ML 워크로드 네트워크 효율 최적화 (1부): Feature Trimmer
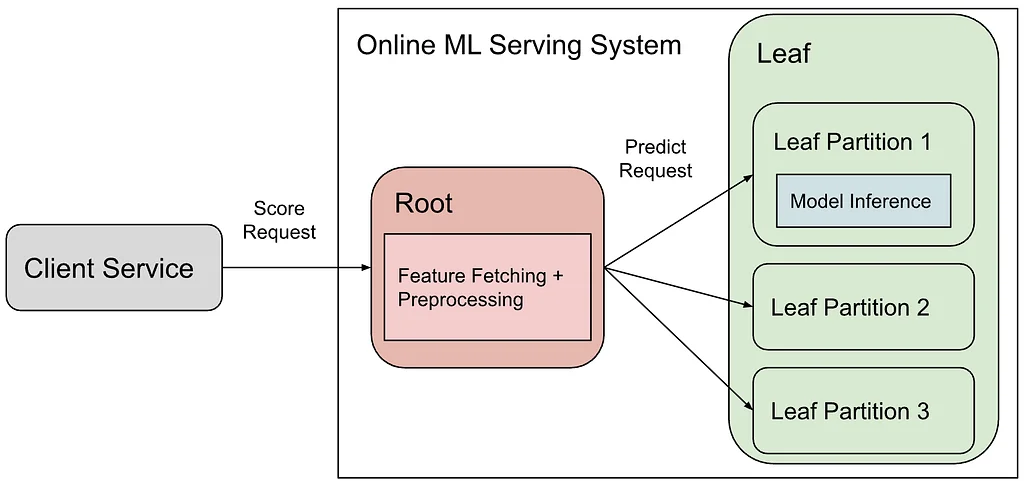
Pinterest의 온라인 ML 서빙 시스템은 클라이언트 서비스가 Pin에 대한 점수를 요청하는 루트-리프 아키텍처를 사용합니다. 루트 컴포넌트는 피처 검색 및 전처리를 담당하고, 리프는 종종 GPU에서 모델 추론을 수행합니다. 이 설계는 새로운 모델의 온보딩을 단순화하고 CPU 및 GPU 워크로드를 분리하여 리소스 활용을 최적화합니다. 그러나 많은 피처를 전달함으로 인해 루트와 리프 파티션 간의 네트워크 병목 현상이 발생했습니다.초기에는 lz4 압축을 구현하여 네트워크 사용량을 줄였고, 상당한 대역폭 절감 효과를 얻었지만 CPU 사용량과 지연 시간이 약간 증가했습니다. 이는 좋은 시작이었지만, 불필요한 피처를 전달하는 근본적인 문제는 지속되었습니다. "Send What You Use" 접근 방식은 특정 모델이 요구하는 피처만 보내도록 하여 이 문제를 해결하기 위해 개발되었습니다.모델의 입력과 출력을 정의하는 모델 시그니처는 피처 요구 사항의 진실 공급원 역할을 합니다. 모델이 훈련되고 내보내질 때, 해당 시그니처는 모델과 함께 저장됩니다. Leaften은 이러한 시그니처를 로드하여 필요한 피처만 처리하는 피처 컨버터를 구축합니다.루트와 리프 간의 피처 요구 사항을 동기화하기 위해 모델 시그니처는 경량 아티팩트로 게시됩니다. 이러한 시그니처는 번들 수준 매핑으로 집계된 다음, 기존 구성과 함께 루트에 배포됩니다. 이 배포는 모델 롤아웃과 동일한 단계적 전달 프로세스를 따르며, 일관성을 보장하고 점진적인 롤백을 가능하게 합니다.이러한 통합을 통해 Feature Trimmer는 루트의 피처 허용 목록을 동적으로 업데이트하여 필수 피처만 전송되도록 합니다. 시스템은 버전화된 조회 및 폴백 메커니즘을 사용하여 빈번한 모델 업데이트와 점진적인 롤아웃을 처리하도록 설계되었습니다. 이를 통해 루트의 피처 요구 사항에 대한 뷰는 리프에 배포된 실제 모델과 동기화된 상태를 유지합니다. 불필요한 피처를 트리밍함으로써 Pinterest는 네트워크 트래픽을 크게 줄이고 인프라 효율성을 향상시켰습니다.