Pinterest의 파운데이션 모델을 위한 거의 선형적인 학습 확장성 달성
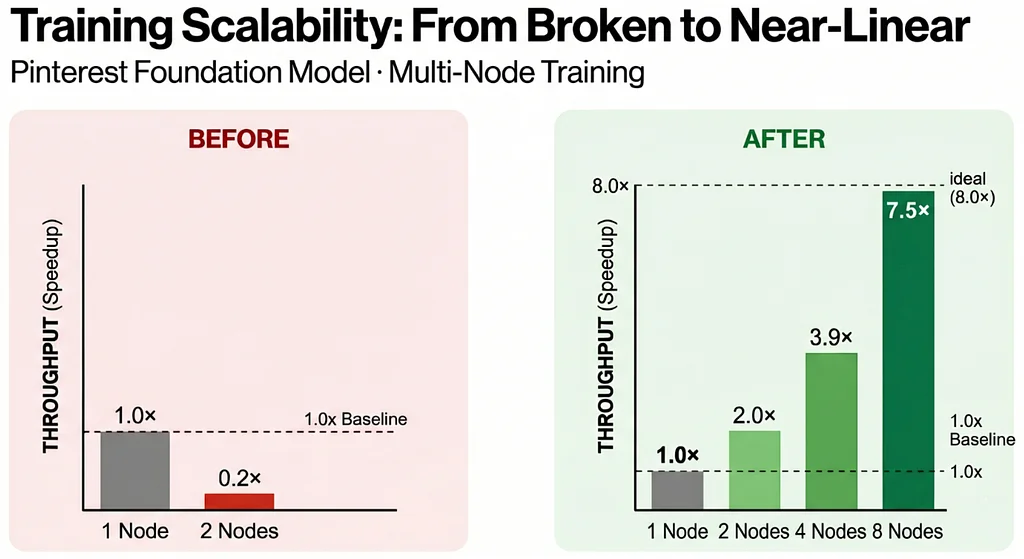
Pinterest의 기반 모델은 수백만 명의 사용자에게 매일 영향을 미치는 추천 시스템에 매우 중요합니다. 초기에는 이러한 대규모 모델의 멀티 노드 학습 성능이 저조했으며, 머신을 추가할수록 프로세스가 현저히 느려졌습니다. 네트워킹 개선을 위해 AWS Elastic Fabric Adapter(EFA)를 사용했음에도 불구하고 확장성은 비효율적이었습니다. 프로파일링 결과, 분산 임베딩 조회(distributed embedding lookups)가 상당한 통신 병목 현상을 유발했으며, GPU는 데이터 대기를 해야 했습니다. 팀은 이러한 통신 오버헤드를 해결하기 위해 여러 최적화를 구현했습니다. 양자화 통신(Quantized Communications, QComms)은 임베딩 텐서를 압축하여 데이터 페이로드를 줄였습니다. 균형 잡힌 샤딩(Balanced sharding)은 GPU 간 워크로드 분산을 개선했습니다. 대역폭 인식 임베딩 최적화(Bandwidth-aware embedding optimization)는 임베딩 차원을 절반으로 줄여 데이터 이동을 감소시켰습니다. 주요 돌파구는 2D 병렬 처리(2D Parallelism)를 구현한 것으로, 초기에는 AllReduce를 최적화하여 로컬 통신을 개선했습니다. 마지막으로, 2D 병렬 처리 토폴로지를 뒤집어 All-to-All을 최적화하여 노드 내에서 비싼 연산을 유지하고 저렴한 AllReduce를 노드 간 동기화에 사용했습니다. 이는 거의 선형적인 확장을 가능하게 하여 2개 노드에서 2.0배, 4개 노드에서 3.9배, 8개 노드에서 인상적인 7.5배의 확장을 달성했습니다. 이러한 발전은 더 큰 모델을 학습할 수 있게 하여 Pinterest 추천 표면에서의 사용자 참여도 향상과 더 빠른 실험 주기를 가져왔습니다.