RSS 구글 AI 블로그
팔로우
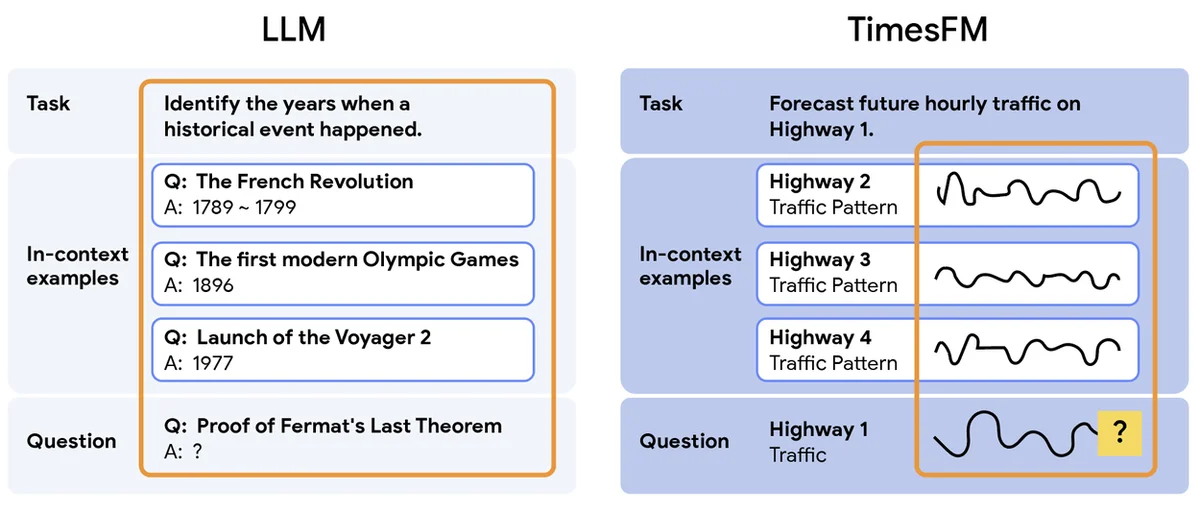
시계열 기반 모델은 소수샷 학습이 가능하다
"시계열 예측은 비즈니스에 매우 중요하지만, 기존 방법은 느리고 전문가의 많은 노력이 필요합니다. 제로샷 파운데이션 모델인 TimesFM은 작업별 학습 없이 예측을 개선했습니다. 그러나 몇 가지 예시를 통합하는 소수샷 학습(few-shot learning)은 정확도를 더욱 향상시킬 수 있습니다. 이를 위한 표준 방법인 지도 미세 조정(supervised fine-tuning)은 복잡성을 다시 도입합니다.새로운 인컨텍스트 미세 조정(In-Context Fine-Tuning, ICF) 접근 방식은 지속적인 사전 학습을 사용하여 TimesFM을 소수샷 학습자로 변환합니다. 이를 통해 모델은 추가 사용자 학습 없이 추론 시점의 예시로부터 학습할 수 있습니다. 이제 TimesFM-ICF가 된 모델은 트랜스포머 레이어가 있는 패치 디코더 아키텍처를 사용합니다.소수샷 학습을 가능하게 하기 위해 예측 기록과 인컨텍스트 예시를 구분하는 "공통 구분 토큰"이 도입됩니다. 이는 데이터 혼동을 방지하고 모델이 과거 패턴으로부터 학습할 수 있도록 합니다. 그런 다음 모델은 이러한 구분 토큰을 통합한 새로운 데이터셋으로 사전 학습됩니다.TimesFM-ICF는 관련 과거 데이터를 인컨텍스트 예시로 사용하여 보지 못한 데이터셋에서 평가되었습니다. 기본 TimesFM보다 6.8%의 정확도 향상을 보였습니다. 중요한 것은 TimesFM-ICF가 추가적인 복잡한 학습 없이 지도 미세 조정과 동일한 성능을 달성한다는 것입니다.이 시스템은 또한 더 많은 인컨텍스트 예시가 더 나은 예측으로 이어진다는 것을 보여주지만, 추론 시간과의 절충이 있습니다. 이 혁신은 더 접근 가능하고 강력한 예측을 약속하며, 비즈니스가 광범위한 ML 프로젝트 없이도 적응 가능한 모델을 배포할 수 있도록 합니다. 향후 연구는 가장 관련성 높은 인컨텍스트 예시의 선택을 자동화하는 것을 목표로 합니다."