RSS Блог Google AI
Подписаться
Синтетические и федеративные: адаптация доменов с сохранением конфиденциальности с использованием больших языковых моделей для мобильных приложений
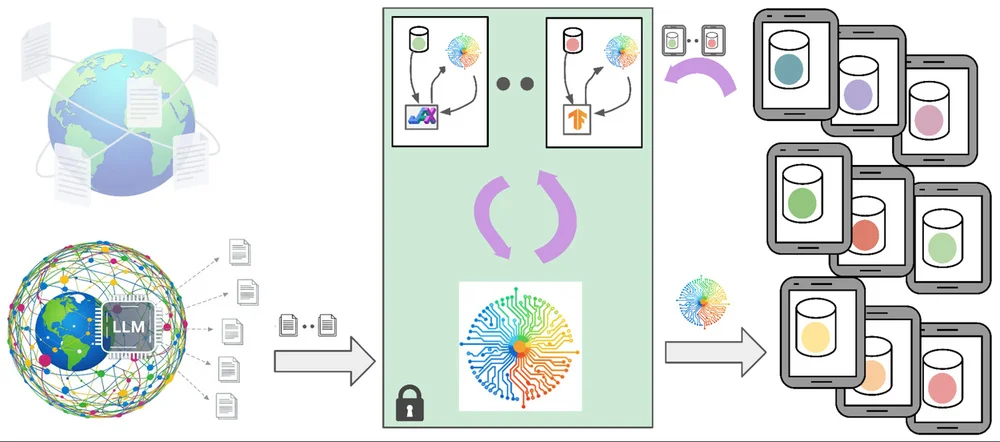
"Gboard от Google использует большие и малые языковые модели (LLM и LM) для таких функций, как предсказание ввода текста и корректура. Обучение этих моделей требует высококачественных данных, но использование пользовательских данных вызывает опасения по поводу конфиденциальности. Для решения этой проблемы Gboard использует синтетические данные, сгенерированные LLM, обученными на общедоступных данных, имитируя взаимодействие пользователя без раскрытия личной информации. Эти синтетические данные предварительно обучают модели, улучшая их производительность перед дальнейшим обучением с использованием методов, сохраняющих конфиденциальность, таких как федеративное обучение и дифференциальная приватность. Такой подход минимизирует риски для конфиденциальности, одновременно значительно повышая точность моделей, что приводит к улучшениям функций Gboard. Процесс включает в себя подсказки LLM для генерации реалистичных данных о вводе текста на мобильных устройствах, которые затем используются для предварительного обучения меньших моделей. "Бутстресс-модуль" — небольшая модель, обученная на пользовательских данных с дифференциальной приватностью, — дополнительно дорабатывает синтетические данные для лучшей адаптации к предметной области. Этот комбинированный подход улучшает как малые, так и большие модели, повышая функциональность Gboard при сохранении конфиденциальности пользователей. Система включает в себя несколько мер защиты конфиденциальности, включая минимизацию данных и анонимизацию. Текущие исследования направлены на улучшение генерации и применения синтетических данных, сохраняющих конфиденциальность, для еще более высокой производительности моделей и улучшения взаимодействия с пользователем."