RSS Блог Google AI
Подписаться
Проектирование синтетических наборов данных для реального мира: Проектирование механизмов и рассуждение из первых принципов
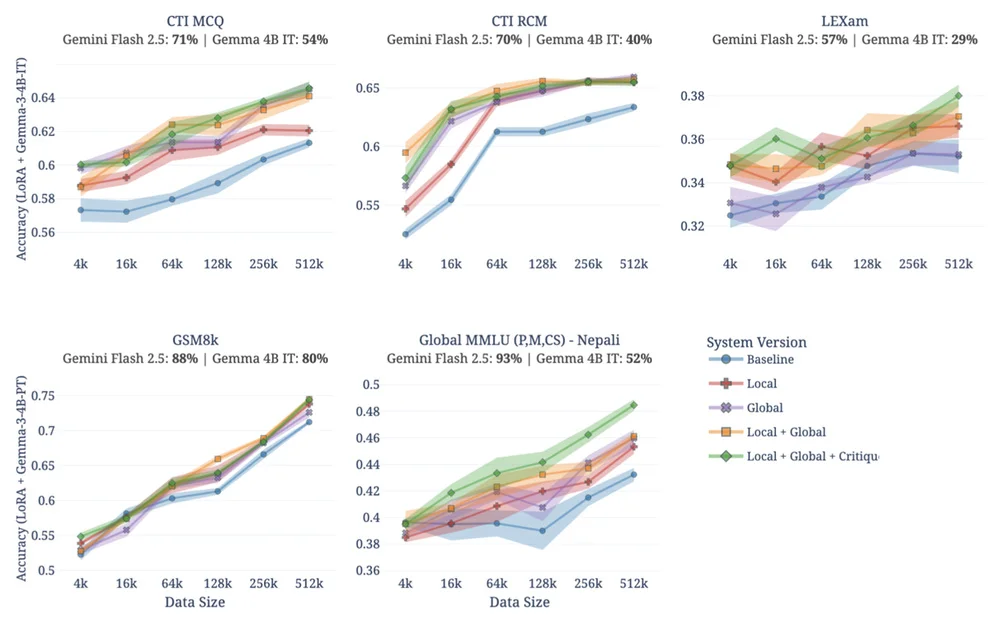
В статье рассматривается задача создания специализированных моделей ИИ путем генерации синтетических данных, что критически важно в тех случаях, когда реальные данные скудны или недоступны. Simula, предлагаемая структура, переосмысливает генерацию синтетических данных как проблему проектирования механизма, отдавая приоритет контролю. Подход Simula "рассуждение в первую очередь" создает наборы данных, исходя из основополагающих принципов, обеспечивая глобальную диверсификацию с помощью иерархических таксономий. Локальная диверсификация, использующая мета-подсказки, обеспечивает разнообразие внутри концепций и предотвращает коллапс моды. Структура также включает в себя усложнение для корректировки сложности и проверки качества для подтверждения правильности. Система Simula стабильно превосходит более простые базовые показатели в экспериментах в различных областях, таких как кибербезопасность и юридические рассуждения. Оценка использует метрики, основанные на рассуждениях, такие как таксономическое покрытие и калиброванная оценка сложности. Полученные результаты подчеркивают, что данные должны быть адаптированы к возможностям модели, при этом качество данных является более важным, чем просто объем. Simula служит механизмом обработки данных для Google, обеспечивая специализированные модели и функции защиты пользователей. Кроме того, Simula позволяет проводить исследования по синтезу реалистичных сценариев атак и обучению ИИ чтению карт. Синтетические данные имеют решающее значение для будущих достижений в области ИИ, и Simula демонстрирует потенциал управления генерацией данных.