RSS 구글 AI 블로그
팔로우
명확화 학습: 액션 기반 대조적 자기 학습을 통한 다중 턴 대화
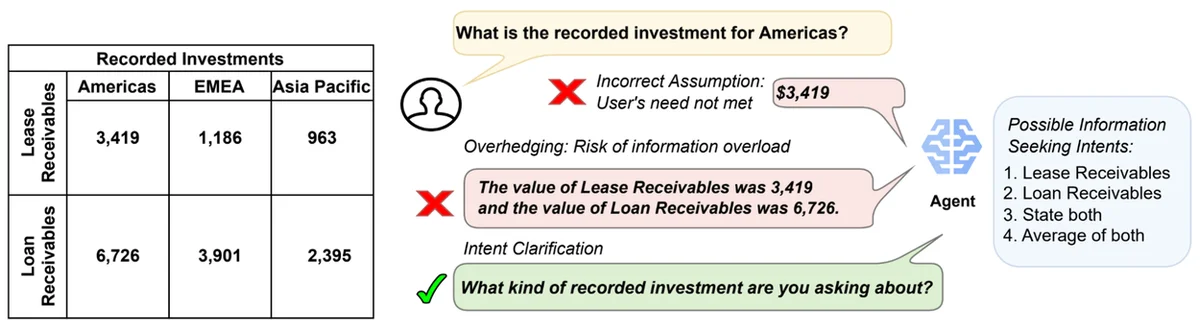
대규모 언어 모델(LLM)은 지능적인 대화형 에이전트 개발의 주요 패러다임이 되었지만, 종종 모호성 해소와 같은 다중 턴 대화 기술이 부족합니다. 이를 해결하기 위해 저자들은 Action-Based Contrastive Self-Training (ACT)를 제안합니다. ACT는 준온라인 선호도 최적화 알고리즘으로, 다중 턴 대화 모델링에서 데이터 효율적인 대화 정책 학습을 가능하게 합니다. ACT는 지도 학습 미세 조정 및 DPO와 같은 표준 조정 방식에 비해 상당한 대화 모델링 개선을 보여줍니다. 저자들은 또한 복잡한 구조적 쿼리 언어 (SQL) 코드 생성을 위한 정보 검색 요청의 모호성을 해소하는 새로운 태스크인 AmbigSQL을 소개합니다. ACT는 선호도 데이터셋 구축, 거부된 응답 합성, DPO 목표를 사용한 정책 모델 조정으로 구성됩니다. 저자들은 다양한 대화 데이터셋에서 오픈 웨이트 LLM을 사용하여 ACT를 실험하고, 지도 학습 미세 조정, 반복적 추론 선호도 최적화, 인컨텍스트 학습 예제를 사용하여 Gemini 및 Claude 프롬프팅을 포함한 다양한 경쟁적인 베이스라인과 비교합니다. ACT는 모든 지표에서 최고의 성능을 달성하며, 조정된 모델이 암묵적으로 모호성을 인식하는 능력을 측정할 때 지도 학습 미세 조정에 비해 최대 19.1%의 상대적 개선을 보입니다. 저자들은 또한 ACT의 각 구성 요소의 이점을 이해하기 위해 절제 연구를 수행하고, 행동 기반 선호도, 온-폴리시 샘플링, 궤적 시뮬레이션이 다중 턴 목표 완료 개선에 중요하다는 것을 발견했습니다. 전반적으로 ACT는 사전 인간 피드백과의 정렬 여부에 관계없이 성능을 향상시킬 수 있는 모델에 구애받지 않는 접근 방식입니다.