RSS Блог Google AI
Подписаться
Обеспечение конфиденциальности больших объемов частных данных с помощью дифференциально-приватного выбора разделов
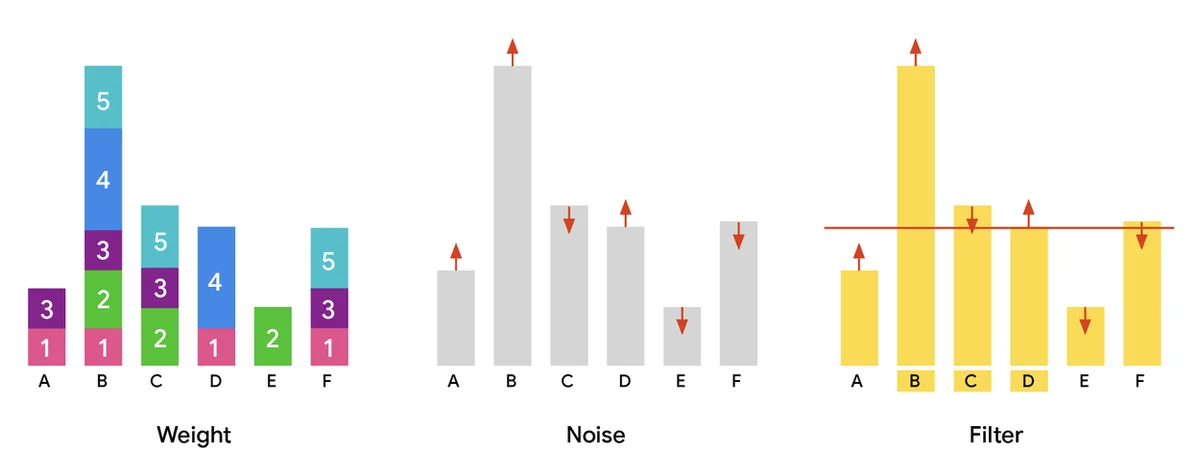
Большие наборы данных, основанные на пользователях, являются жизненно важными для развития ИИ, улучшения услуг и персонализации. Обмен этими наборами данных ускоряет исследования, но создает риски для приватности. Дифференциально-частичное (ДЧ) выделение разделов идентифицирует безопасные, общие подмножества данных, добавляя шум для защиты индивидуальных вкладов. Это имеет решающее значение для задач, таких как извлечение словаря и частный анализ данных. Обработка огромных наборов данных требует параллельных алгоритмов, не только для скорости, но и для обработки огромных масштабов. Наша публикация, «Масштабируемое частное выделение разделов через адаптивное взвешивание», представляет эффективный параллельный алгоритм для ДЧ выделения разделов. Этот алгоритм масштабируется до сотен миллиардов элементов, значительно превышая предыдущие возможности. Целью является максимизация выбранных элементов, сохраняя приватность пользователей, приоритизируя популярные данные. Стандартный подход заключается в взвешивании, добавлении шума и фильтрации элементов на основе порогового значения. Наш новый алгоритм адаптивного взвешивания, MAD, перераспределяет «избыточное вес» от популярных элементов к тем, которые чуть ниже порога приватности. Это улучшает полезность, включая больше элементов без компромисса приватности или масштабируемости. Эксперименты показывают, что наш двухитерационный алгоритм MAD достигает результатов на уровне состояния искусства, выводя больше элементов, чем другие методы с теми же гарантиями приватности. Мы открыто публикуем наш алгоритм, чтобы стимулировать инновации в сообществе.