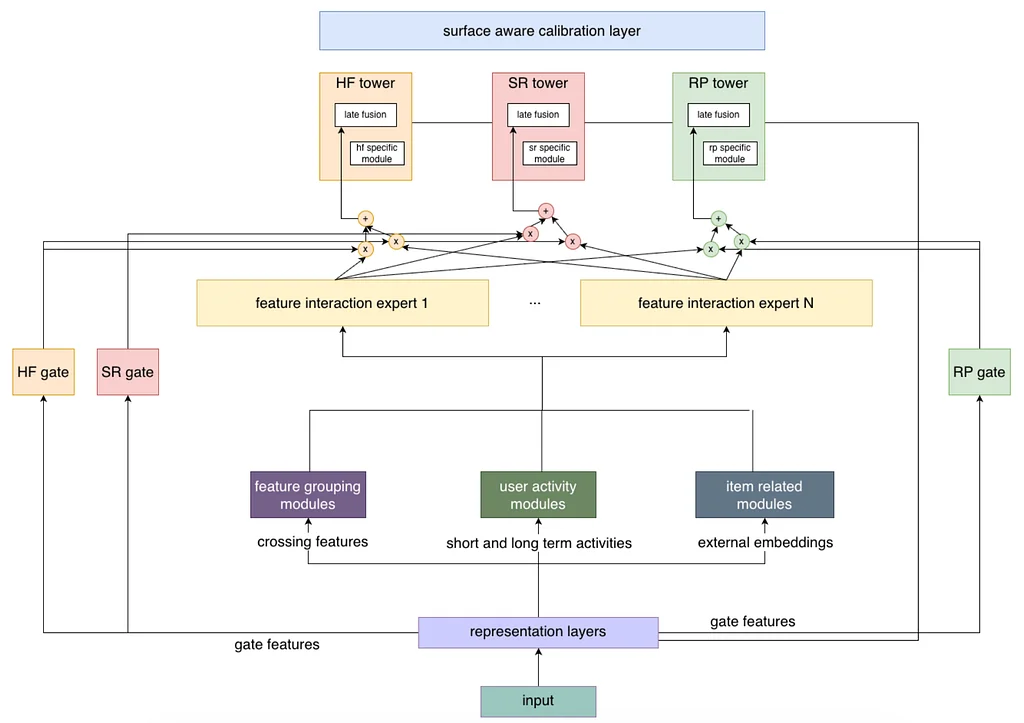
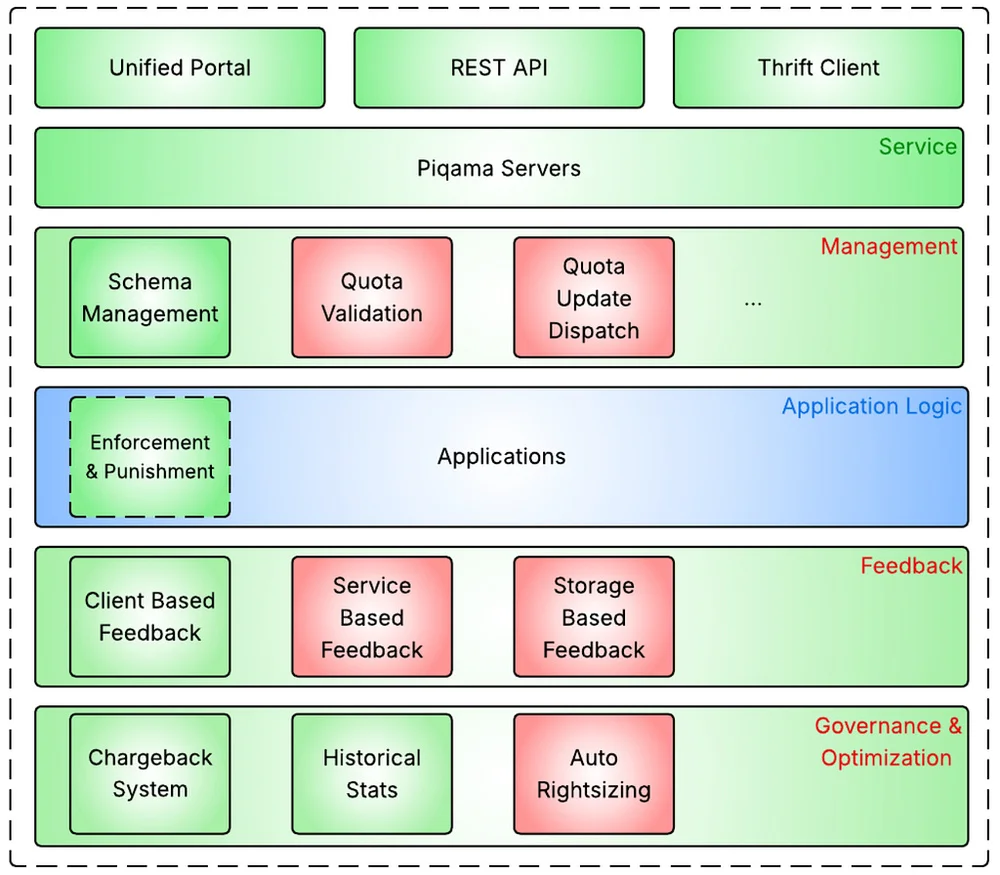
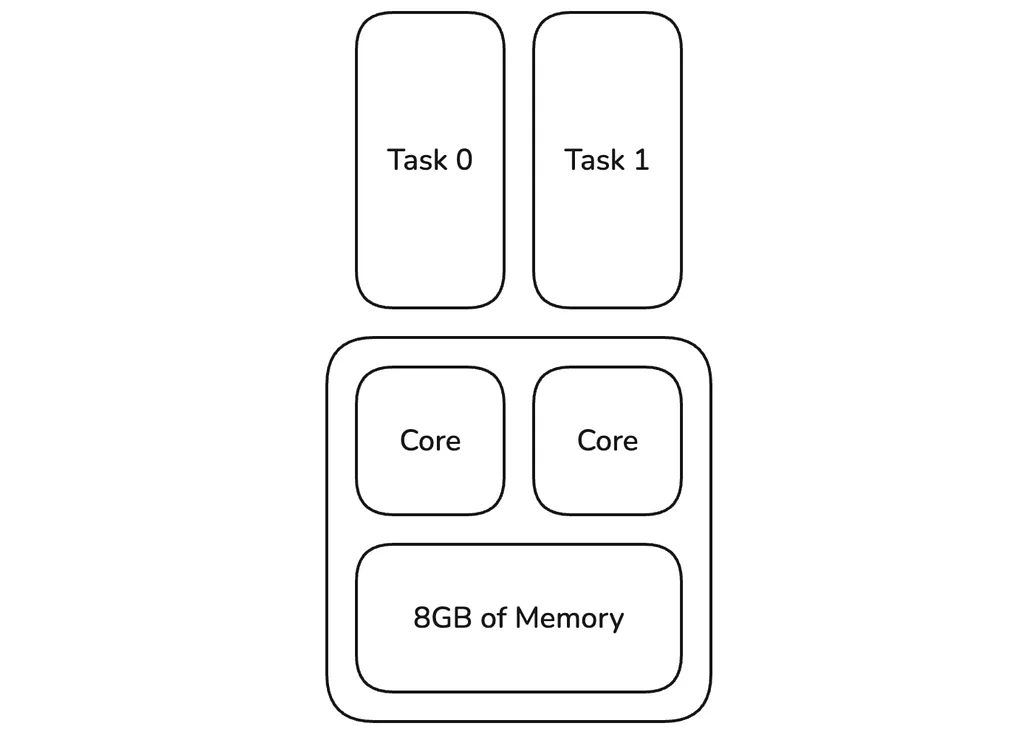
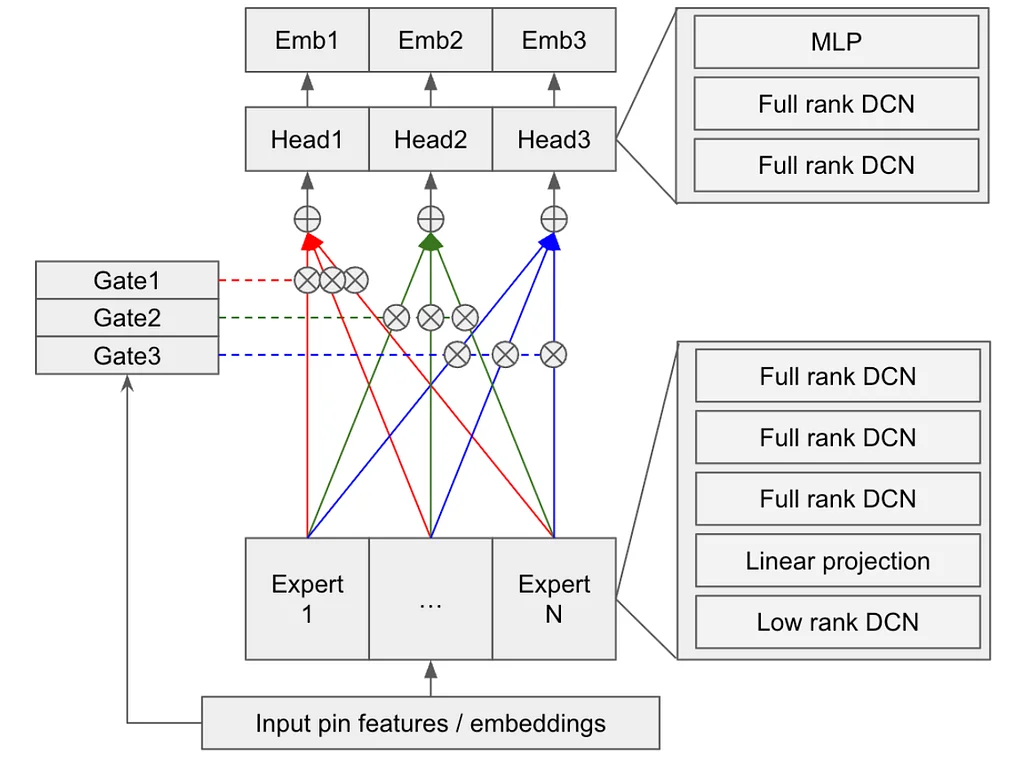
