RSS Блог о Kubernetes
Подписаться
Kubernetes v1.33: Потоковые ответы списка
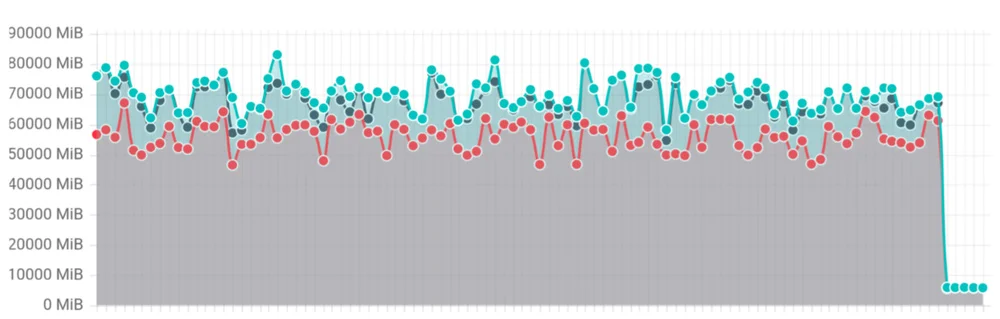
Управление стабильностью кластера является критически важным по мере роста инфраструктуры, а обработка больших запросов List может повлиять на стабильность кластера. Сообщество Kubernetes ввело кодирование потоков для ответов List, чтобы решить проблему ненужного потребления памяти при работе с большими ресурсами. Текущие кодеры ответов API хранят полные данные ответа в виде одного буфера, предотвращая постепенное освобождение памяти во время передачи. Этот подход становится неэффективным в крупном масштабе, что приводит к высокому и продолжительному потреблению памяти в процессе kube-apiserver. Пакет encoding/json и Protocol Buffers имеют ограничения при работе с большими наборами данных, подчеркивая потребность в подходах на основе потокового кодирования. Новый кодер потокового кодирования обрабатывает и передает каждый элемент по отдельности, позволяя постепенно освобождать по мере передачи кадров или фрагментов. Этот подход уменьшает требуемый объем памяти сервера API и сохраняет потребление памяти предсказуемым и управляемым. Кодер потокового кодирования спроектирован с обратной совместимостью, гарантируя байтовую идентичность с оригинальным кодером, и поддерживает все типы List Kubernetes без необходимости в изменениях на стороне клиента. Введение кодирования потоков привело к значительным улучшениям производительности, включая уменьшение потребления памяти, улучшение масштабируемости и увеличение стабильности. Результаты бенчмаркинга показали 20-кратное уменьшение потребления памяти, уменьшив его с 70-80 ГБ до 3 ГБ, демонстрируя эффективность нового механизма кодирования потоков.