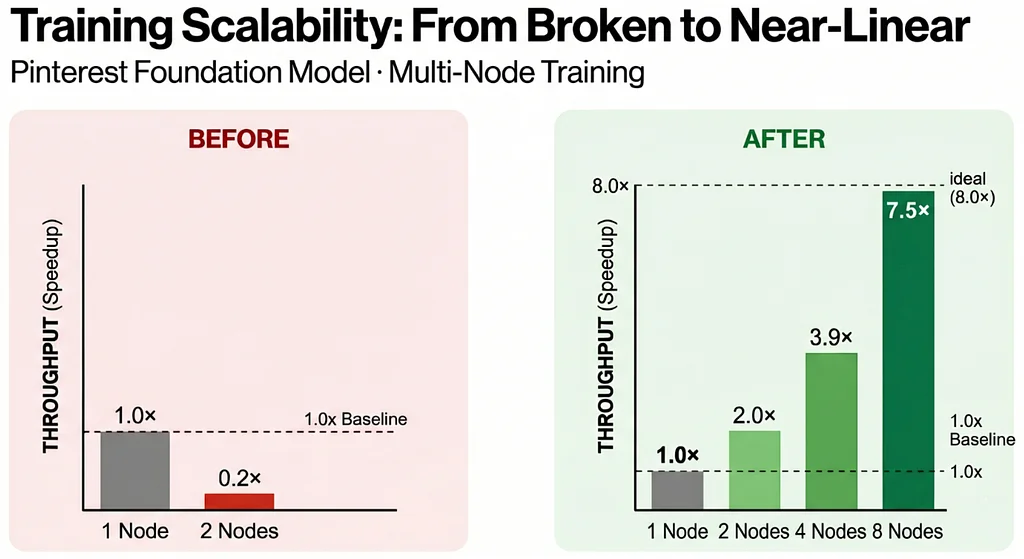
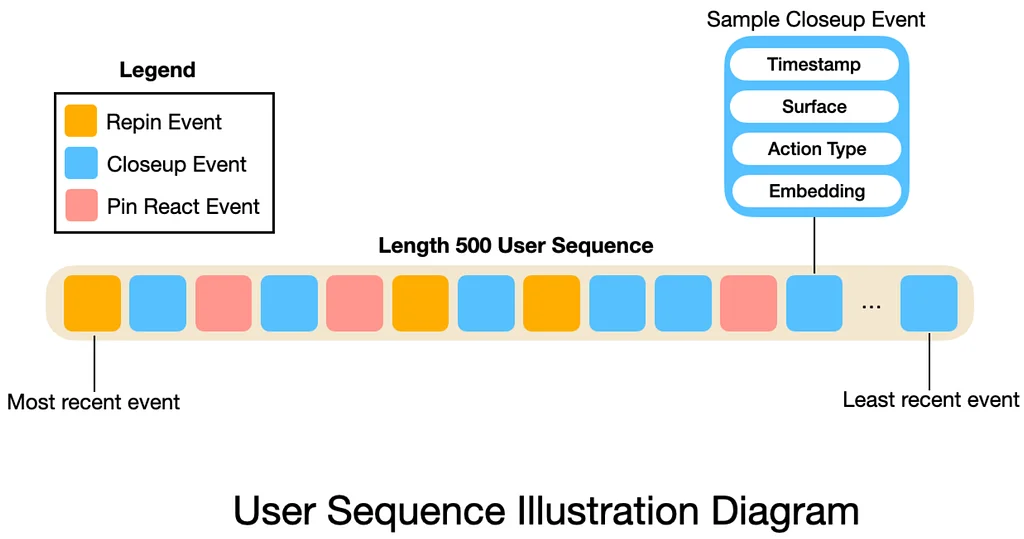
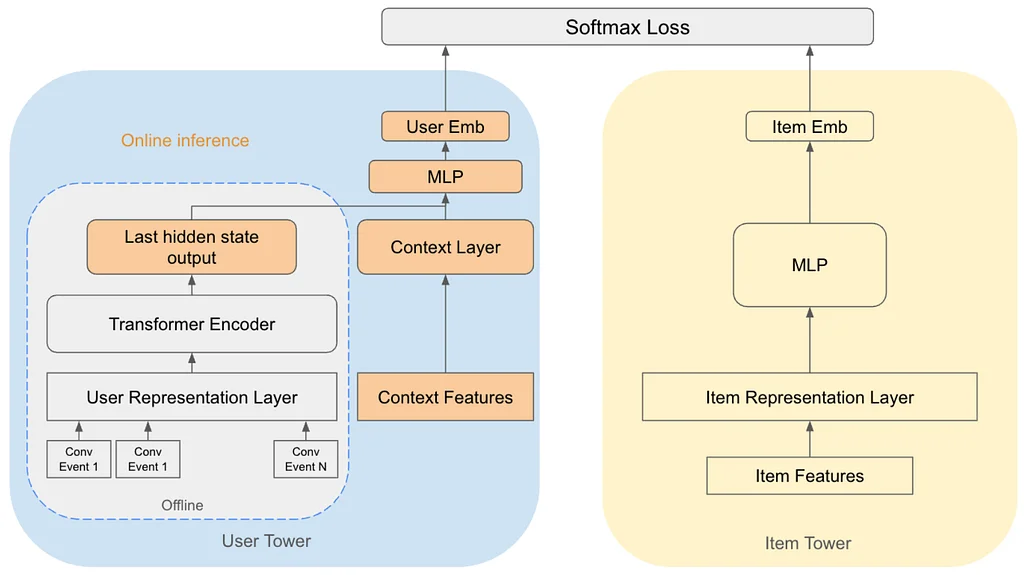
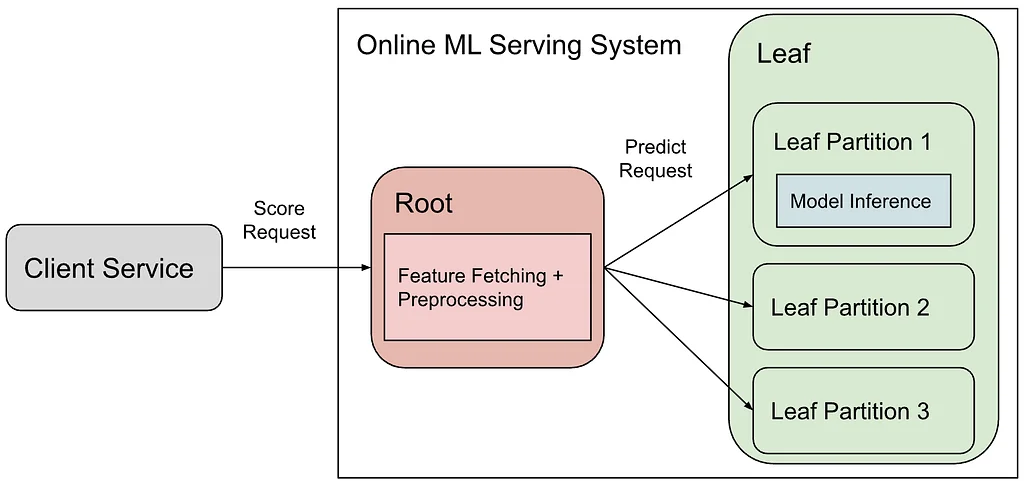
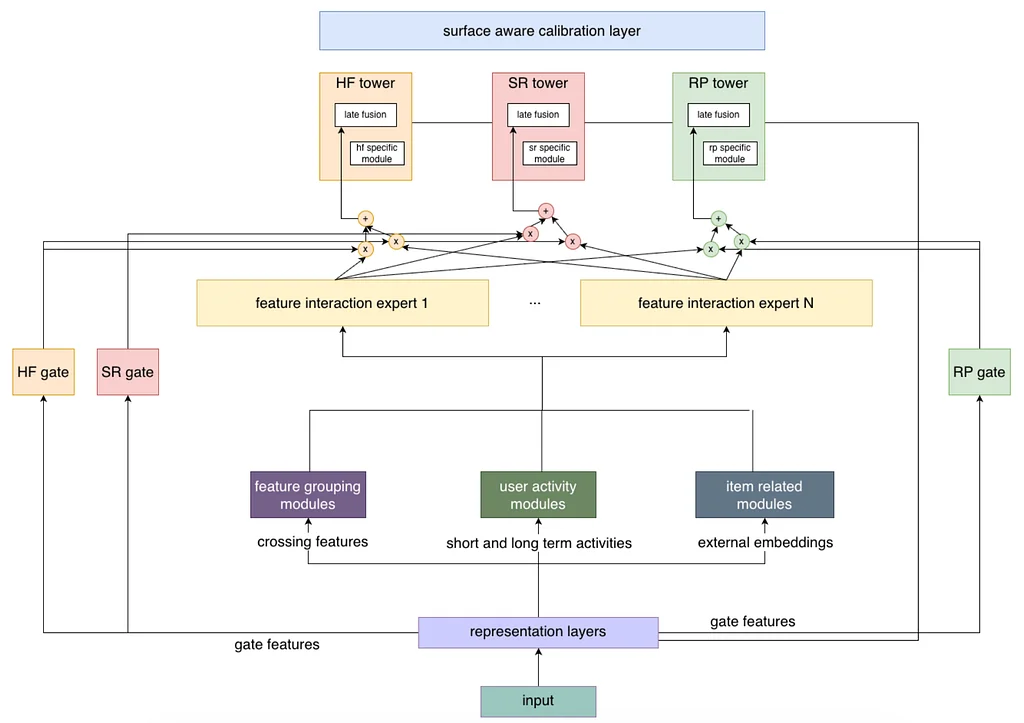
