RSS Блог о Kubernetes Подписаться
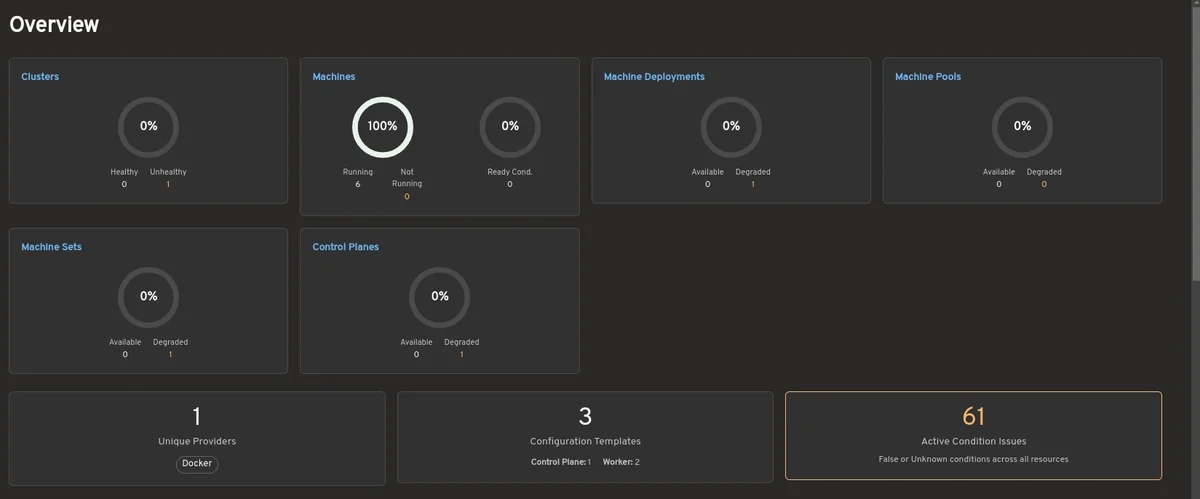
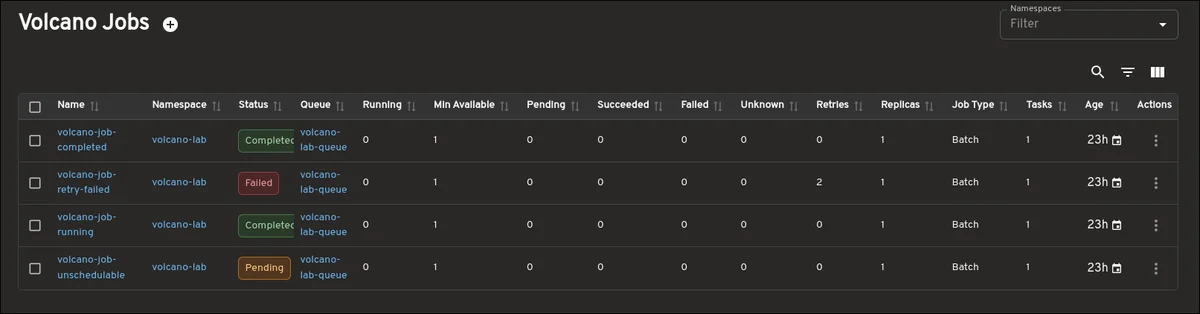
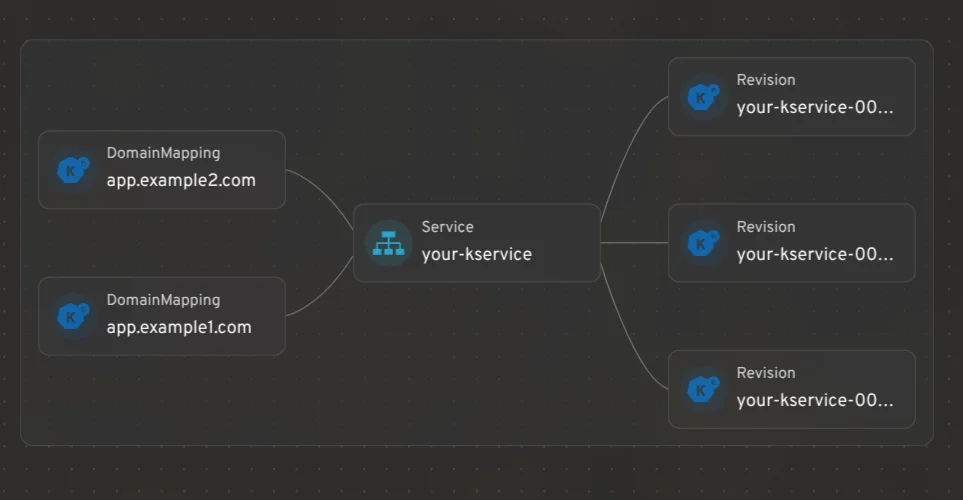
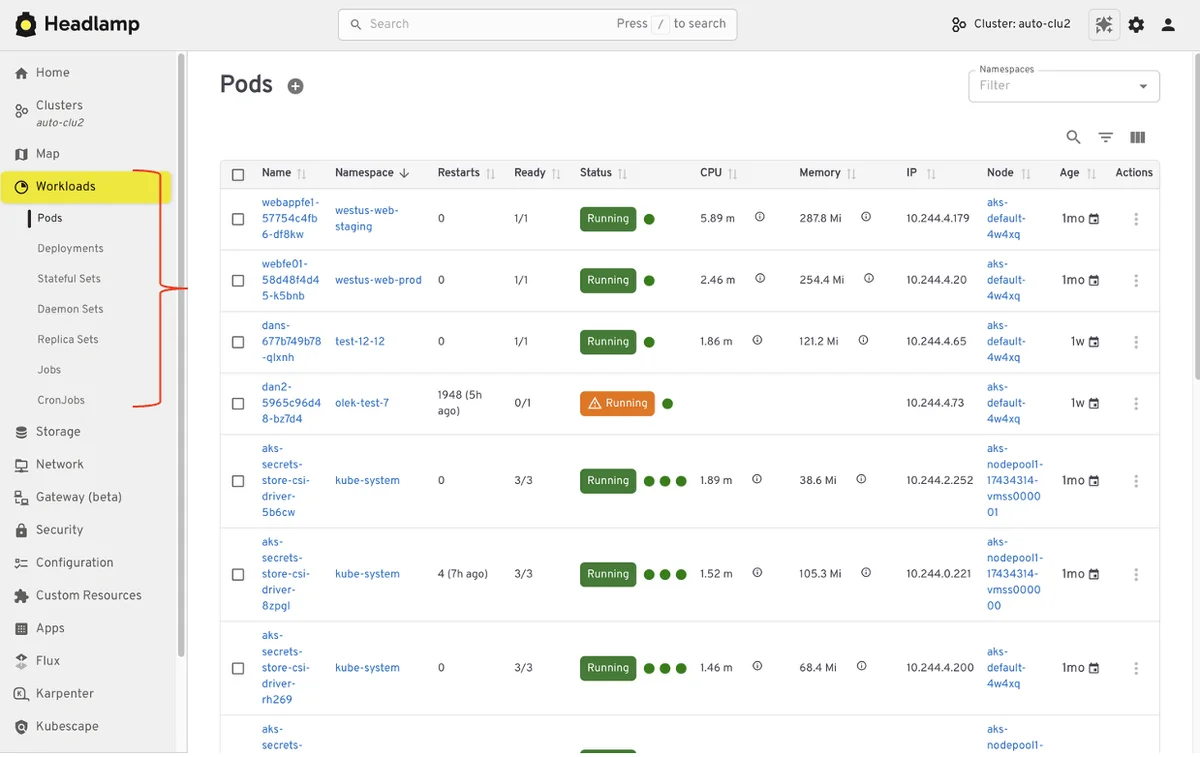
Официальная домашняя страница Kubernetes, системы оркестровки контейнеров для автоматизации развертывания, масштабирования и управления контейнерными приложениями. На этой платформе представлена исчерпывающая документация по Kubernetes, проекту, поддерживаемому Cloud Native Computing Foundation. Она включает в себя подробную информацию о запуске приложений без состояния и с состоянием, пакетных заданиях и рабочих процессах CI/CD с использованием Kubernetes. Сайт содержит подробные руководства, учебники, справочные материалы, документацию по API и инициативы по вовлечению сообщества, чтобы помочь пользователям начать работу с Kubernetes и эффективно использовать его возможности для управления облачными приложениями.