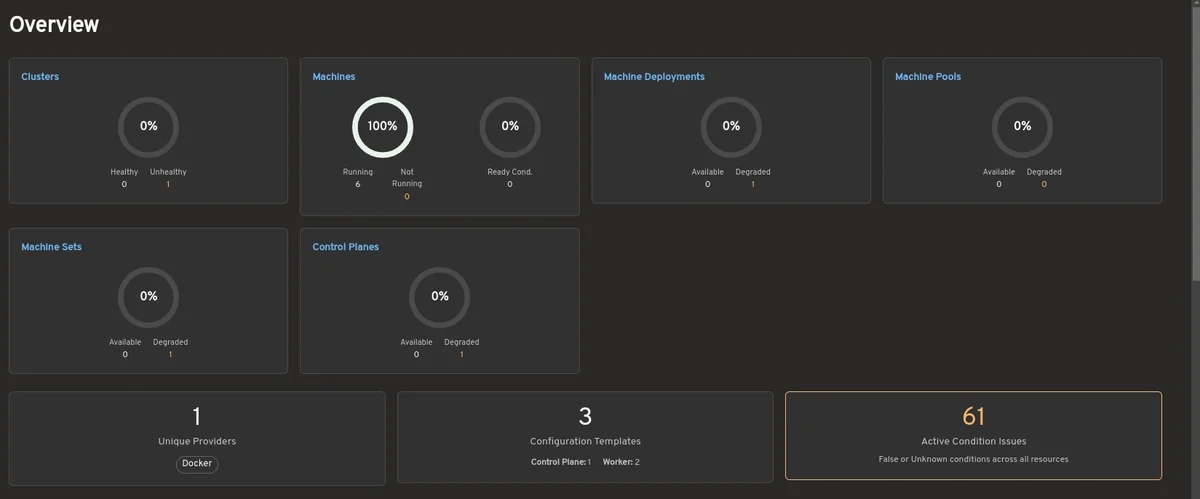
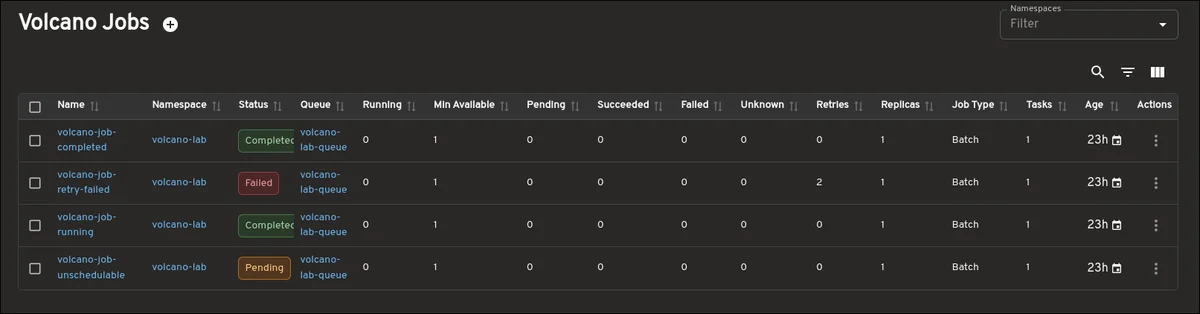
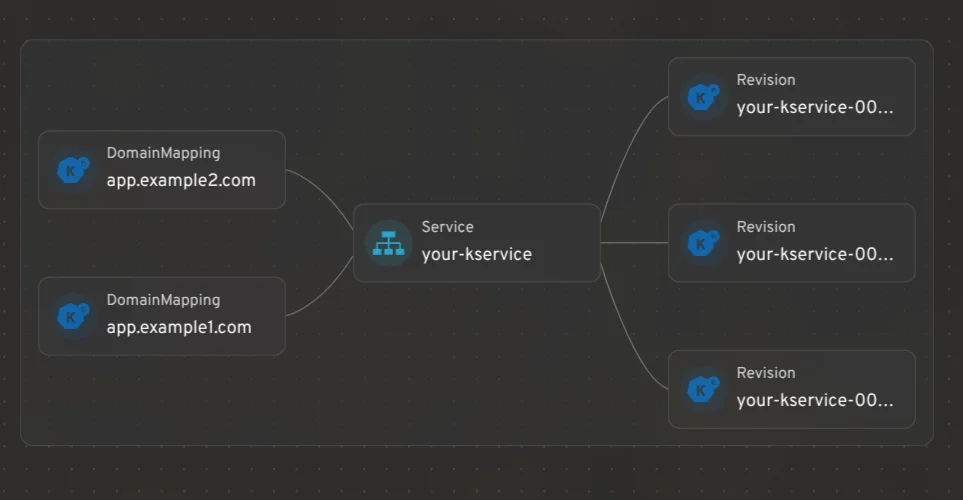
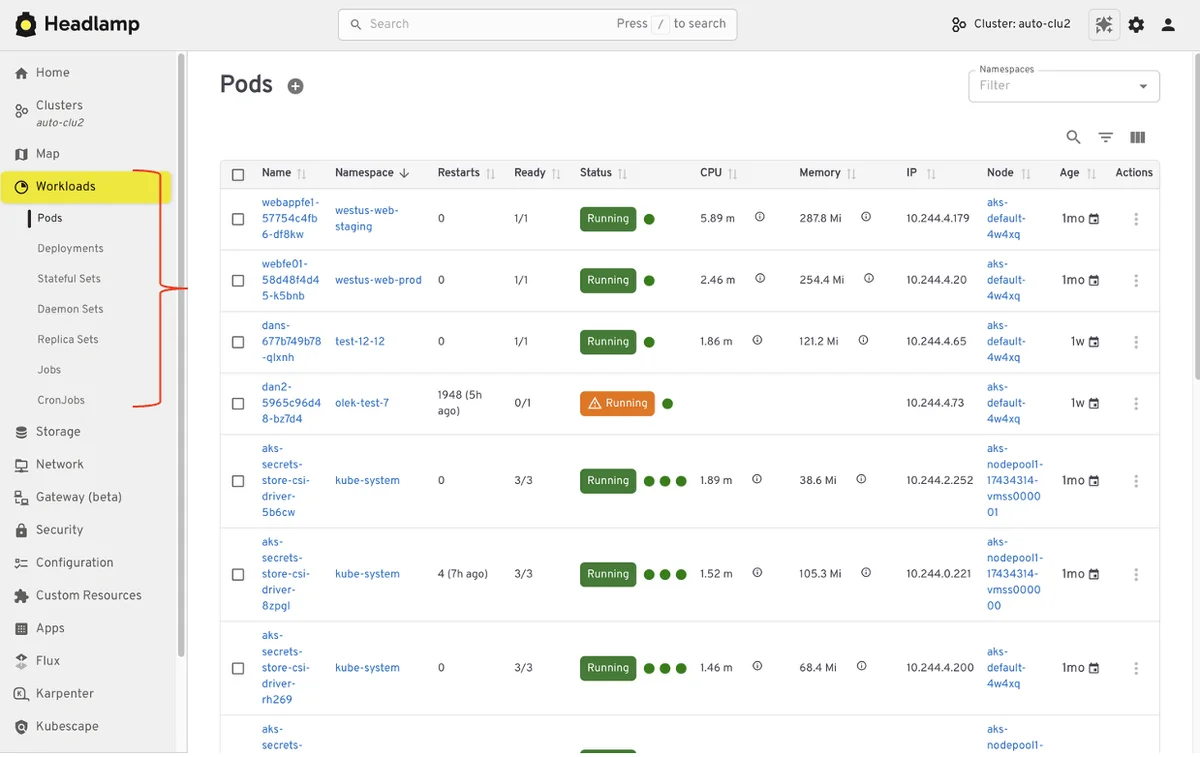
RSS 쿠버네티스 블로그 팔로우
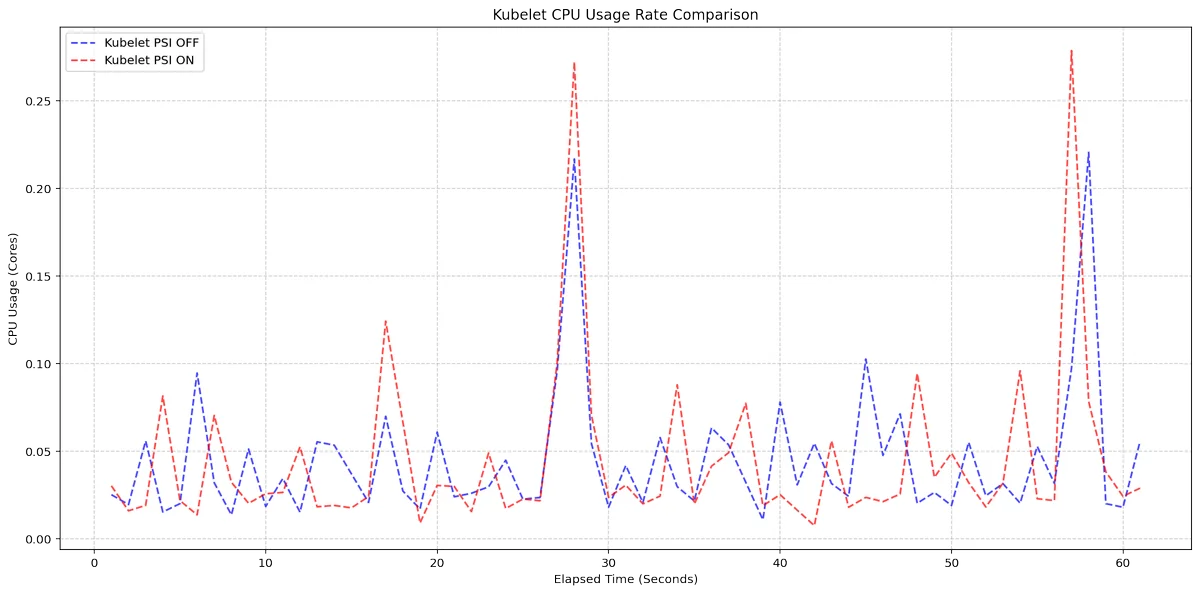
쿠버네티스의 공식 홈페이지, 컨테이너 오케스트레이션 시스템으로 컨테이너화된 애플리케이션의 배포, 크기 조정 및 관리를 자동화하는 데 사용됩니다. 클라우드 네이티브 컴퓨팅 재단에서 유지하는 프로젝트인 쿠버네티스에 대한 포괄적인 문서를 제공하는 플랫폼입니다. 상태가 없는 애플리케이션과 상태가 있는 애플리케이션, 배치 작업 및 CI/CD 워크플로우를 쿠버네티스를 사용하여 실행하는 방법에 대한 세부적인 정보를 포함합니다. 이 사이트에는 쿠버네티스를 시작하고 이를 통해 클라우드 기반 애플리케이션을 효율적으로 관리하는 데 필요한 기능을 최대한 활용하는 데 도움이 되는 자세한 가이드, 튜토리얼, 참조 자료, API 문서 및 커뮤니티 참여 이니셔티브가 포함되어 있습니다.