핀터레스트에서 대규모 학습 검색 시스템 구축
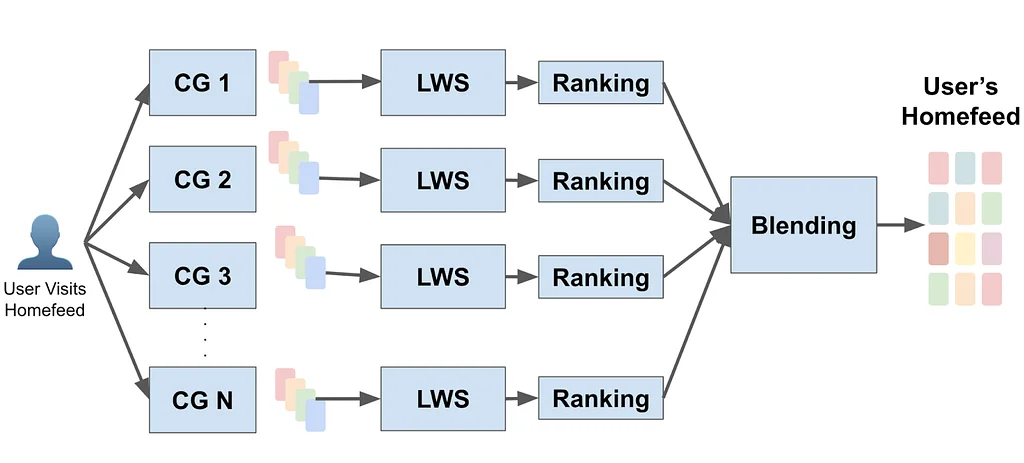
핀터레스트에서는 사용자가 사랑하는 삶을 창조하도록 영감을 주는 것이 미션이며, 이를 위해 온라인에서 적절한 콘텐츠를 찾는 것이 중요합니다. 회사의 추천 시스템은 사용자에게 적절한 콘텐츠를 제공하는 데 여러 단계를 포함하는데, 이를 포함하여 검색 및 랭킹이 있습니다. 랭킹 모델은 사용자의 장기 및 단기 참여도를 포착하는 강력한 트랜스포머 기반 모델입니다. 그러나 검색 시스템은 이전에는 휴리스틱 접근 방식에 기반을 두고 있었습니다. 이를 개선하기 위해 핀터레스트는 로그된 사용자 참여 이벤트에서 학습한 내부 임베딩 기반 검색 시스템을 구축했으며, 이는 홈피드 및 알림에 배포되었습니다. 이 시스템은 쿼리 임베딩을 학습하는 한 탑과 아이템 임베딩을 학습하는 다른 탑으로 구성된 2탑 접근 방식을 사용하여 온라인 서비스에서 효율적인 최근접 이웃 검색을 가능하게 합니다. 모델은 인기 편향을 보정하고 사용자의 장기 참여도, 프로필 및 컨텍스트를 입력으로 인코딩하는 샘플드 소프트맥스 접근 방식으로 훈련됩니다. 시스템 설계는 아이템 임베딩을 온라인 서비스 및 오프라인 색인으로 나누고, 사용자 지식 및 최근 트렌드를 캡처하는 자동 재훈련 워크플로우를 포함합니다. 모델 버전 동기화를 보장하기 위해 각 ANN 검색 서비스 호스트에 모델 버전 메타데이터가 첨부되어 있으며, 이는 모델 이름에서 최신 모델 버전으로의 매핑을 포함합니다. 학습된 검색 후보 생성기는 최고의 사용자 커버리지 및 상위 3개의 저장률을 달성했으며, 2개의 다른 후보 생성기를 대체하여 사이트 전체 참여도에서 큰 승리를 거두었습니다.