RSS Stories by Pinterest Engineering on Medium
Подписаться
Улучшение релевантности поиска в Pinterest с помощью больших языковых моделей
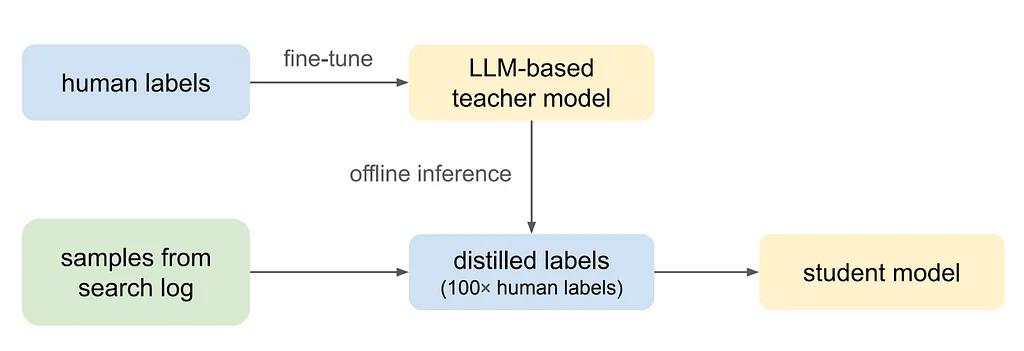
Поиск в Pinterest - это ключевая поверхность, где пользователи могут обнаружить вдохновляющий контент, соответствующий их информационным потребностям, а релевантность поиска измеряет, насколько хорошо результаты поиска соответствуют поисковому запросу. Чтобы улучшить модель релевантности поиска, используется 5-уровневое руководство для измерения релевантности между запросами и Pin'ами. Для прогнозирования релевантности Pin'а к запросу, вместе с текстом Pin'а, используется кросс-энкодер языковая модель, и задача формулируется как многоклассовая задача классификации. Модель дообучается с помощью данных, аннотированных людьми, минимизируя перекрестную энтропию.Для представления каждого Pin'а используется разнообразный набор текстовых особенностей, включая заголовки и описания Pin'ов, синтетические подписи к изображениям, токены запросов с высоким уровнем вовлеченности, названия досок, созданных пользователями, и названия и описания ссылок. Однако кросс-энкодерная LLM-основанная классификаторная модель трудна для масштабирования для поиска в Pinterest из-за соображений реального времени и стоимости. Поэтому используется дистилляция знаний для дистилляции LLM-основанной модели учителя в легкую модель релевантности ученика.Модель ученика использует особенности уровня запроса, особенности уровня Pin'а и особенности взаимодействия запроса и Pin'а для прогнозирования оценок релевантности по 5-балльной шкале. Дистилляция знаний и полуавтоматическое обучение используются для обучения модели ученика, что эффективно использует огромные объемы изначально неаннотированных данных и расширяет данные на широкий спектр языков со всего мира.Офлайн-эксперименты демонстрируют эффективность каждого решения моделирования, включая сравнение языковых моделей, важность обогащения текстовых особенностей и масштабирование обучающих меток посредством дистилляции. Онлайн-результаты показывают улучшение на +2,18% в релевантности ленты поиска, измеренной по nDCG@20, и значительный рост глобальных показателей выполнения поиска.Предлагаемый конвейер моделирования релевантности эффективно обобщается на языки, не встречавшиеся во время обучения, и многолингвальная LLM-основанная модель релевантности учителя обобщается на незнакомые языки. Будущая работа будет исследовать интеграцию служебных LLM, моделей vision-and-language и стратегий активного обучения для динамического масштабирования и улучшения качества обучающих данных.