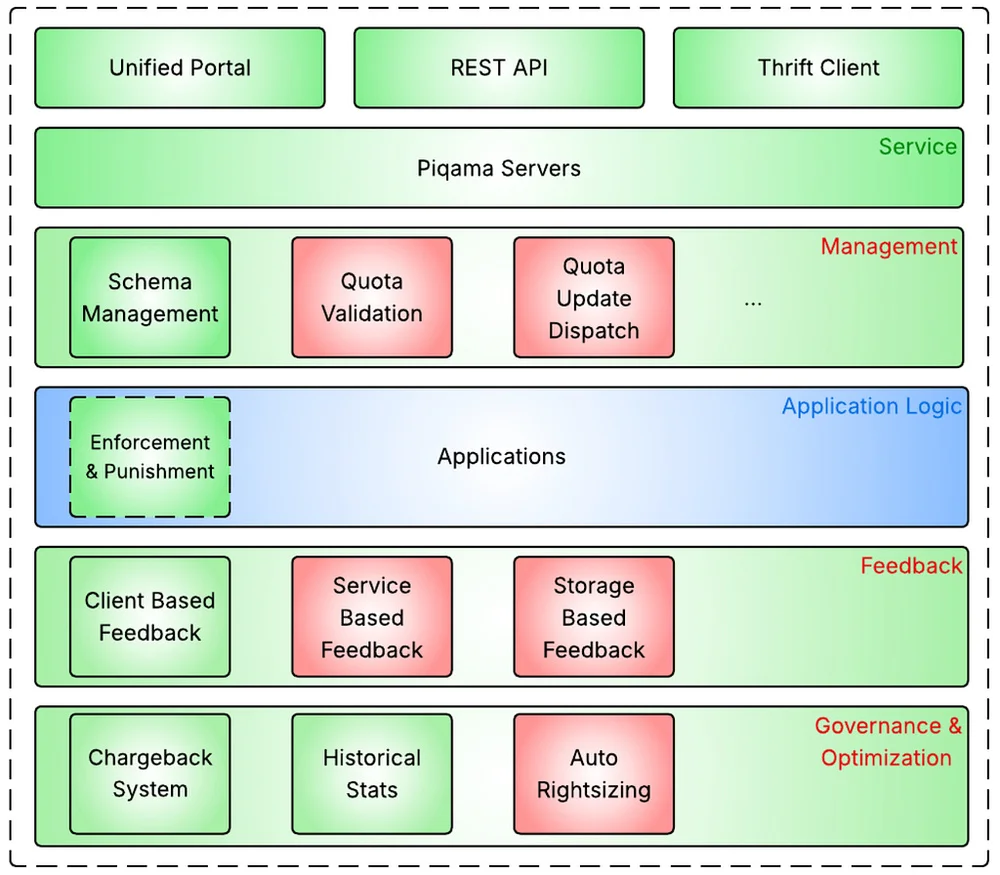
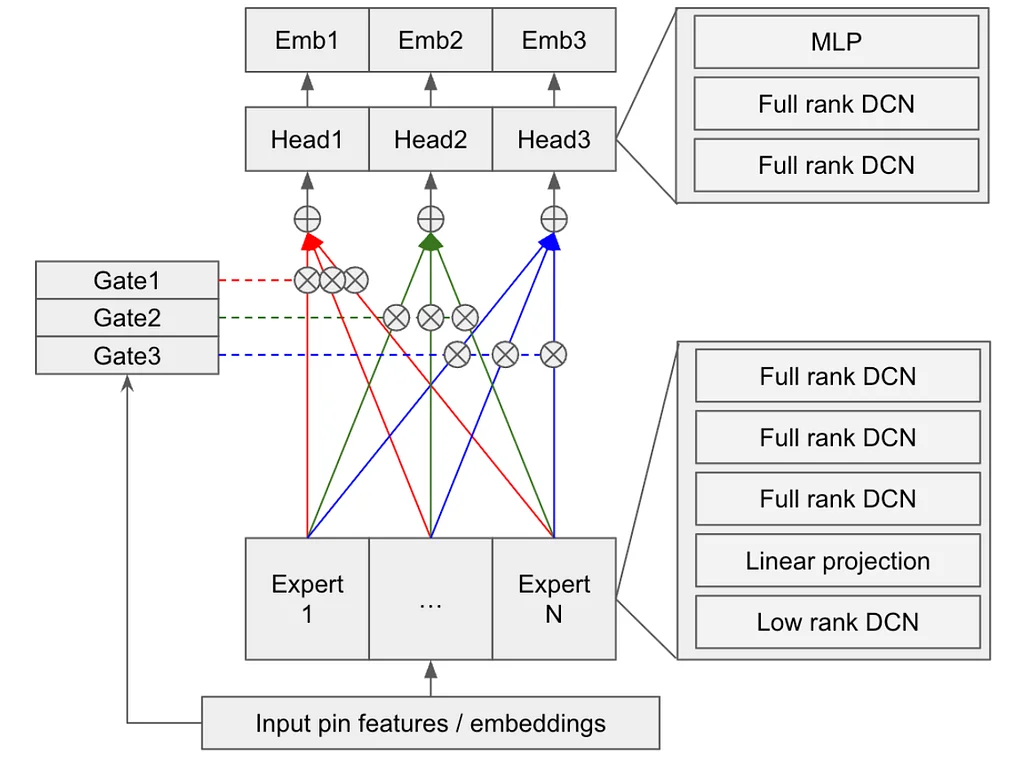
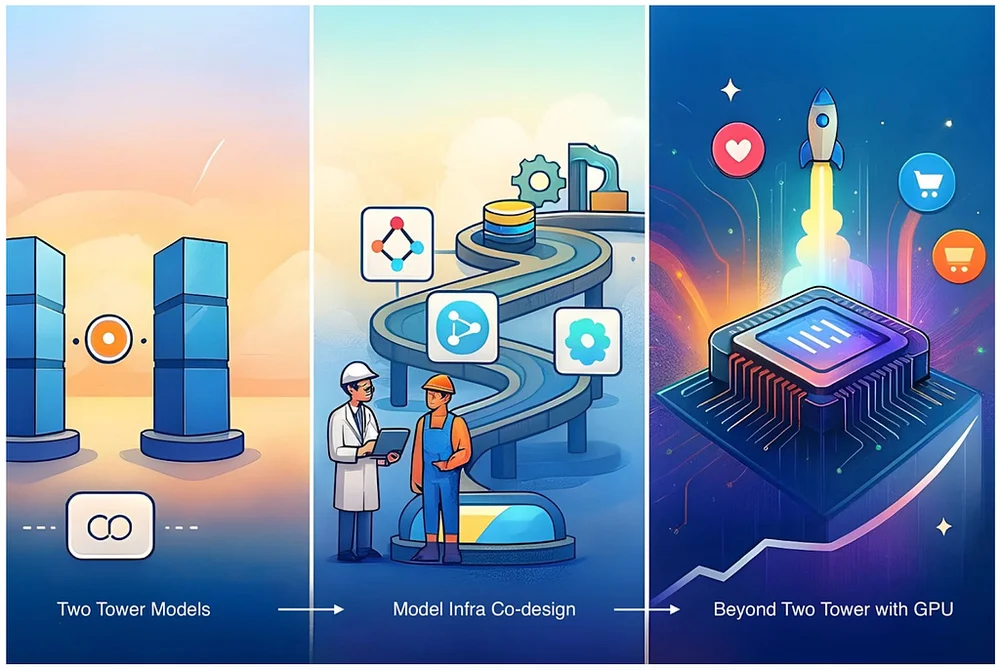
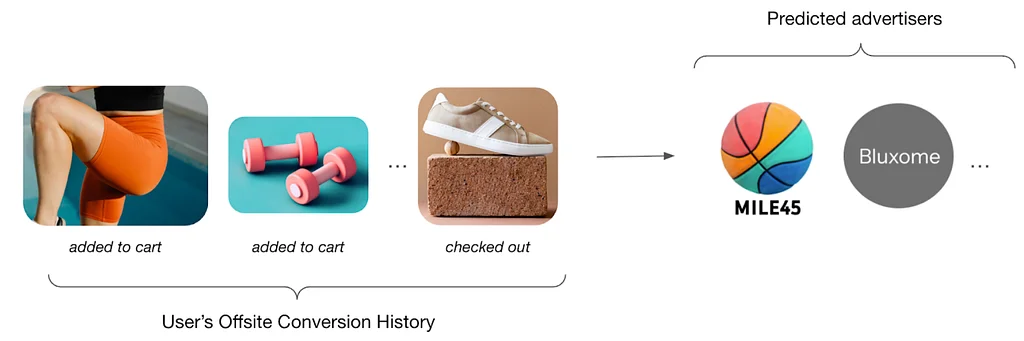
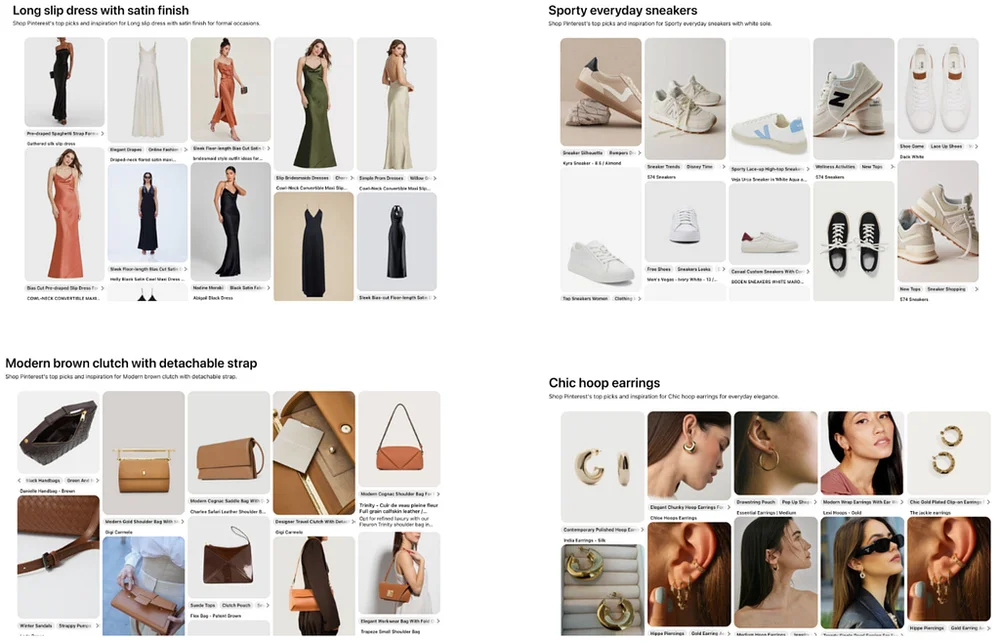
