RSS Блог Google AI
Подписаться
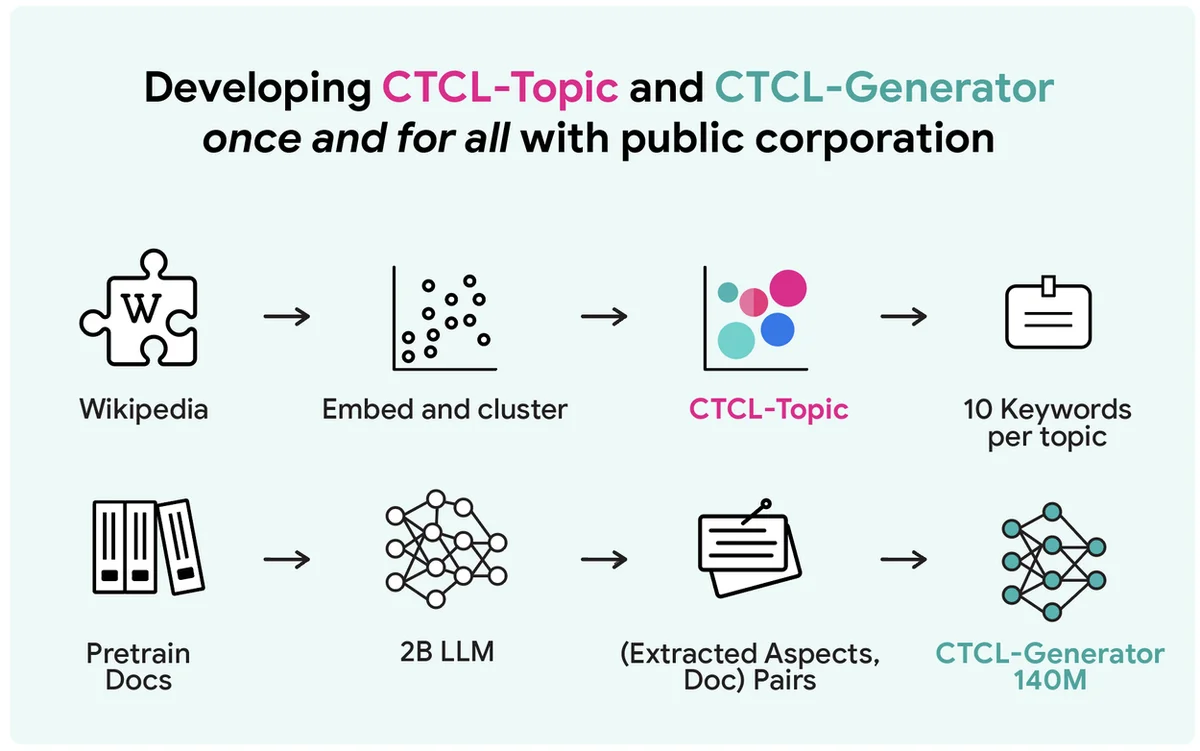
За гранью миллиарда параметров: Разблокировка синтеза данных с помощью условного генератора
Генерация крупномасштабных синтетических текстовых данных с дифференциальной приватностью сталкивается с торговым оффшором между приватностью, вычислениями и полезностью. Обычный, но вычислительно дорогой метод заключается в тонкой настройке крупных языковых моделей на частных данных. Существующие подходы на основе API, такие как Aug-PE, полагаются на ручные запросы и испытывают трудности с использованием частной информации. Предлагаемый фреймворк CTCL генерирует синтетические данные, сохраняющие приватность, без тонкой настройки массивных языковых моделей или требований к обширной инженерии запросов. Он использует легковесную модель с 140 миллионами параметров, что делает его подходящим для ресурсно-ограниченных сред. CTCL генерирует данные, учитывая тематическую информацию, чтобы соответствовать распределению частных данных. В отличие от Aug-PE, CTCL может производить неограниченное количество синтетических данных без дополнительных затрат на приватность. Эксперименты показывают, что CTCL превосходит базовые линии, особенно при сильных гарантиях приватности, демонстрируя свою эффективность в захвате полезной информации. Исследования абляции подтверждают важность предварительной тренировки и условий на основе ключевых слов для производительности и масштабируемости CTCL. Основная идея CTCL может быть расширена до более крупных моделей для улучшения реальных приложений.