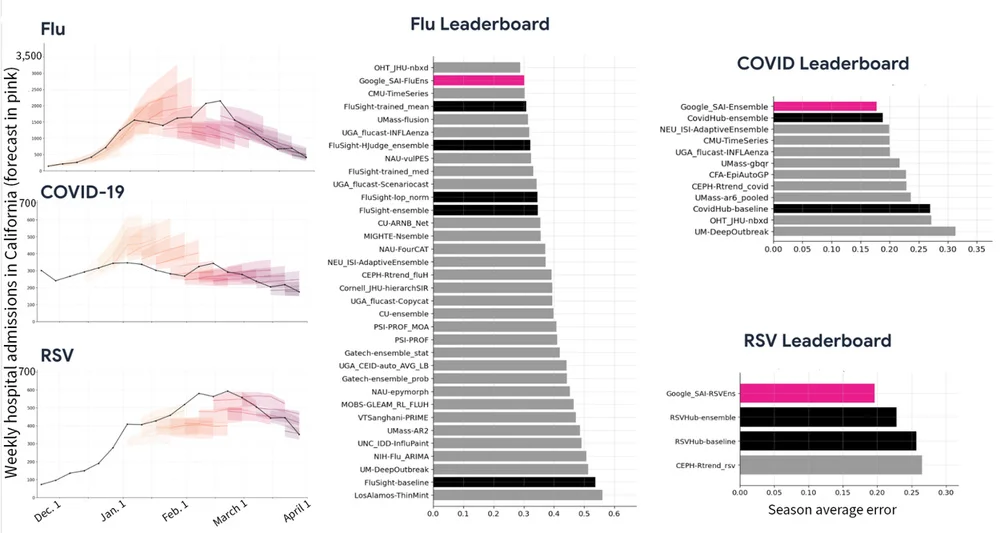
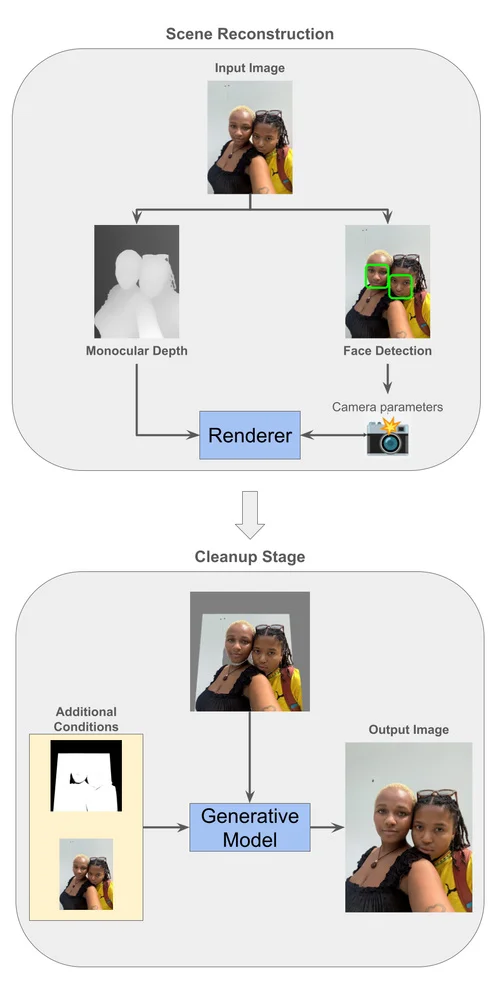
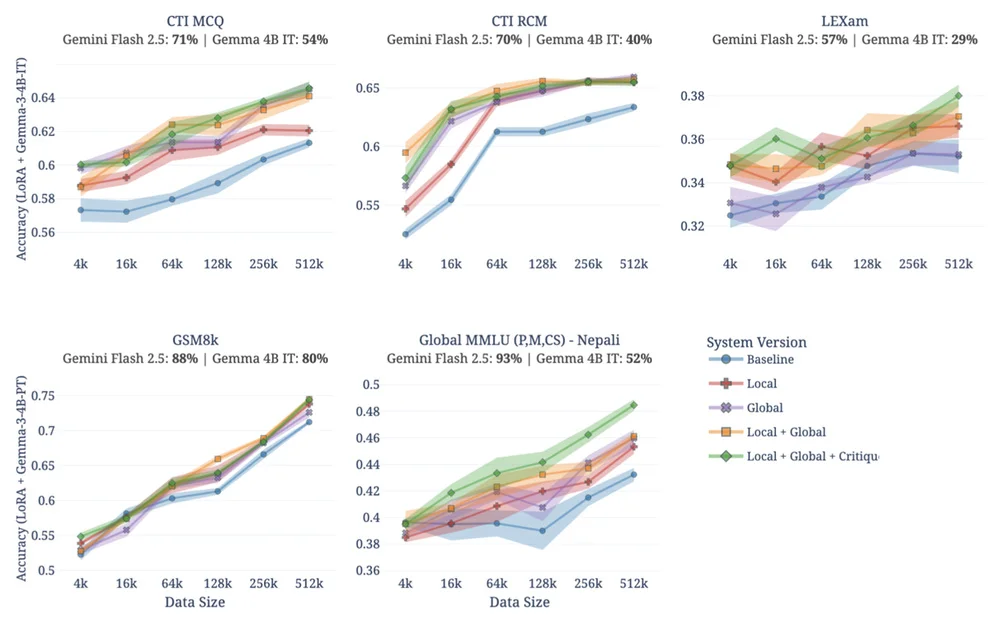
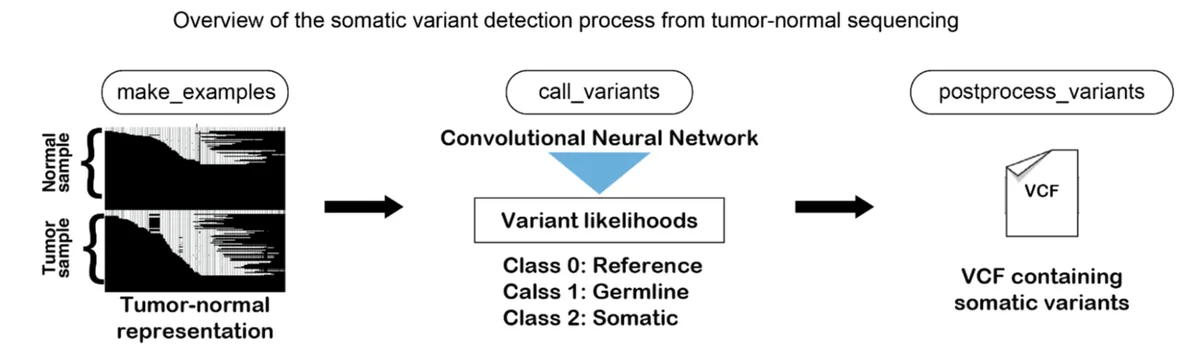
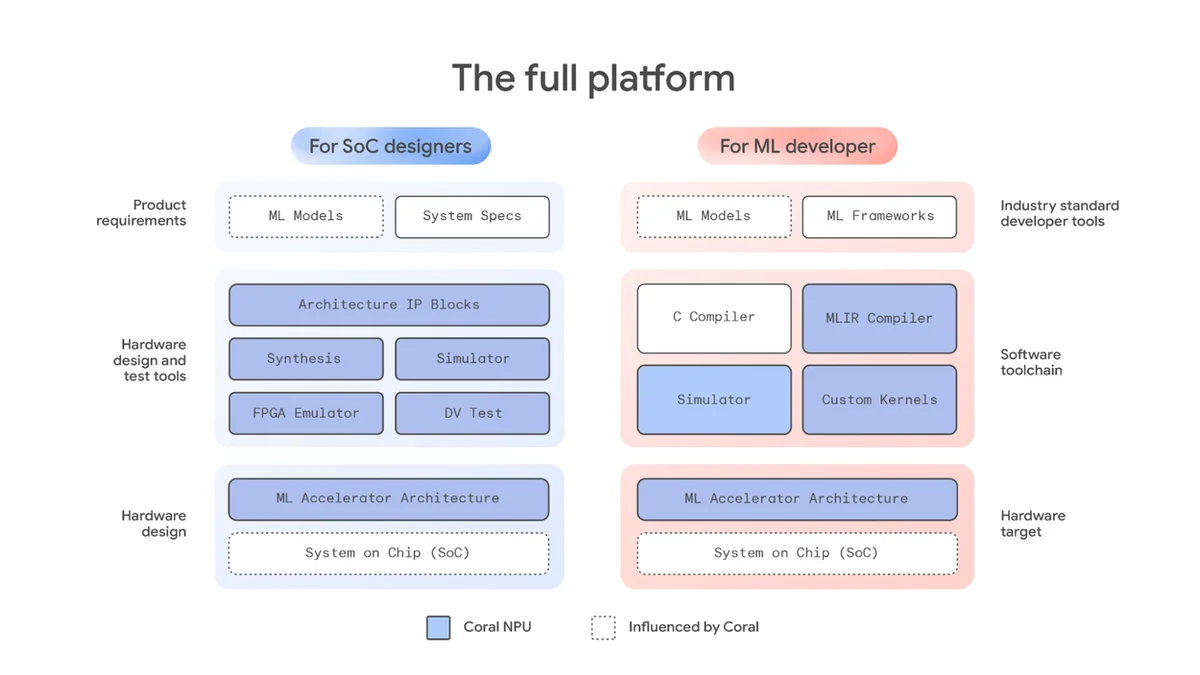
