RSS Блог Google AI
Подписаться
Достижение 10 000-кратного сокращения обучающих данных с высокоточными метками
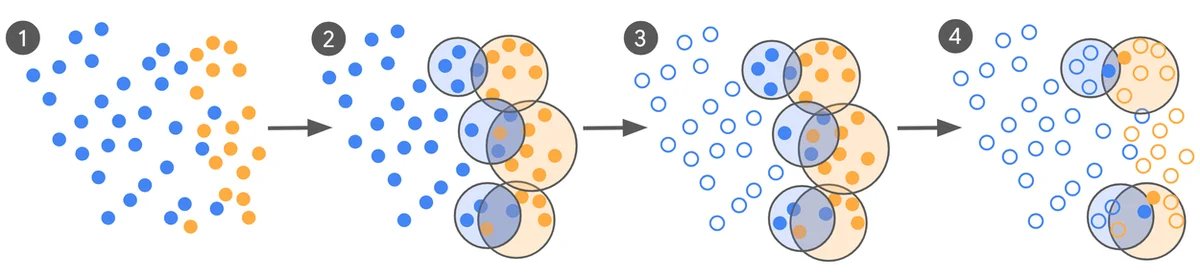
Классификация небезопасного рекламного контента — сложная задача, для которой большие языковые модели (LLM) подходят хорошо благодаря своему контекстному пониманию. Однако для дообучения LLM для таких задач требуются высококачественные, масштабные обучающие данные, сбор которых дорог и занимает много времени. Дрейф концепций, когда политики безопасности меняются, требует частого переобучения, что увеличивает расходы. Для решения этой проблемы новый процесс кураторства на основе активного обучения значительно сокращает объем необходимых обучающих данных, улучшая при этом соответствие модели экспертам. Этот процесс выявляет наиболее ценные примеры для аннотирования, значительно снижая потребность в данных. Эксперименты показали сокращение обучающих данных со 100 000 до менее чем 500 примеров, при этом соответствие модели улучшилось до 65%. Процесс кураторства начинается с того, что LLM, работающая в режиме "нулевого выстрела" (zero-shot), размечает данные, затем используется кластеризация для выявления запутанных примеров. Эти информативные и разнообразные примеры затем отправляются экспертам для маркировки. Метки экспертов используются для итеративной оценки и дообучения моделей. Процесс полагается на Каппу Коэна для измерения соответствия, поскольку эталонные метки часто неоднозначны. Базовые модели, дообученные на больших краудсорсинговых наборах данных, работали менее эффективно по сравнению с кураторскими моделями. Новый метод демонстрирует, что тщательный отбор меньшего количества более информативных примеров может привести к значительному повышению производительности при гораздо меньшем объеме данных. Этот подход особенно выгоден для таких областей, как безопасность рекламы, с быстро меняющимся контентом.