RSS 구글 AI 블로그
팔로우
LLM을 활용한 모바일 애플리케이션을 위한 합성 및 연합 기반 개인 정보 보호 도메인 적응
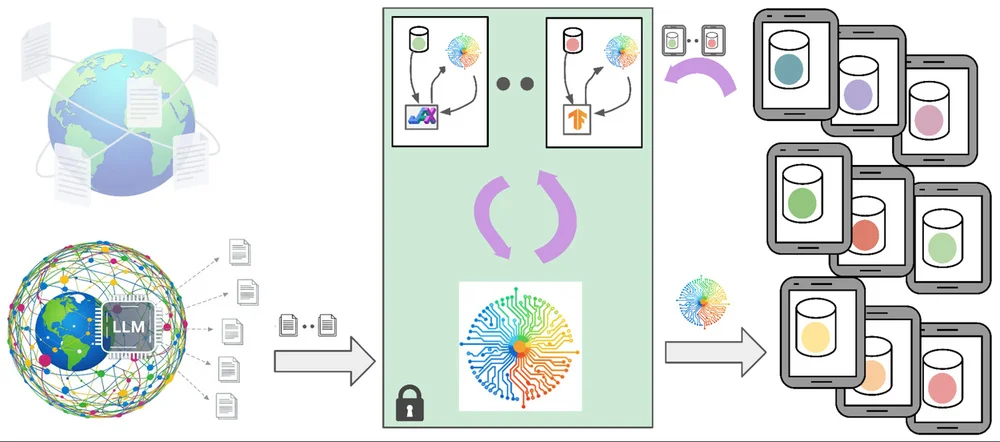
"Google의 Gboard는 타이핑 예측 및 교정 기능에 대규모 및 소규모 언어 모델(LLM 및 LM)을 활용합니다. 이러한 모델을 훈련하려면 고품질 데이터가 필요하지만, 사용자 데이터를 사용하면 개인 정보 보호 문제가 발생합니다. 이를 해결하기 위해 Gboard는 공개 데이터로 훈련된 LLM이 생성한 합성 데이터를 사용하여 개인 정보를 노출하지 않고 사용자 상호 작용을 모방합니다. 이 합성 데이터는 모델을 사전 훈련하여 개인 정보 보호 기술(예: 연합 학습 및 차등 개인 정보 보호)로 추가 훈련하기 전에 성능을 향상시킵니다. 이 접근 방식은 개인 정보 보호 위험을 최소화하는 동시에 모델 정확도를 크게 향상시켜 Gboard 기능 개선으로 이어집니다. 이 과정에는 LLM에 프롬프트를 제공하여 실제 모바일 타이핑 데이터를 생성하고, 이 데이터를 사용하여 소규모 모델을 사전 훈련하는 과정이 포함됩니다. 차등 개인 정보 보호를 사용하여 사용자 데이터로 훈련된 소규모 모델인 "버트레스 모듈"은 도메인 적응력을 높이기 위해 합성 데이터를 추가로 정제합니다. 이 결합된 접근 방식은 소규모 및 대규모 모델 모두를 개선하여 사용자 개인 정보를 보호하면서 Gboard의 기능을 향상시킵니다. 시스템에는 데이터 최소화 및 익명화를 포함한 여러 개인 정보 보호 장치가 통합되어 있습니다. 진행 중인 연구는 모델 성능을 더욱 향상시키고 사용자 경험을 개선하기 위해 개인 정보 보호 강화 합성 데이터의 생성 및 적용을 개선하는 데 중점을 둡니다."