RSS 구글 AI 블로그
팔로우
실세계용 합성 데이터셋 설계: 메커니즘 설계 및 제1원리로부터의 추론
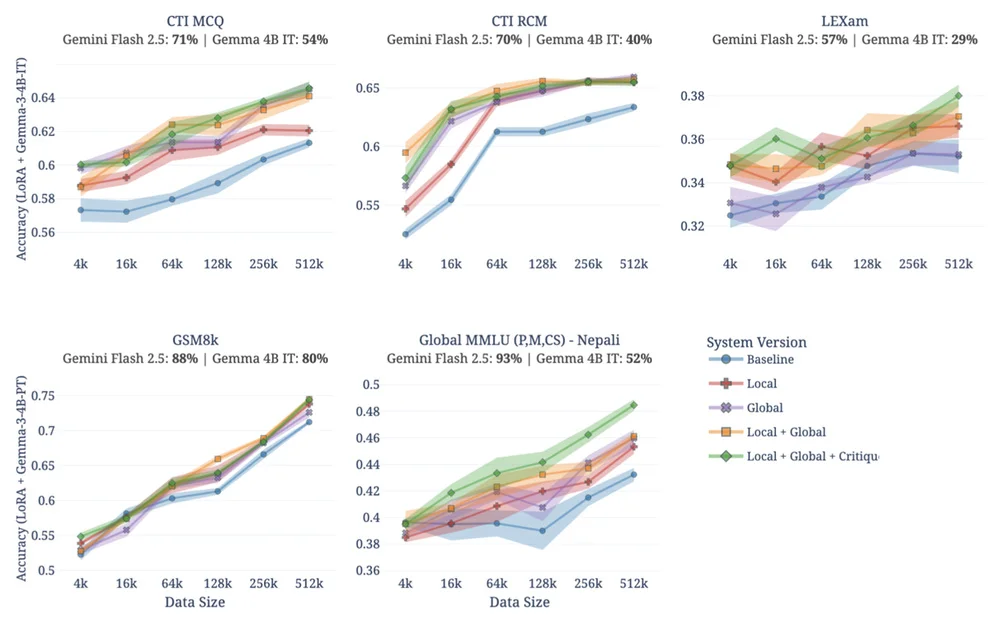
이 논문은 실제 데이터가 부족하거나 접근하기 어려운 상황에서 필수적인 합성 데이터를 생성하여 전문 AI 모델을 만드는 과제를 다룹니다. 제안된 프레임워크인 Simula는 합성 데이터 생성을 제어를 우선시하는 메커니즘 설계 문제로 재구성합니다. Simula의 "추론 우선" 접근 방식은 기본 원리부터 데이터셋을 구축하여 계층적 분류 체계를 통해 전역적 다양성을 보장합니다. 메타 프롬프트를 사용하는 지역적 다양성은 개념 내의 다양성을 보장하고 모드 붕괴를 방지합니다. 이 프레임워크는 난이도를 조정하기 위한 복잡화와 정확성을 확인하기 위한 품질 검사도 통합합니다. Simula 시스템은 사이버 보안 및 법률 추론과 같은 다양한 도메인에 걸친 실험에서 단순한 기준선보다 일관되게 뛰어난 성능을 보입니다. 평가는 분류 체계 적용 범위 및 보정된 복잡성 점수와 같은 추론 기반 메트릭을 사용합니다. 연구 결과는 데이터가 모델의 기능에 맞춰져야 하며, 데이터 품질이 단순한 양보다 더 중요함을 강조합니다. Simula는 Google의 데이터 엔진 역할을 하여 전문 모델 및 사용자 보호 기능을 지원합니다. 또한 Simula는 현실적인 공격 시나리오를 합성하고 AI에게 지도를 읽도록 가르치는 연구를 가능하게 합니다. 합성 데이터는 미래 AI 발전에 매우 중요하며, Simula는 데이터 생성 제어의 잠재력을 보여줍니다.