Платформа машинного обучения Pinterest, MLEnv, столкнулась со значительным падением производительности после обновления версии PyTorch. Эта проблема привела к снижению пропускной способности обучения более чем на 50%. Процесс отладки начался с изучения пропускной способности GPU roofline. Это измерение выявило снижение производительности на 20% даже при исключении загрузчика данных. Дальнейший анализ был сосредоточен на отдельных модулях модели, чтобы точно определить источник замедления. Конкретный модуль-трансформатор, модуль A, был идентифицирован как основной виновник. Профилировщик PyTorch показал, что CompiledFunctions, присутствовавшие ранее, теперь отсутствовали для этого модуля в обновленной версии.Расследование torch.compile выявило журнал, указывающий на наличие режима диспетчеризации PyTorch, не относящегося к инфраструктуре, который torch.compile не поддерживал. Минимальные воспроизводимые скрипты подтвердили, что эта проблема проявлялась конкретно в классе тренера. Проблемным компонентом оказался менеджер контекста, используемый для подсчета FLOPs, включенный по умолчанию. Отключение этого менеджера контекста решило проблему с torch.compile, восстановив CompiledFunctions. Однако это исправление не улучшило сквозную пропускную способность.Внимание переключилось обратно на аспекты загрузки данных и распределенного обучения, исключив Ray.data в качестве причины, наблюдая те же проблемы с пропускной способностью GPU roofline даже при запуске как нативное приложение PyTorch. Несколько наблюдений указывали на прерывистые медленные итерации, эффект отстающего во время синхронизации и своеобразное поведение, когда включение профилировщика Nsight Systems от Nvidia устраняло медлительность. Тестирование на одном GPU подтвердило, что распределенное обучение не было основной причиной. Полное отключение torch.compile в настройках Ray восстановило исходную пропускную способность, предполагая, что разрывы графа в torch.compile были связаны с замедлением.Создание минимальной воспроизводимой модели с обширными разрывами графа привело к наблюдению повторяющихся медленных итераций. Трассировки Nsight Systems показали, что основной поток обучения удерживал Global Interpreter Lock (GIL) во время этих медленных итераций, но это не объясняло всю паузу. Дальнейший анализ с использованием инструмента Linux perf и визуализация трассировок с помощью chrome://tracing выявили подозрительный процесс Python. Этот процесс выполнял дорогостоящие вычисления, в частности, вызов ядра Linux под названием smap_gather_stats, который собирает статистику виртуальной памяти.
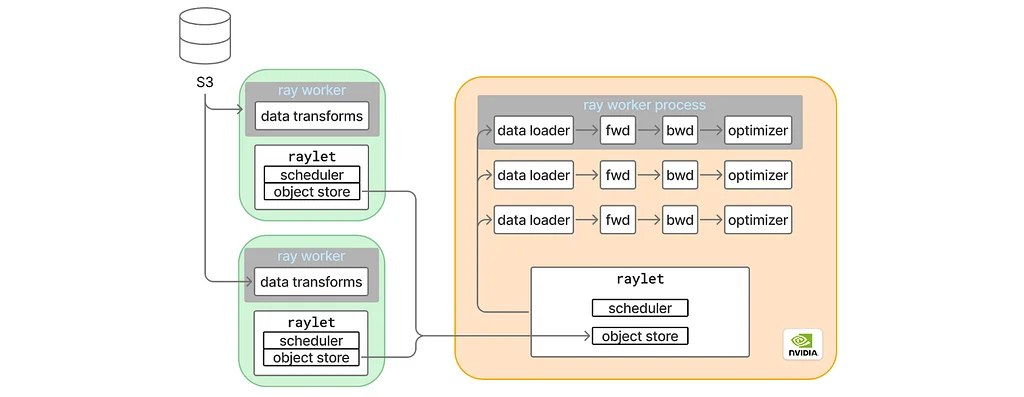
torch.compileвыявило журнал, указывающий на наличие режима диспетчеризации PyTorch, не относящегося к инфраструктуре, которыйtorch.compileне поддерживал. Минимальные воспроизводимые скрипты подтвердили, что эта проблема проявлялась конкретно в классе тренера. Проблемным компонентом оказался менеджер контекста, используемый для подсчета FLOPs, включенный по умолчанию. Отключение этого менеджера контекста решило проблему сtorch.compile, восстановив CompiledFunctions. Однако это исправление не улучшило сквозную пропускную способность.Внимание переключилось обратно на аспекты загрузки данных и распределенного обучения, исключив Ray.data в качестве причины, наблюдая те же проблемы с пропускной способностью GPU roofline даже при запуске как нативное приложение PyTorch. Несколько наблюдений указывали на прерывистые медленные итерации, эффект отстающего во время синхронизации и своеобразное поведение, когда включение профилировщика Nsight Systems от Nvidia устраняло медлительность. Тестирование на одном GPU подтвердило, что распределенное обучение не было основной причиной. Полное отключениеtorch.compileв настройках Ray восстановило исходную пропускную способность, предполагая, что разрывы графа вtorch.compileбыли связаны с замедлением.Создание минимальной воспроизводимой модели с обширными разрывами графа привело к наблюдению повторяющихся медленных итераций. Трассировки Nsight Systems показали, что основной поток обучения удерживал Global Interpreter Lock (GIL) во время этих медленных итераций, но это не объясняло всю паузу. Дальнейший анализ с использованием инструмента Linuxperfи визуализация трассировок с помощьюchrome://tracingвыявили подозрительный процесс Python. Этот процесс выполнял дорогостоящие вычисления, в частности, вызов ядра Linux под названиемsmap_gather_stats, который собирает статистику виртуальной памяти.