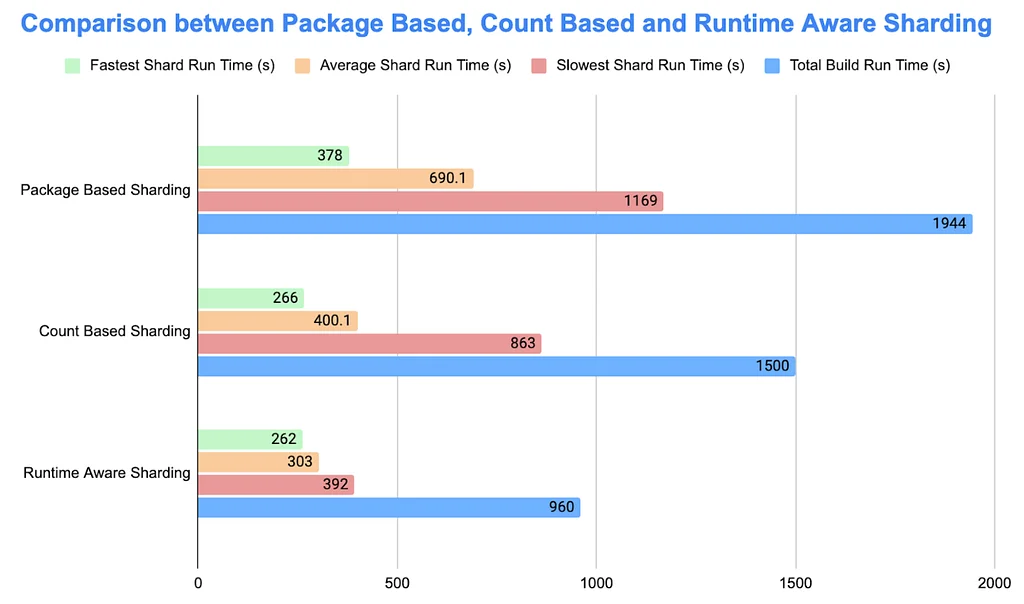
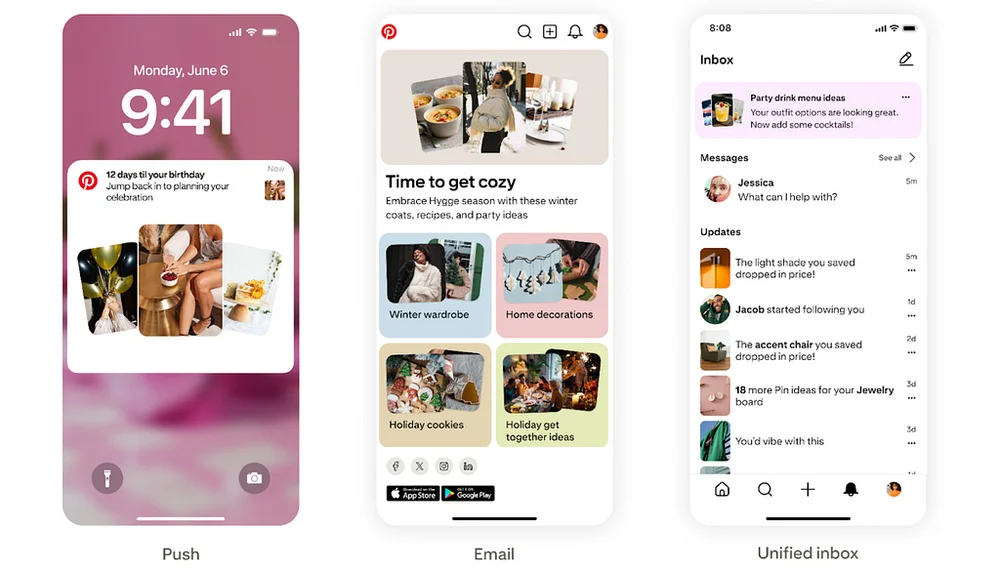
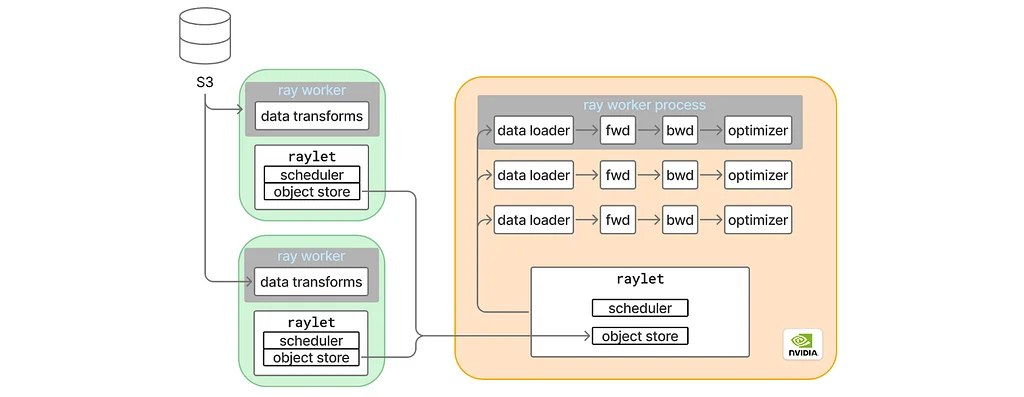
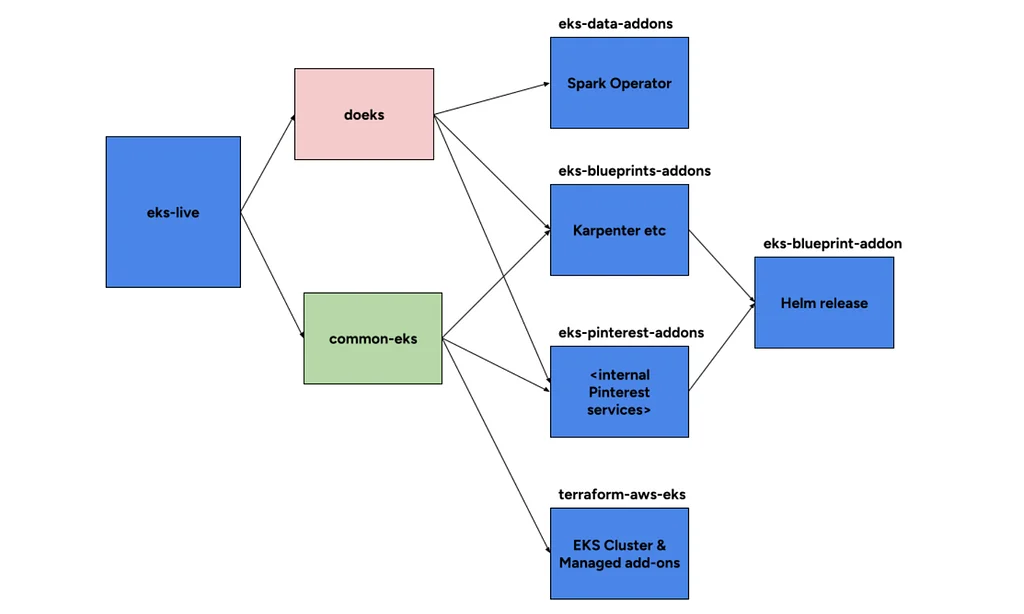
