Pinterest의 ML 인프라를 Ray로 확장하기: 학습부터 엔드투엔드 ML 파이프라인까지
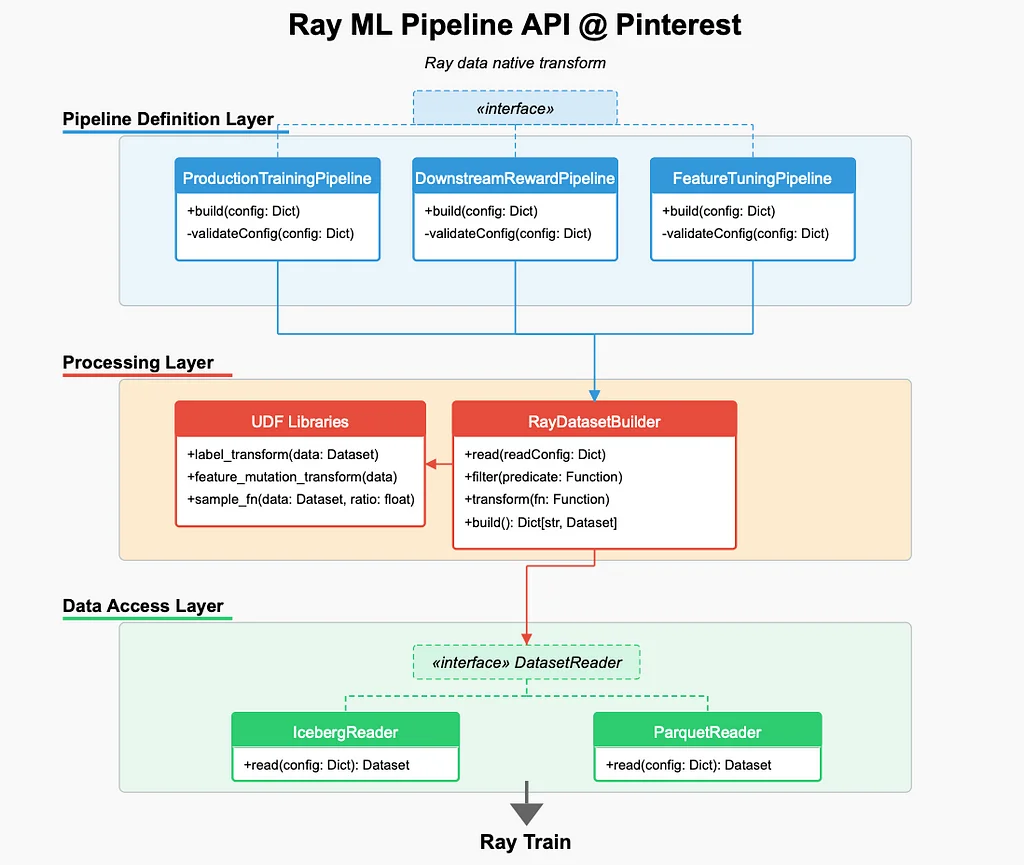
Pinterest에서 ML 엔지니어들은 느린 데이터 파이프라인, 비용이 많이 드는 기능 반복, 비효율적인 컴퓨팅 사용으로 인해 기능 개발 최적화, 샘플링 전략, 라벨 실험에 어려움을 겪고 있습니다. 이러한 문제를 해결하기 위해 Pinterest는 Ray의 기능을 훈련 외에도 기능 개발, 샘플링, 라벨 모델링까지 확장했습니다. 기존 ML 인프라는 느린 데이터 파이프라인, 비용이 많이 드는 기능 반복, 비효율적인 컴퓨팅 사용에 의해 제약을 받았습니다. Pinterest는 Ray-네이티브 ML 인프라 스택을 도입하여 다음과 같은 네 가지 주요 개선 사항에 중점을 두었습니다: Ray Data 네이티브 파이프라인 API 구축, Iceberg Bucket Join을 이용한 효율적인 데이터 조인, 효율적인 반복을 위한 데이터 지속성, 대규모 워크로드를 위한 Ray Data 최적화. 새로운 Ray 기반 ML 워크플로우는 ML 반복 시간을 10배 줄이는 동시에 인프라 비용을 크게 절감합니다. Ray Data 네이티브 파이프라인 API는 Ray에서 기능 개발, 샘플링, 라벨 변환을 네이티브하게 수행하여 Spark 백필의 필요성을 없앴습니다. Iceberg Bucket Join은 대규모 테이블을 미리 계산하지 않고도 서로 다른 소스 간의 빠르고 효율적인 기능 조인을 가능하게 합니다. 데이터 지속성은 변환된 기능을 캐싱하고 해당 기능을 재사용하여 효율적인 반복을 가능하게 합니다. Ray Data 최적화는 다양한 파이프라인에서 2-3배의 속도 향상을 달성했으며, 새로운 워크플로우는 Pinterest에서 더욱 확장 가능하고 효율적이며 비용 효율적인 ML 인프라를 구축했습니다.