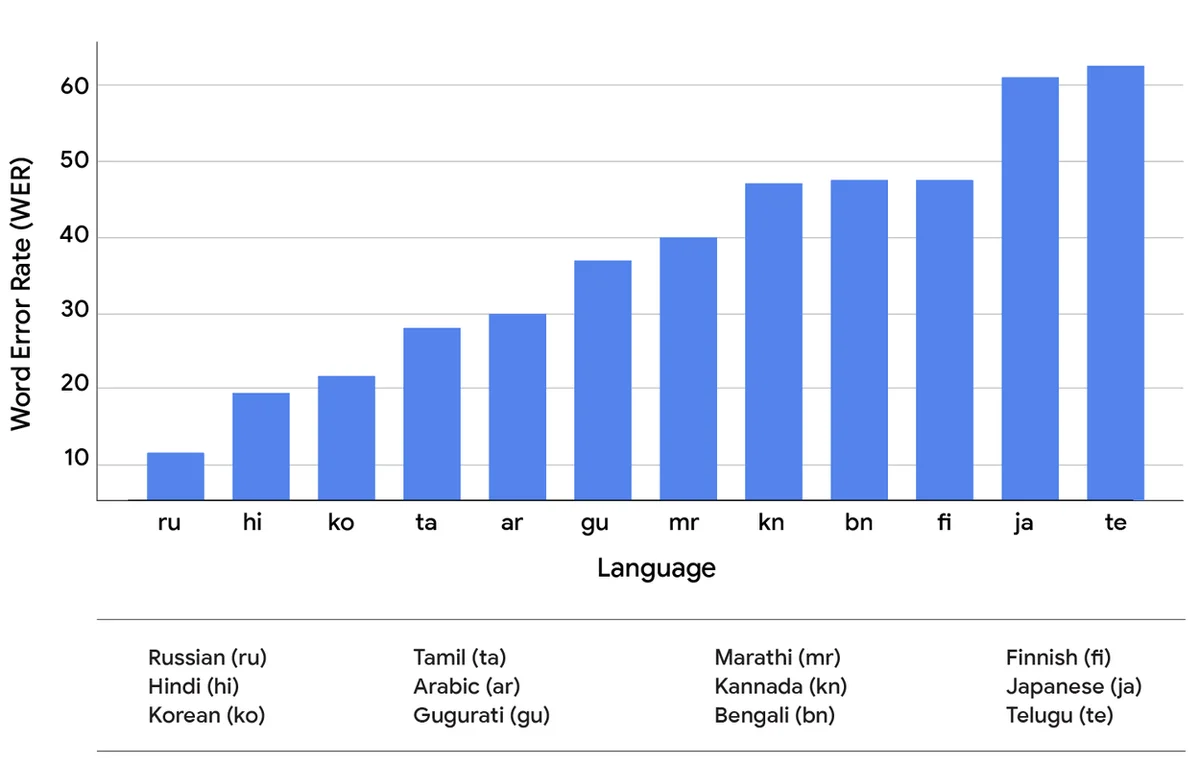
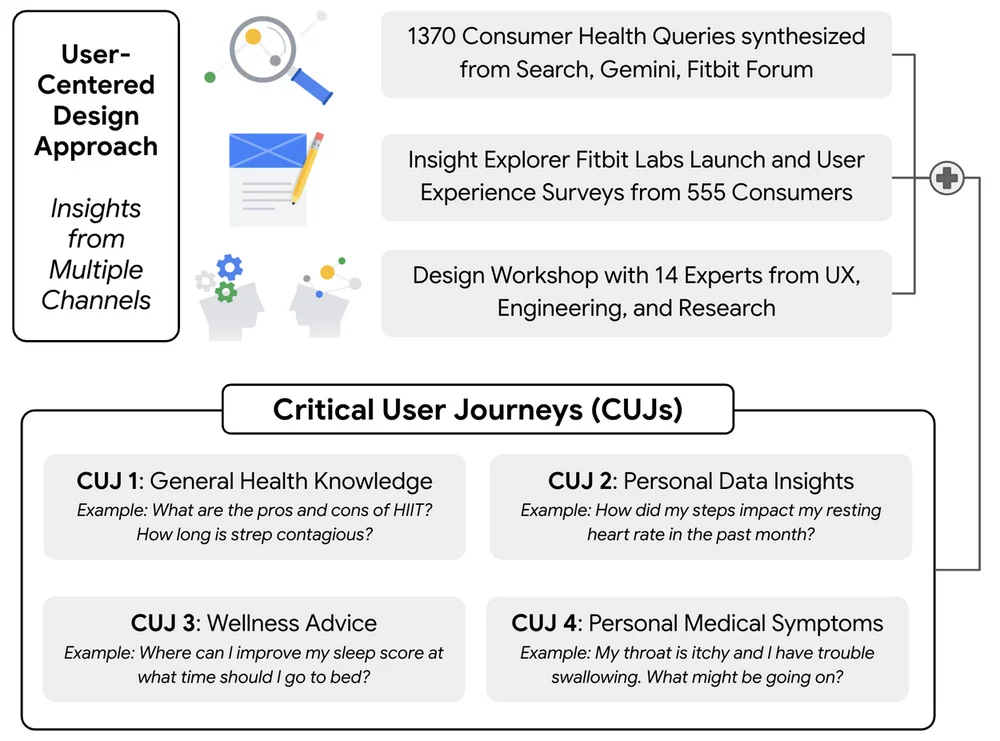
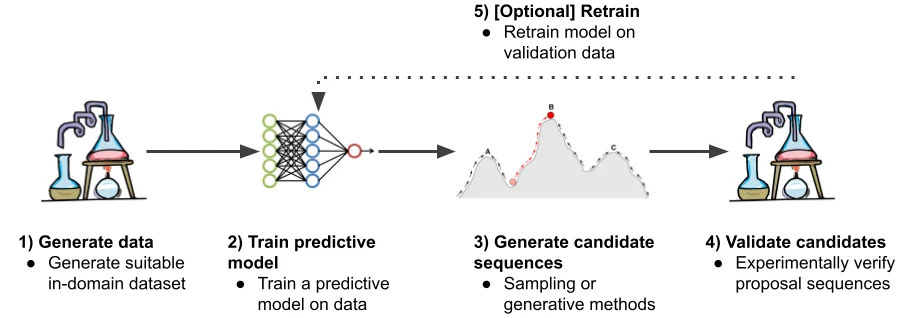
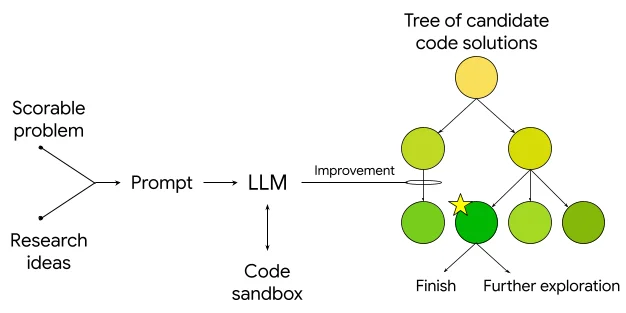
