RSS 구글 AI 블로그
팔로우
고품질 레이블을 사용하여 훈련 데이터 10,000배 절감
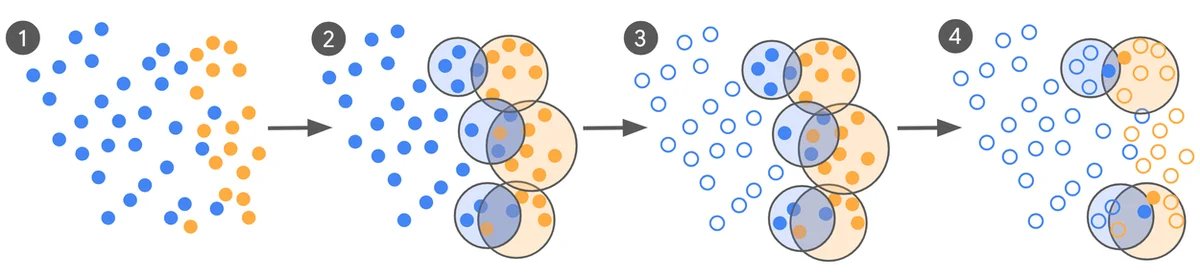
안전하지 않은 광고 콘텐츠를 분류하는 것은 맥락적 이해 능력 덕분에 대규모 언어 모델(LLM)이 잘 수행할 수 있는 복잡한 작업입니다. 그러나 이러한 작업을 위해 LLM을 미세 조정하려면 고품질의 대규모 학습 데이터가 필요한데, 이를 큐레이션하는 데는 비용과 시간이 많이 소요됩니다. 안전 정책이 변경되는 개념 드리프트는 빈번한 재학습을 필요로 하여 비용을 증가시킵니다. 이를 해결하기 위해 새로운 능동 학습 큐레이션 프로세스는 모델이 인간 전문가와 더 잘 일치하도록 개선하면서 필요한 학습 데이터의 양을 극적으로 줄입니다. 이 프로세스는 주석에 가장 가치 있는 예제를 식별하여 데이터 요구 사항을 크게 줄입니다. 실험 결과, 학습 데이터가 100,000개에서 500개 미만으로 줄었고, 모델 일치는 최대 65% 향상되었습니다. 큐레이션 프로세스는 제로샷 LLM이 데이터를 레이블링하는 것으로 시작하여, 혼동될 수 있는 예제를 식별하기 위해 클러스터링합니다. 그런 다음 이러한 유익하고 다양한 예제가 레이블링을 위해 인간 전문가에게 전송됩니다. 전문가 레이블은 모델을 반복적으로 평가하고 미세 조정하는 데 모두 사용됩니다. 이 프로세스는 실제 레이블이 종종 모호하기 때문에 일치를 측정하기 위해 코헨의 카파에 의존합니다. 대규모 크라우드소싱 데이터셋으로 미세 조정된 기본 모델은 큐레이션된 모델에 비해 성능이 떨어졌습니다. 새로운 방법은 적고 더 유익한 예제를 신중하게 큐레이션하면 훨씬 적은 데이터로 상당한 성능 향상을 가져올 수 있음을 보여줍니다. 이 접근 방식은 빠르게 진화하는 콘텐츠가 있는 광고 안전과 같은 분야에 특히 유익합니다.