RSS Stories by Pinterest Engineering on Medium
Подписаться
Масштабирование инфраструктуры машинного обучения Pinterest с помощью Ray: от обучения до конвейеров машинного обучения от начала до конца
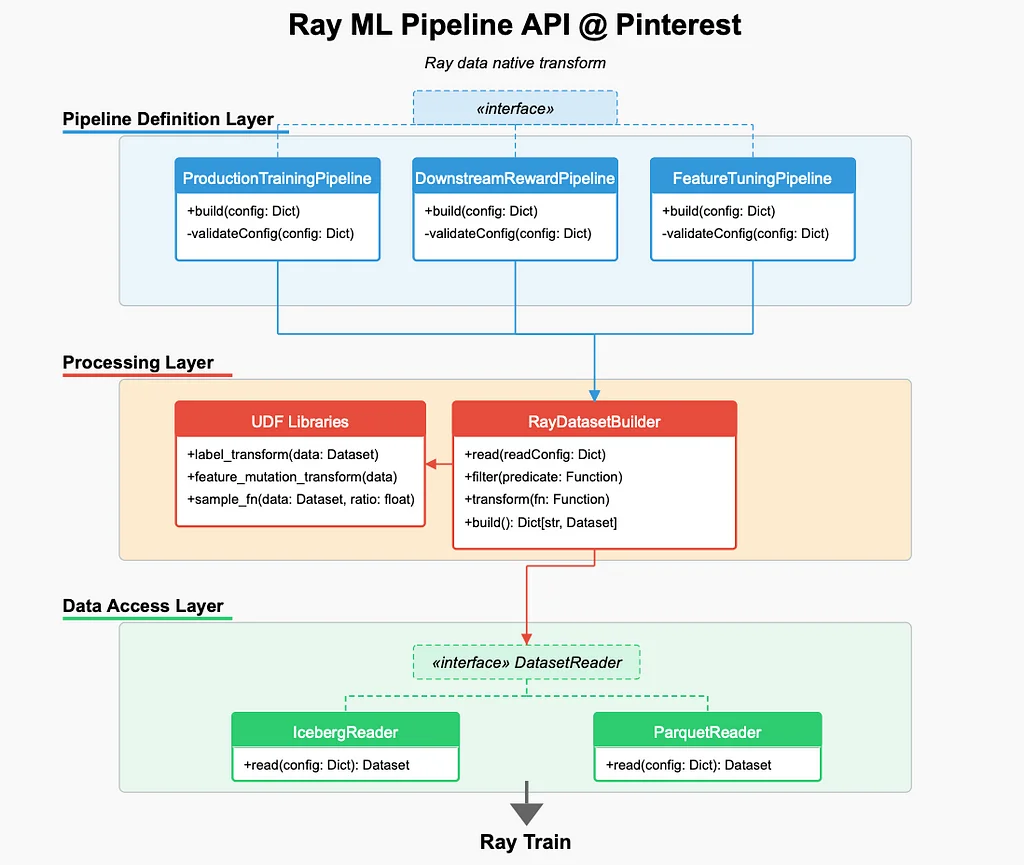
В Pinterest инженеры машинного обучения (ML) сталкиваются с трудностями при оптимизации разработки функций, стратегий выборки и экспериментов с метками из-за медленных конвейеров данных, дорогих итераций функций и неэффективного использования вычислительных ресурсов. Чтобы решить эти проблемы, Pinterest расширил возможности Ray за пределы обучения до разработки функций, выборки и моделирования меток. Традиционная инфраструктура машинного обучения была ограничена медленными конвейерами данных, дорогими итерациями функций и неэффективным использованием вычислительных ресурсов. Pinterest представил стек инфраструктуры машинного обучения на основе Ray, сосредоточившись на четырех основных улучшениях: создании родного API конвейера данных Ray, эффективном объединении данных с помощью Iceberg Bucket Joins, сохранении данных для эффективной итерации и оптимизации Ray Data для больших рабочих нагрузок. Новый рабочий процесс ML, основанный на Ray, уменьшает время итераций ML в 10 раз, значительно сокращая затраты на инфраструктуру. Родный API конвейера данных Ray позволяет разрабатывать функции, выборку и преобразования меток непосредственно в Ray, устраняя необходимость в заполнении Spark. Iceberg Bucket Joins обеспечивают быстрое и эффективное объединение функций из различных источников без предварительного вычисления больших таблиц. Сохранение данных позволяет эффективно итерировать, кэшируя преобразованные функции и повторно используя их при необходимости. Оптимизации Ray Data обеспечили ускорение в 2-3 раза в различных конвейерах, а новый рабочий процесс разблокировал более масштабируемую, эффективную и экономически эффективную инфраструктуру машинного обучения в Pinterest.