RSS 구글 AI 블로그
팔로우
수십억 개 매개변수의 부담을 넘어: 조건부 생성기로 데이터 합성을 열다
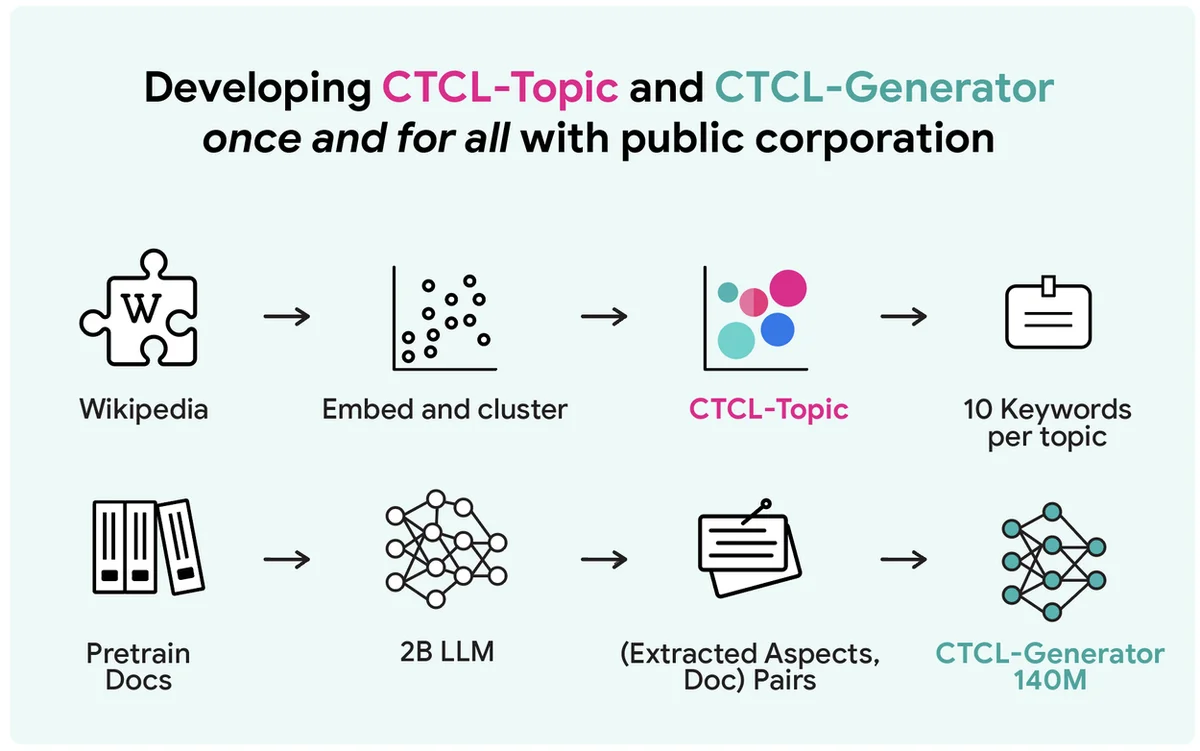
대규모 차분 프라이버시 합성 텍스트 데이터 생성에는 프라이버시-계산-유용성 트레이드오프가 존재합니다. 흔하지만 계산 비용이 많이 드는 방법은 개인 데이터에 대한 대규모 언어 모델의 파인튜닝을 포함합니다. Aug-PE와 같은 기존 API 기반 접근 방식은 수동 프롬프트에 의존하며 개인 정보 활용에 어려움을 겪습니다. 제안된 CTCL 프레임워크는 대규모 LLM을 파인튜닝하거나 광범위한 프롬프트 엔지니어링을 요구하지 않고 프라이버시를 보존하는 합성 데이터를 생성합니다. 1억 4천만 개의 매개변수를 가진 경량 모델을 활용하여 리소스가 제한된 환경에 적합합니다. CTCL은 개인 데이터 분포를 일치시키기 위해 주제 정보에 대한 생성을 조건화합니다. Aug-PE와 달리 CTCL은 추가 프라이버시 비용 없이 무제한의 합성 데이터 샘플을 생산할 수 있습니다. 실험 결과 CTCL은 기준선을 능가하며, 특히 강력한 프라이버시 보장 하에서 유용한 정보를 포착하는 데 효과적임을 보여줍니다. 제거 연구는 CTCL의 성능 및 확장성에 대한 사전 훈련 및 키워드 기반 조건화의 중요성을 확인합니다. CTCL의 핵심 아이디어는 더 나은 실제 애플리케이션을 위해 더 큰 모델로 확장될 수 있습니다.