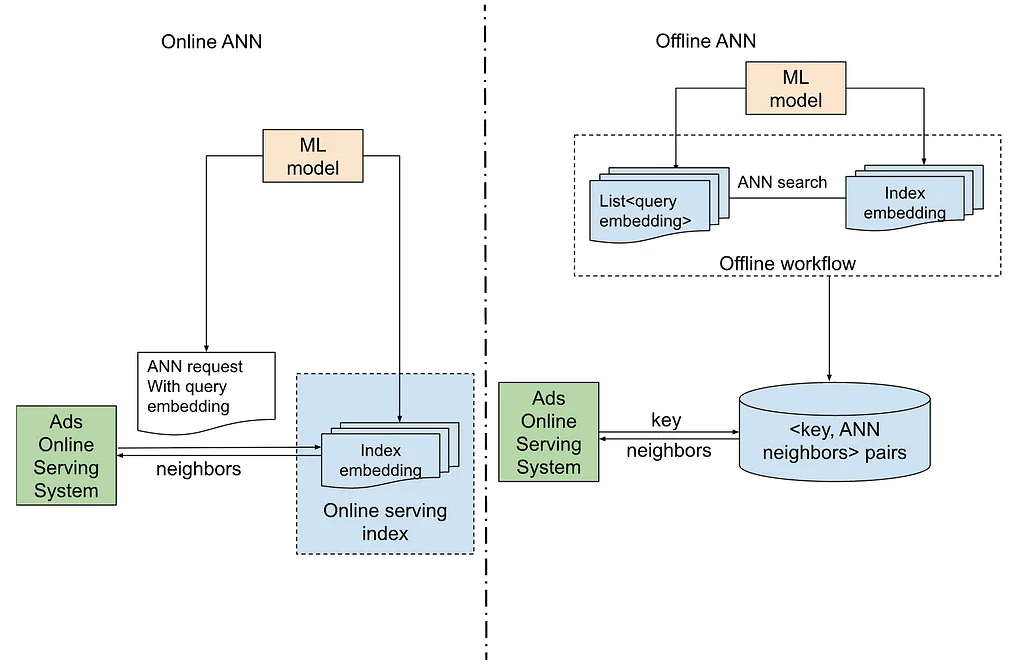
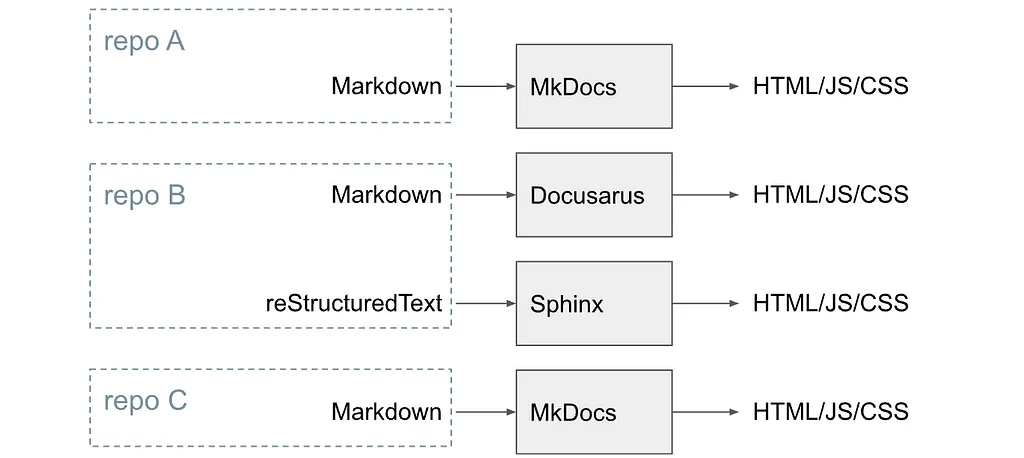
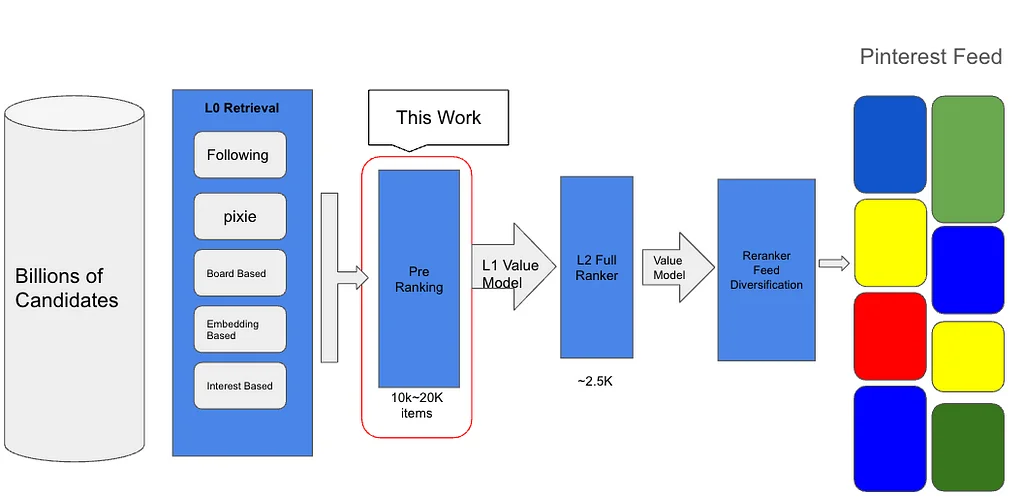
미디엄의 Pinterest 엔지니어링 팀의 RSS 스토리 팔로우
미디어(Medium)에서 공개된 'Pinterest 엔지니어링(Pinterest Engineering)'은 인기 있는 시각적 검색 플랫폼을 구동하는 기술 혁신에 대한 내부적인 모습을 보여준다. 엔지니어들은 확장성, 기계 학습, 데이터 인프라스트럭처 등에 대한 자신의 작업에 대한 깊은 통찰력을 공유한다. 이 출판물은 협업, 실험, 복잡한 문제 해결에 대한 열정을 강조하는 핀터레스트의 엔지니어링 문화를 강조한다. 독자는 추천 시스템 구축, 검색 기능 최적화, 데이터 분석을 위한 도구 개발 등 다양한 주제를 탐색할 수 있다. 이 콘텐츠는 핀터레스트와 같은 대규모 플랫폼의 세부 사항에 관심 있는 엔지니어와 기술 애호가들에게 귀중한 통찰력을 제공한다. 이미지 인식의 도전이나 인프라의 진화에 깊이 있게 탐구하는 것과 같은 주제를 다루는 동안, 미디어의 Pinterest 엔지니어링은 사랑받는 온라인 목적지의 기술적인 측면에 대한 매혹적인 모습을 제공한다.