RSS Блог Google AI
Подписаться
Тонкая настройка больших языковых моделей с использованием дифференциальной приватности на уровне пользователя
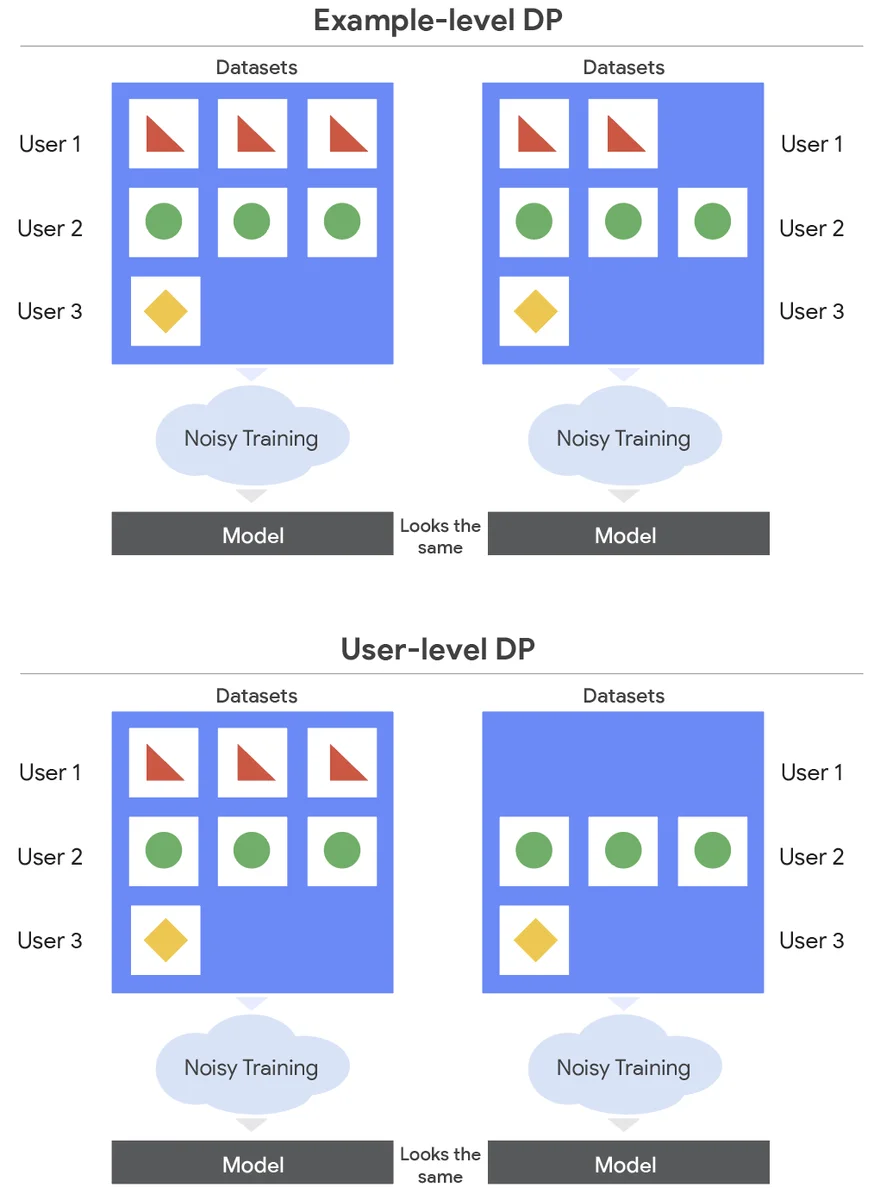
Модели машинного обучения требуют тонкой настройки на специфических для предметной области данных, но это может быть проблематично из-за проблем конфиденциальности. Дифференциальная приватность (DP) позволяет обучать модели, соблюдая конфиденциальность, но большинство работ сосредоточено на DP на уровне примеров, что имеет недостатки. DP на уровне пользователей - более сильная форма приватности, которая гарантирует, что злоумышленник не сможет узнать о данных пользователя, и она используется в федеративном обучении. Обучение с DP на уровне пользователей сложнее и требует добавления большего шума, который ухудшается с увеличением размера моделей. В статье основное внимание уделяется тонкой настройке больших языковых моделей с DP на уровне пользователей в обучении в датацентре. Авторы модифицируют стохастический градиентный спуск (SGD), чтобы добавить шум и ограничить влияние каждого пользователя на модель. Они сравнивают два метода: Example-Level Sampling (ELS) и User-Level Sampling (ULS), которые различаются способом выборки данных. Авторы оптимизируют эти алгоритмы для больших языковых моделей, обнаружив, что ULS в целом лучше, и оба метода работают лучше, чем без тонкой настройки, несмотря на строгое требование приватности. Оптимизации позволяют тренерам моделей выполнять тонкую настройку своих моделей на конфиденциальных наборах данных, обеспечивая при этом надежную защиту пользователей.