RSS 구글 AI 블로그
팔로우
검색 증강 생성(Retrieval Augmented Generation)에 대한 심층적인 이해: 충분한 컨텍스트의 역할
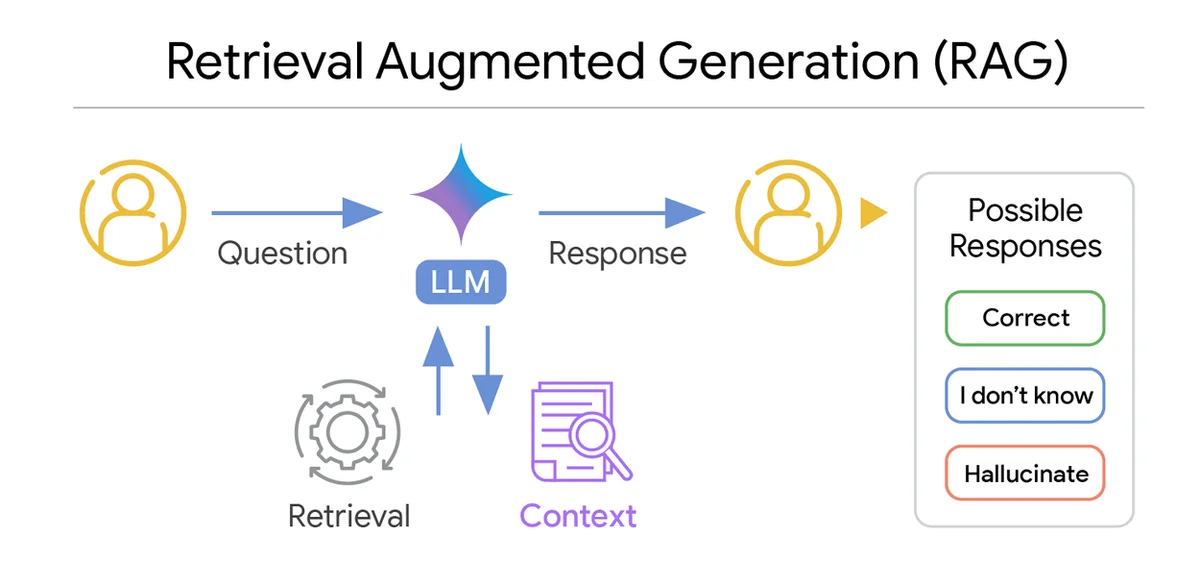
검색 증강 생성(RAG) 시스템은 관련 외부 정보를 제공하여 대규모 언어 모델(LLM)을 향상시킵니다. 이상적으로 LLM은 특정 핵심 정보가 부족할 때 올바른 답변을 생성하거나 "모르겠습니다"라고 응답합니다. RAG 시스템의 주요 과제는 환각(따라서 부정확한) 정보로 사용자를 오도할 수 있다는 것입니다. 저자들은 컨텍스트의 관련성만 측정하는 것은 잘못된 것이라고 생각합니다. 그들은 LLM이 질문에 답변할 수 있는 충분한 정보를 제공하는지 여부를 정말로 알고 싶어합니다. 저자들은 컨텍스트를 쿼리에 대한 결정적인 답변을 제공하는 데 필요한 모든 정보를 포함하는 경우 "충분"하다고 정의하고 필요한 정보가 부족한 경우 "불충분"하다고 정의합니다. 저자들은 LLM에 대한 컨텍스트 충분성을 정량화하는 방법을 개발하고 Vertex AI RAG 엔진에서 LLM Re-Ranker를 출시합니다. 저자들은 LLM이 질문에 대한 올바른 답변을 제공할 충분한 정보를 가지고 있는지 알 수 있다는 것을 보여줍니다. 저자들은 이러한 아이디어를 사용하여 RAG 시스템의 성능에 영향을 미치는 요인을 분석하고 성공 또는 실패하는 시점과 이유를 분석합니다. 저자들은 쿼리-컨텍스트 쌍을 평가하는 충분한 컨텍스트 자동 평가기를 개발하고 충분한 컨텍스트를 매우 높은 정확도로 분류할 수 있음을 보여줍니다. 저자들은 자체 충분한 컨텍스트 자동 평가기를 사용하여 다양한 LLM 및 데이터 세트의 성능을 분석하여 몇 가지 주요 결과를 얻습니다.