Pinterest에서의 차세대 대규모 데이터 처리: Moka (2부작 중 1부)
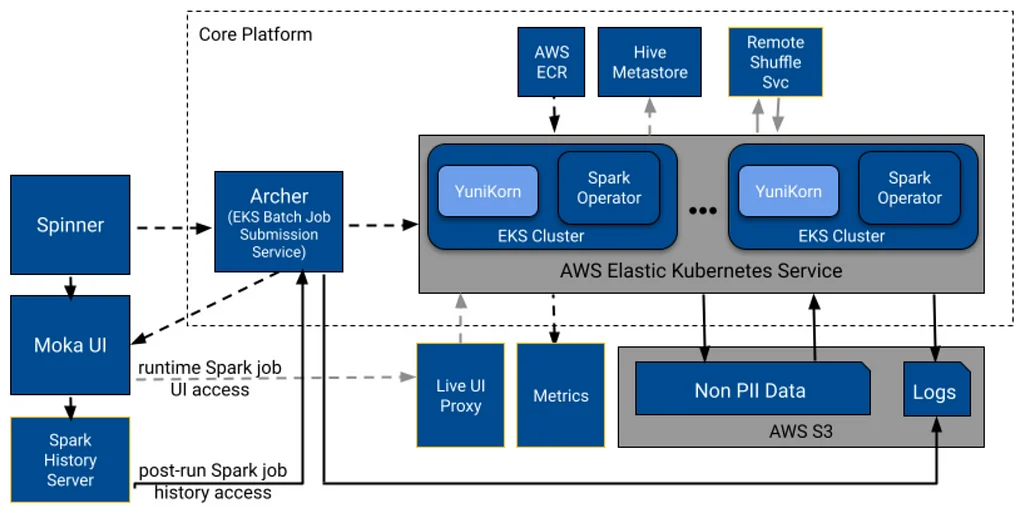
핀터레스트의 데이터 엔지니어링 팀은 현재 사용 중인 하둡 기반 플랫폼인 모나크(Monarch)를 대체하기 위해 대규모 데이터 처리 플랫폼을 구축 중이다. 팀은 빅데이터 커뮤니티에서 점점 더 많이 사용되고 채택되는 쿠버네티스 기반 시스템을 대체 플랫폼으로 탐색했다. 새로운 플랫폼은 컨테이너에 대한 광범위한 지원, 핀터레스트의 커스텀 스파크 포크의 실행, 운영 및 유지 보수 비용의 감소와 같은 특정 기준을 충족해야 했다. 팀은 다양한 플랫폼에서 스파크를 실행하는 것을 포함한 종합적인 평가를 수행했으며, 컨테이너 기반의 격리 및 보안, 배포의 용이성, 내장된 프레임워크와 같은 장점으로 인해 쿠버네티스 기반 프레임워크를 선호했다. 쿠버네티스는 다른 시스템보다 컨테이너 관리 및 배포에 대한 더 세부적인 지원을 제공하지만, 데이터 관리, 저장소 및 처리에 대한 내장된 지원은 부족하다. 팀의 현재 배포 모델은 하둡에서 번거롭기 때문에, 팀은 테라폼, 컨테이너 이미지 및 헬름을 사용하여 더 직접적인 접근 방식을 사용하고 있다. 새로운 플랫폼은 모나크를 대체하기 위해 쿠버네티스와 EKS를 사용할 것이며, 이는 EKS를 기존 핀터레스트 환경에 통합하고 하둡 구성 요소를 대체하는 것과 같은 여러 가지 도전을 가져올 것이다. 팀은 배치 스파크 워크로드를 처리할 수 있는 새로운 플랫폼인 모카(Moka)를 구축했으며, 향후에는 더 많은 기능을 추가할 계획이다. 모카의 초기 고급 설계에는 일련의 구성 요소인 스핀너(Spinner), 아처(Archer) 및 스파크 연산자를 통해 작업이 제출되고 처리되는 배치 스파크 워크로드를 처리할 수 있는 시스템이 포함된다. 팀은 블로그 시리즈의 다음 부분에서 플랫폼의 핵심 애플리케이션 중심 측면에 대한 자세한 정보를 제공할 예정이다.