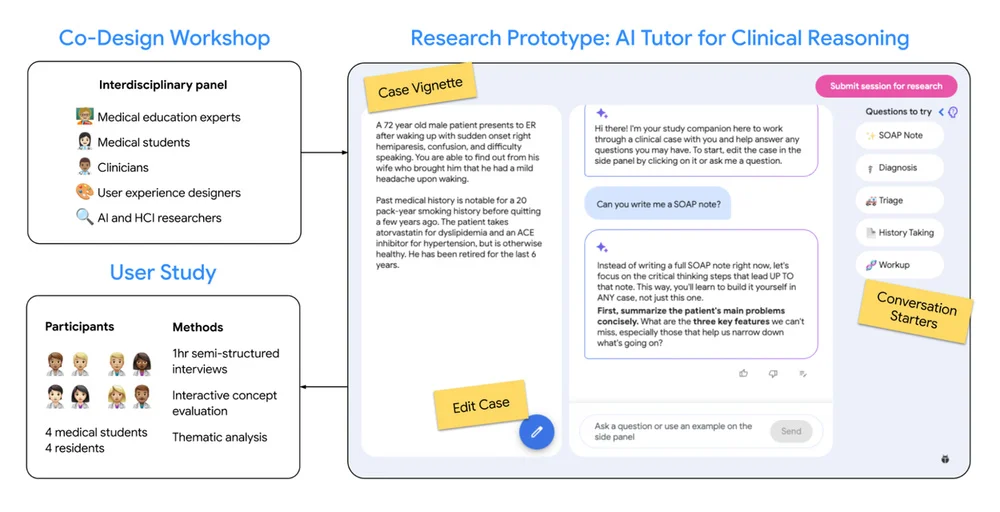
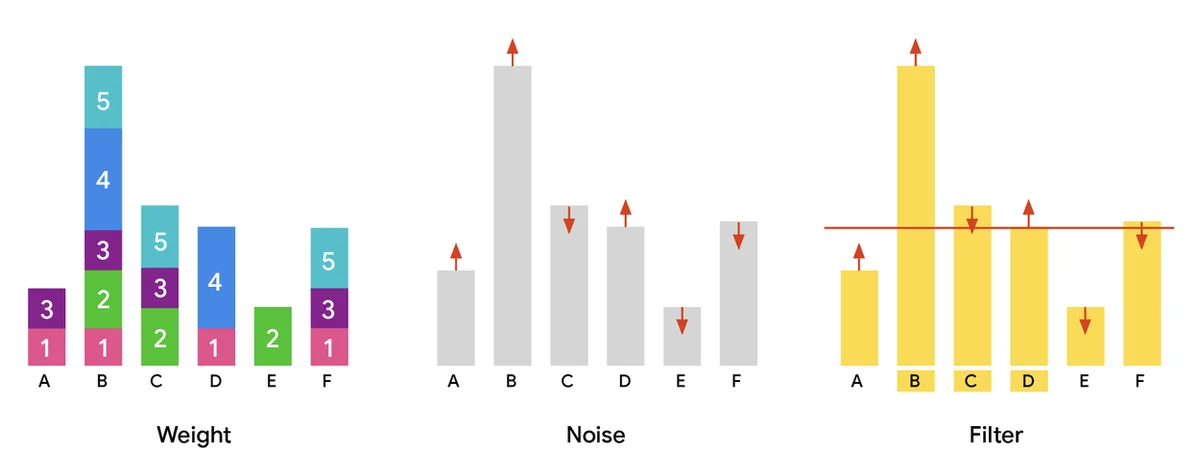
Google Research는 인공 지능, 기계 학습, 의료 혁신 등 다양한 과학 주제에 대한 글을 자주 게시합니다. 또한 자율 주행 차량에서 최신 의료 진단 및 데이터 분석 기법까지 새로운 기술에 대한 글도 자주 다룹니다.
블로그의 주목할만한 기능은 팀 멤버 기고입니다. Google의 주요 기술자 및 연구자들이 다양한 관심사와 기술을 반영하는 통찰적인 글을 제공합니다. 이 사이트는 기술 세계의 최신 발전 및 미래 비전을 첫손으로 읽을 수 있는 기회를 제공합니다.
블로그에는 '저자' 섹션이 있어 사용자가 개별 기고자의 글과 통찰을 접근할 수 있습니다. 기술적 논의 및 혁신 외에도 블로그는 새로운 기술이 우리의 일상 생활에 미치는 영향을 포함하여 사회적 및 철학적 문제들도 다룹니다.
따라서 Google Research 블로그는 기술 전문 지식, 연구 돌파구, 사회적 함의를 독특한 조합으로 제공하여 기술 애호가, 연구자, 미래 기술을 이해하고 형성하고 싶은 모든 사람에게 귀중한 자원이 됩니다.