Pinterest의 ML 훈련 플랫폼인 MLEnv는 PyTorch 버전 업그레이드 후 상당한 성능 저하를 겪었습니다. 이 문제는 훈련 처리량을 50% 이상 감소시켰습니다. 디버깅 과정은 GPU roofline 처리량 검사로 시작되었습니다. 이 측정 결과, 데이터 로더를 제외하더라도 20%의 성능 저하가 나타났습니다. 추가 분석은 성능 저하의 원인을 파악하기 위해 개별 모델 모듈에 초점을 맞췄습니다. 특정 변환기 모듈인 모듈 A가 주요 원인으로 확인되었습니다. PyTorch 프로파일러는 이 모듈에 대해 이전에 존재했던 CompiledFunctions가 업그레이드된 버전에서는 누락되었음을 보여주었습니다.torch.compile에 대한 조사 결과, torch.compile이 지원하지 않는 비 인프라 PyTorch 디스패치 모드가 존재한다는 로그가 나타났습니다. 최소 재현 가능한 스크립트는 이 문제가 특히 트레이너 클래스 내에서 나타난다는 것을 확인했습니다. 문제의 구성 요소는 기본적으로 활성화된 FLOPs 계산에 사용되는 컨텍스트 관리자로 확인되었습니다. 이 컨텍스트 관리자를 비활성화하면 torch.compile 문제가 해결되어 CompiledFunctions가 복원되었습니다. 그러나 이 수정 사항은 엔드 투 엔드 처리량을 개선하지 못했습니다.초점은 데이터 로딩 및 분산 훈련 측면으로 다시 옮겨졌으며, 네이티브 PyTorch 애플리케이션으로 실행할 때에도 동일한 GPU roofline 처리량 문제가 관찰되어 Ray.data가 원인이 아님을 배제했습니다. 여러 관찰 결과는 간헐적인 느린 반복, 동기화 중의 straggler 효과, 그리고 Nvidia의 Nsight Systems 프로파일러를 활성화하면 느림이 사라지는 특이한 동작을 지적했습니다. 단일 GPU에서 테스트한 결과, 분산 훈련이 근본 원인이 아님을 확인했습니다. Ray 설정에서 torch.compile을 완전히 비활성화하면 원래의 처리량이 복원되었으며, 이는 torch.compile 내의 그래프 중단이 성능 저하와 관련이 있음을 시사했습니다.광범위한 그래프 중단을 포함하는 최소 재현 가능한 모델을 생성한 결과, 반복적인 느린 반복이 관찰되었습니다. Nsight Systems 추적 결과, 주요 훈련 스레드가 이러한 느린 반복 동안 GIL(Global Interpreter Lock)을 유지하고 있었지만, 이것이 전체 일시 중지를 설명하지는 못했습니다. Linux perf 도구를 사용하고 chrome://tracing으로 추적을 시각화한 추가 분석 결과, 의심스러운 Python 프로세스가 강조되었습니다. 이 프로세스는 smap_gather_stats라는 Linux 커널 호출, 즉 가상 메모리 통계를 수집하는 비용이 많이 드는 계산을 실행하고 있었습니다.
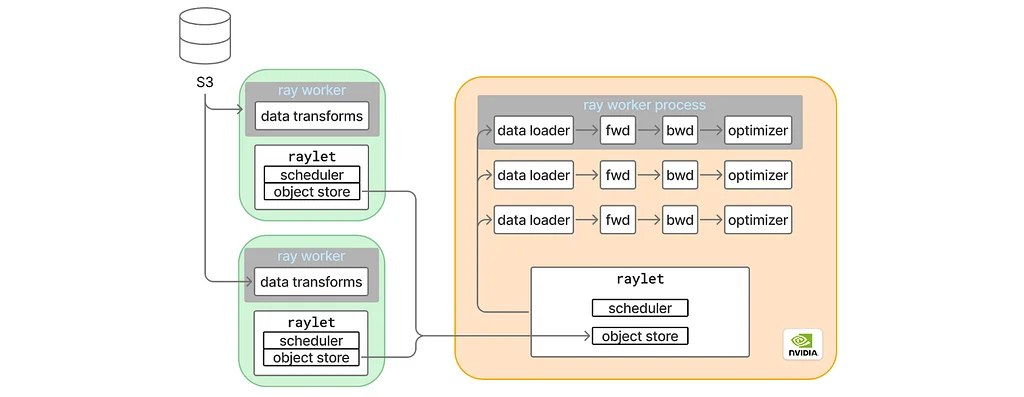
torch.compile에 대한 조사 결과,torch.compile이 지원하지 않는 비 인프라 PyTorch 디스패치 모드가 존재한다는 로그가 나타났습니다. 최소 재현 가능한 스크립트는 이 문제가 특히 트레이너 클래스 내에서 나타난다는 것을 확인했습니다. 문제의 구성 요소는 기본적으로 활성화된 FLOPs 계산에 사용되는 컨텍스트 관리자로 확인되었습니다. 이 컨텍스트 관리자를 비활성화하면torch.compile문제가 해결되어 CompiledFunctions가 복원되었습니다. 그러나 이 수정 사항은 엔드 투 엔드 처리량을 개선하지 못했습니다.초점은 데이터 로딩 및 분산 훈련 측면으로 다시 옮겨졌으며, 네이티브 PyTorch 애플리케이션으로 실행할 때에도 동일한 GPU roofline 처리량 문제가 관찰되어 Ray.data가 원인이 아님을 배제했습니다. 여러 관찰 결과는 간헐적인 느린 반복, 동기화 중의 straggler 효과, 그리고 Nvidia의 Nsight Systems 프로파일러를 활성화하면 느림이 사라지는 특이한 동작을 지적했습니다. 단일 GPU에서 테스트한 결과, 분산 훈련이 근본 원인이 아님을 확인했습니다. Ray 설정에서torch.compile을 완전히 비활성화하면 원래의 처리량이 복원되었으며, 이는torch.compile내의 그래프 중단이 성능 저하와 관련이 있음을 시사했습니다.광범위한 그래프 중단을 포함하는 최소 재현 가능한 모델을 생성한 결과, 반복적인 느린 반복이 관찰되었습니다. Nsight Systems 추적 결과, 주요 훈련 스레드가 이러한 느린 반복 동안 GIL(Global Interpreter Lock)을 유지하고 있었지만, 이것이 전체 일시 중지를 설명하지는 못했습니다. Linuxperf도구를 사용하고chrome://tracing으로 추적을 시각화한 추가 분석 결과, 의심스러운 Python 프로세스가 강조되었습니다. 이 프로세스는smap_gather_stats라는 Linux 커널 호출, 즉 가상 메모리 통계를 수집하는 비용이 많이 드는 계산을 실행하고 있었습니다.