대규모 언어 모델을 사용한 Pinterest 검색 관련성 향상
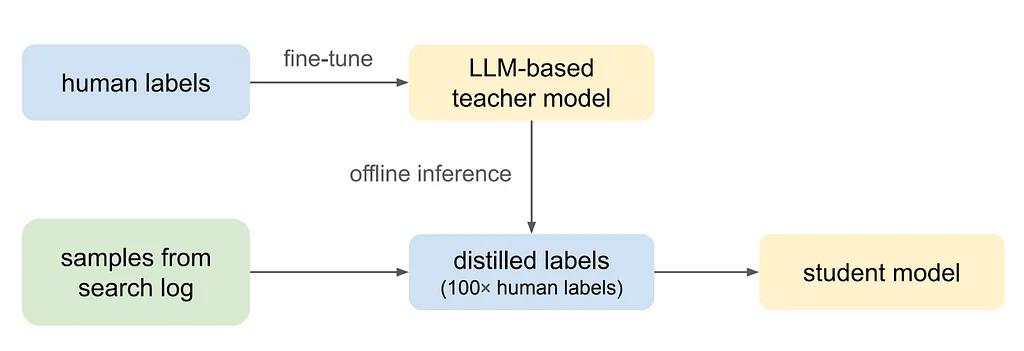
Pinterest 검색은 사용자들이 정보 니즈에 맞는 영감을 주는 콘텐츠를 발견하는 주요 경로이며, 검색 관련성은 검색 결과가 검색어와 얼마나 잘 일치하는지를 측정합니다. 검색 관련성 모델을 개선하기 위해, 쿼리와 핀의 관련성을 측정하는 5단계 가이드라인이 사용됩니다. 핀의 텍스트와 함께 핀의 쿼리 관련성을 예측하기 위해 크로스 인코더 언어 모델이 사용되며, 이 작업은 다중 클래스 분류 문제로 공식화됩니다. 모델은 사람이 주석을 단 데이터를 사용하여 미세 조정되며, 교차 엔트로피 손실을 최소화합니다.각 핀을 나타내기 위해 핀 제목 및 설명, 합성 이미지 캡션, 높은 참여도를 보이는 쿼리 토큰, 사용자가 관리하는 보드 제목, 링크 제목 및 설명을 포함한 다양한 텍스트 기능 집합이 사용됩니다. 그러나 실시간 지연 시간 및 비용 문제로 인해 크로스 인코더 LLM 기반 분류기는 Pinterest 검색에 확장하기 어렵습니다. 따라서 지식 증류를 사용하여 LLM 기반 교사 모델을 경량 학생 관련성 모델로 증류합니다.학생 모델은 5단계 관련성 점수를 예측하기 위해 쿼리 수준 기능, 핀 수준 기능 및 쿼리-핀 상호 작용 기능을 사용합니다. 지식 증류 및 준지도 학습을 사용하여 학생 모델을 훈련하며, 이를 통해 방대한 양의 초기 비표지 데이터를 효과적으로 활용하고 전 세계 다양한 언어로 데이터를 확장합니다.오프라인 실험은 언어 모델 비교, 텍스트 기능 풍부화의 중요성, 증류를 통한 훈련 레이블 확장 등 각 모델링 결정의 효과를 보여줍니다. 온라인 결과는 nDCG@20으로 측정했을 때 검색 피드 관련성이 +2.18% 향상되었고, 전 세계적으로 검색 만족도가 크게 증가했음을 보여줍니다.제안된 관련성 모델링 파이프라인은 훈련 중에 접하지 못한 언어에서도 효과적으로 일반화되며, 다국어 LLM 기반 관련성 교사 모델은 보이지 않는 언어에서도 일반화됩니다. 향후 작업은 서비스 가능한 LLM, 비전 및 언어 다중 모달 모델, 적극적 학습 전략을 통합하여 훈련 데이터의 규모를 동적으로 확장하고 품질을 개선하는 것을 목표로 합니다.