RSS Блог Google AI Подписаться
Google Research - это блог, цель которого - поделиться последними открытиями и идеями, полученными от научного сообщества Google Research. Эта платформа служит для исследователей средством общения с пользователями за пределами научных кругов, обсуждения новых и перспективных технологий, идей и инноваций.
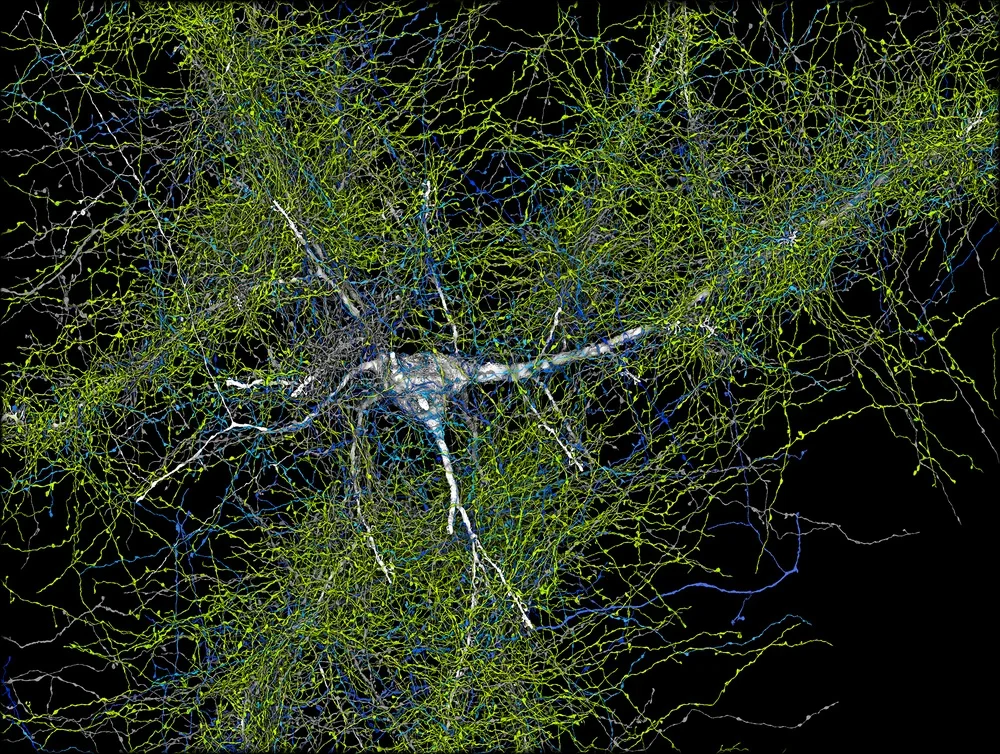
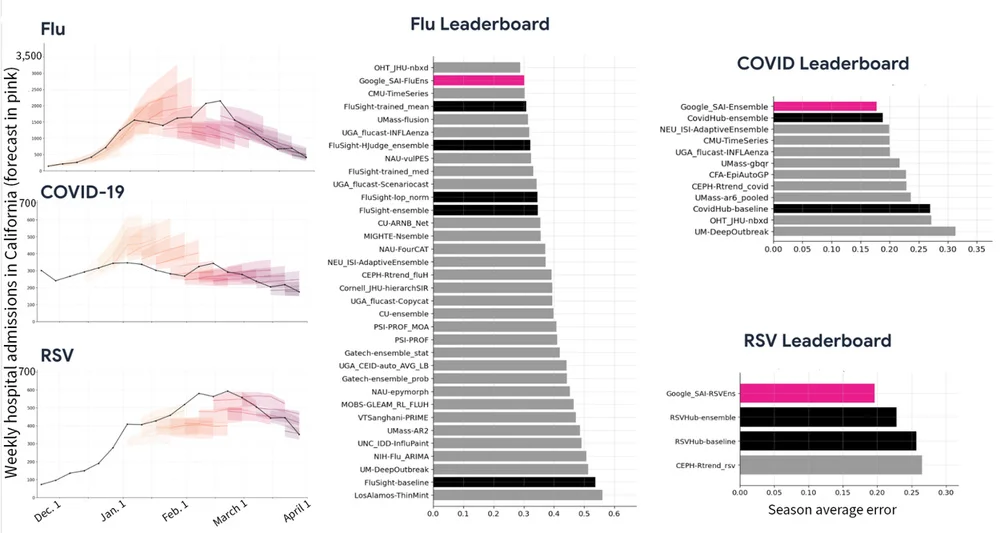
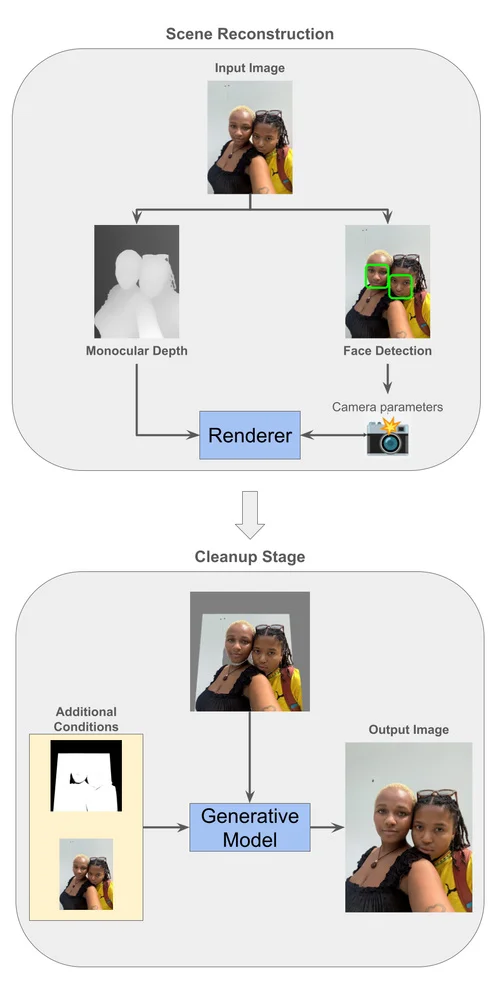
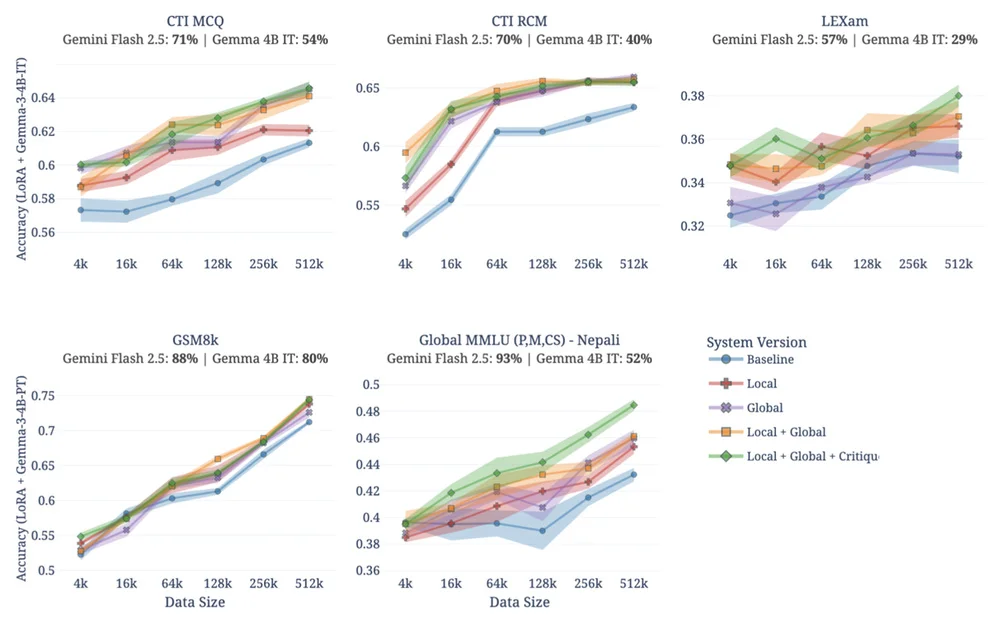
Google Research часто публикует материалы на различные научные темы - от искусственного интеллекта и машинного обучения до инноваций в здравоохранении. Кроме того, в блоге часто обсуждаются новые технологии - от самоуправляемых автомобилей до передовых методов медицинской диагностики и анализа данных.
Примечательной особенностью блога является вклад членов команды. Многие из ведущих технологов и исследователей Google предлагают интересные статьи, отражающие их разнообразные интересы и навыки. На этом сайте можно узнать о последних достижениях и перспективах развития мира технологий из первых рук.
В блоге есть раздел «Авторы», в котором пользователи могут ознакомиться со статьями и мнениями отдельных авторов. Помимо технических дискуссий и инноваций, блог также затрагивает более широкие социальные и философские вопросы, связанные с новыми технологиями, что позволяет пользователям получить более полное представление о том, как технологии влияют на нашу повседневную жизнь.
По сути, блог Google Research предлагает уникальное сочетание технических знаний, научных открытий и социальных последствий, что делает его ценным ресурсом для энтузиастов технологий, исследователей и всех, кто заинтересован в понимании и формировании технологий будущего.