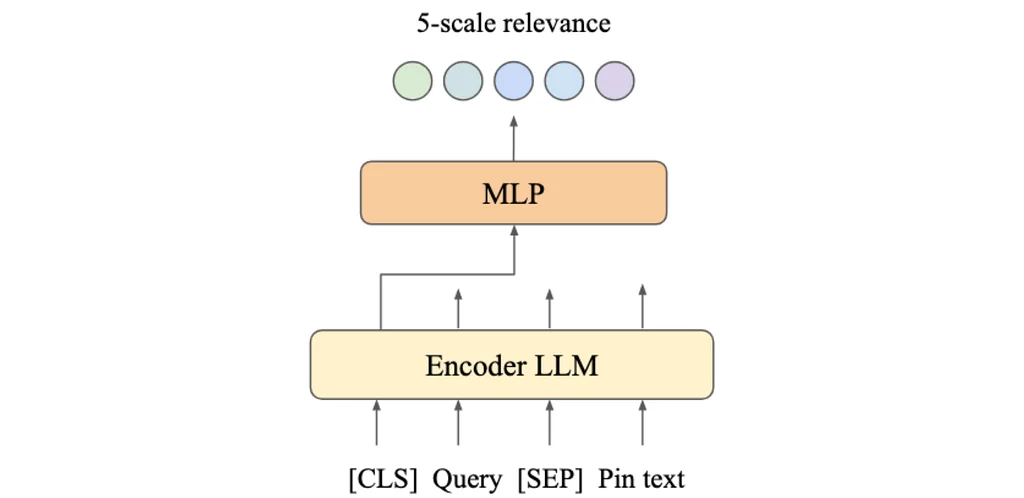
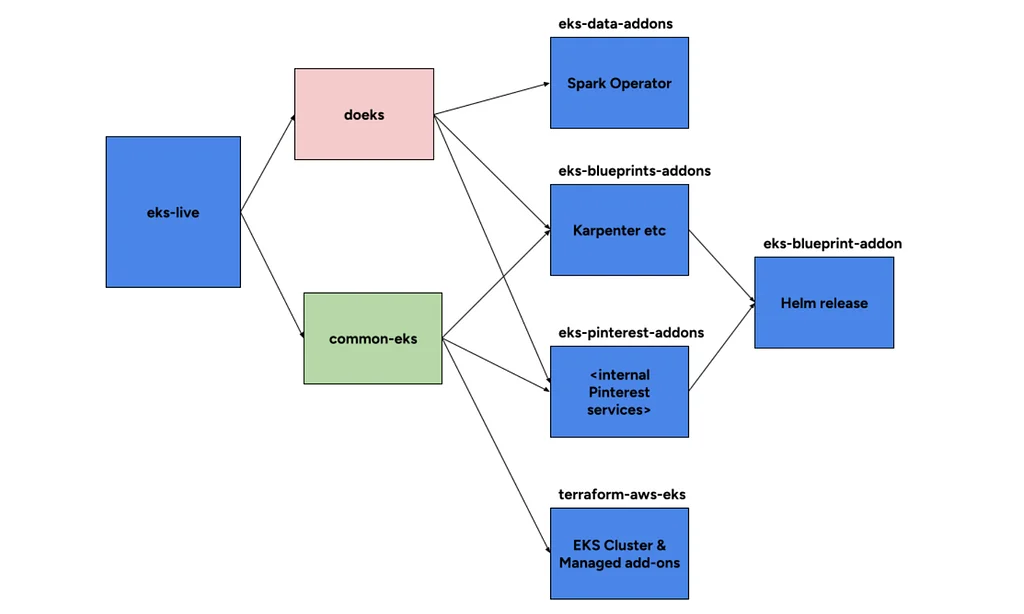
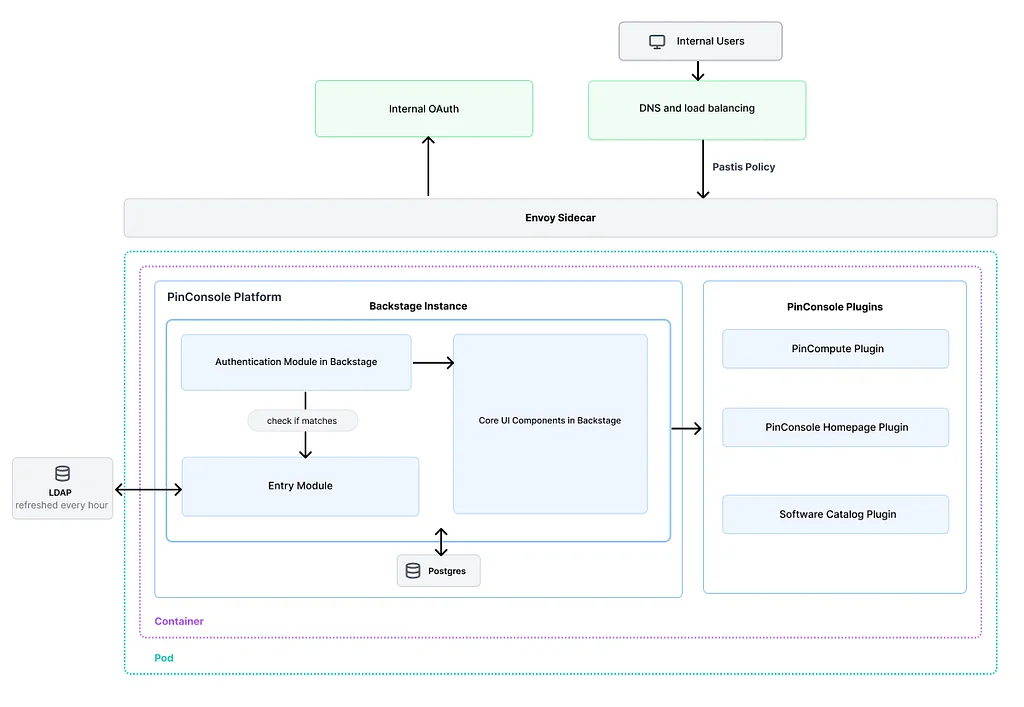
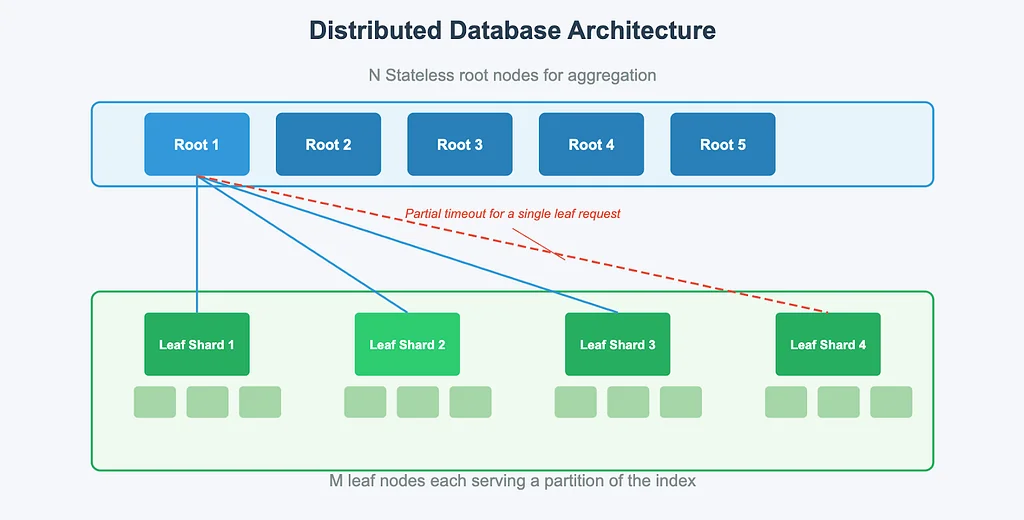
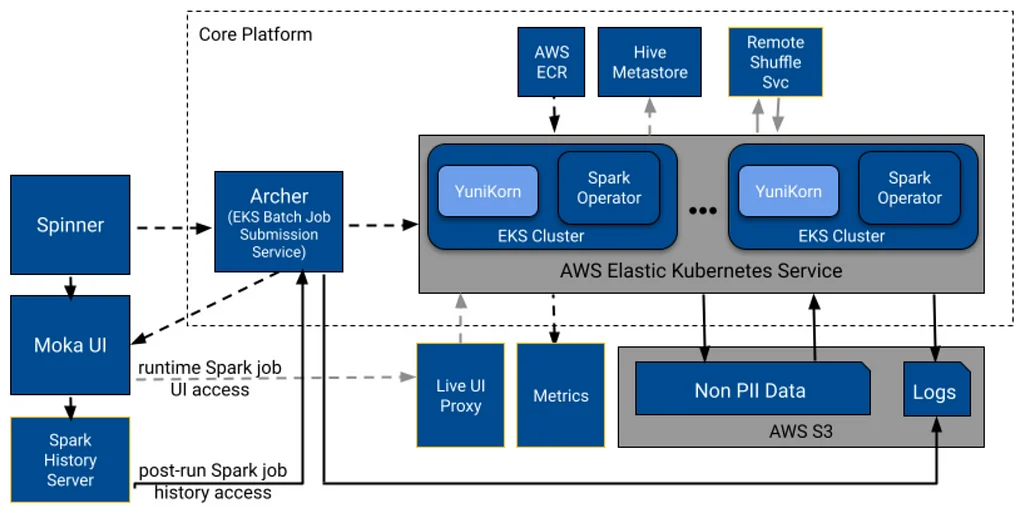
RSS Stories by Pinterest Engineering on Medium Подписаться
Сайт Pinterest Engineering, представленный на Medium, дает возможность заглянуть за кулисы технологических инноваций, лежащих в основе популярной платформы визуальных открытий. В подробных статьях инженеры рассказывают о своей работе над масштабируемостью, машинным обучением, инфраструктурой данных и многим другим. Издание подчеркивает инженерную культуру Pinterest, в которой особое место занимают сотрудничество, эксперименты и страсть к решению сложных проблем. Читатели могут изучить такие темы, как создание рекомендательных систем, оптимизация поисковой функциональности и разработка инструментов для анализа данных. Контент предлагает ценные перспективы для инженеров и любителей технологий, интересующихся тонкостями работы такой масштабной платформы, как Pinterest. Углубляясь в проблемы распознавания изображений или эволюции инфраструктуры, Pinterest Engineering на Medium предлагает увлекательный взгляд на техническую сторону любимого интернет-ресурса.