RSS 구글 AI 블로그
팔로우
회귀 언어 모델을 이용한 대규모 시스템 시뮬레이션
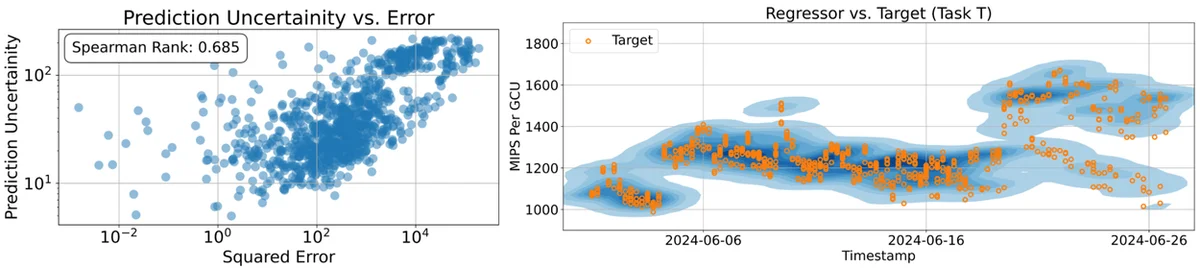
대규모 언어 모델(LLM)은 인간의 선호도에서 학습하여 유용한 텍스트를 생성함으로써 향상됩니다. 한 가지 새로운 접근 방식은 운영 데이터를 사용하여 성능 지표를 예측하는 보상 모델을 훈련하는 것입니다. 기존 회귀는 복잡하고 구조화되지 않은 데이터에 어려움을 겪으며, 많은 특징 공학이 필요합니다. 본 논문은 텍스트-텍스트 회귀를 수행하는 회귀 언어 모델(RLM)을 소개합니다. 이는 텍스트 입력을 직접 처리하여 숫자 예측을 문자열로 출력합니다. 이 방법은 특징 공학을 피하고 새로운 작업에 대한 소량 학습 적응을 가능하게 합니다. RLM은 결과의 확률 분포를 포착하고 예측 불확실성을 정량화할 수 있습니다. 이 접근 방식은 Google의 대규모 컴퓨팅 인프라인 Borg에서 리소스 효율성을 예측하는 데 적용되었습니다. RLM은 Google Compute Unit당 백만 건의 명령(MIPS per GCU)을 효과적으로 예측했습니다. 이 새로운 패러다임은 원시 텍스트에서 숫자 결과를 예측하는 확장 가능하고 효율적인 방법을 제공하여 보편적인 시스템 시뮬레이터와 고급 보상 메커니즘을 가능하게 합니다.