RSS 구글 AI 블로그
팔로우
사용자 수준 차등 프라이버시를 이용한 LLM 미세 조정
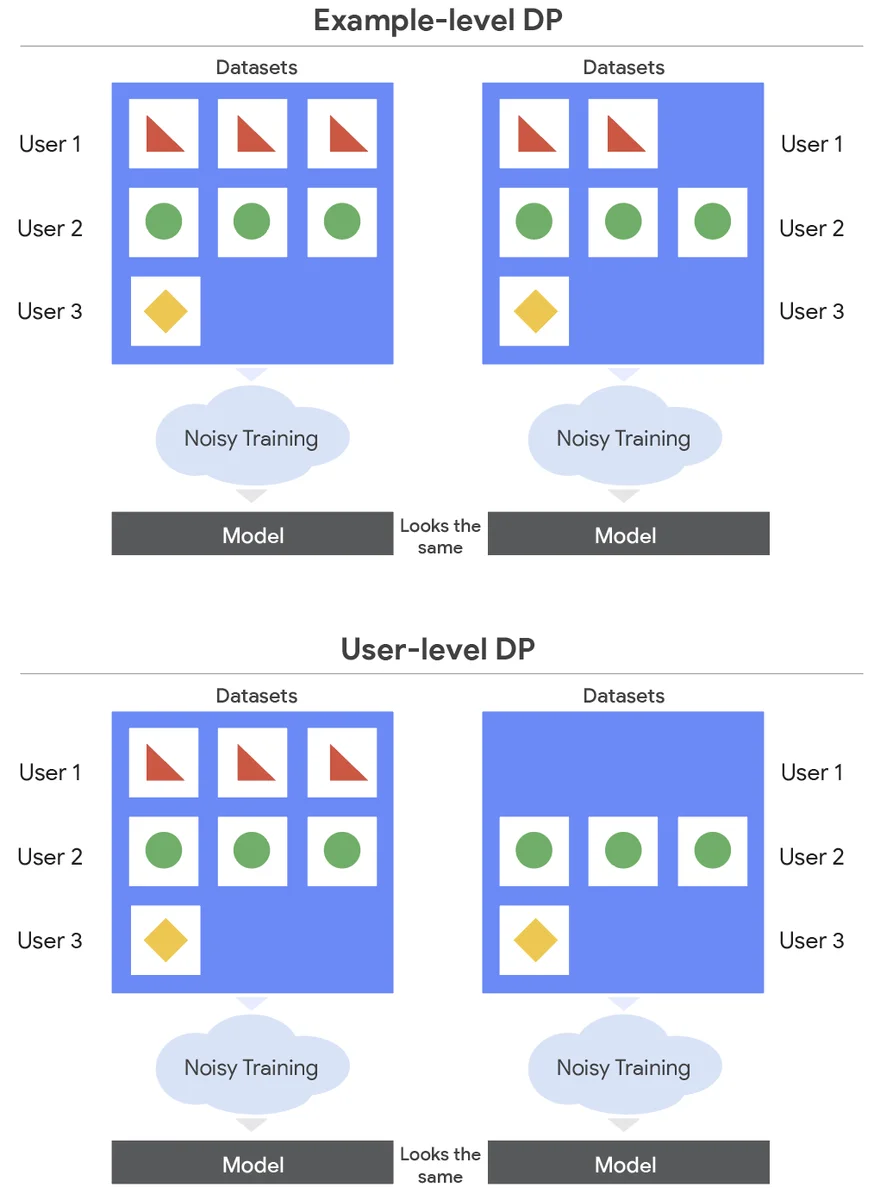
머신 러닝 모델은 도메인별 데이터에 대한 미세 조정을 필요로 하지만, 이는 개인 정보 보호 문제로 인해 문제가 될 수 있습니다. 차등 프라이버시(DP)는 개인 정보를 존중하면서 모델을 훈련할 수 있게 해주지만, 대부분의 연구는 예제 수준 DP에 집중하며, 이는 단점이 있습니다. 사용자 수준 DP는 공격자가 자신의 데이터에 대해 알 수 없도록 보장하는 더 강력한 형태의 개인 정보 보호이며, 연합 학습에 사용됩니다. 사용자 수준 DP로 학습하는 것은 더 어렵고 더 많은 노이즈를 추가해야 하며, 이는 더 큰 모델일수록 악화됩니다. 이 논문은 데이터센터 훈련에서 사용자 수준 DP로 대규모 언어 모델을 미세 조정하는 데 초점을 맞춥니다. 저자들은 노이즈를 추가하고 각 사용자가 모델에 미치는 영향을 제한하기 위해 확률적 경사 하강법(SGD)을 수정했습니다. 그들은 데이터를 샘플링하는 방식에서 차이가 있는 두 가지 방법, 예제 수준 샘플링(ELS)과 사용자 수준 샘플링(ULS)을 비교합니다. 저자들은 이러한 알고리즘을 대규모 언어 모델에 최적화하여, ULS가 일반적으로 더 좋다는 것을 발견했으며, 두 방법 모두 엄격한 개인 정보 보호 요구 사항에도 불구하고 미세 조정하지 않은 것보다 더 나은 성능을 보였습니다. 이러한 최적화를 통해 모델 트레이너는 강력한 사용자 보호를 제공하면서 민감한 데이터 세트에 대한 모델을 미세 조정할 수 있습니다.