RSS Google KI-Blog
Folgen
Erreichen einer 10.000-fachen Reduzierung der Trainingsdaten bei gleichzeitiger Beibehaltung hochqualitativer Labels
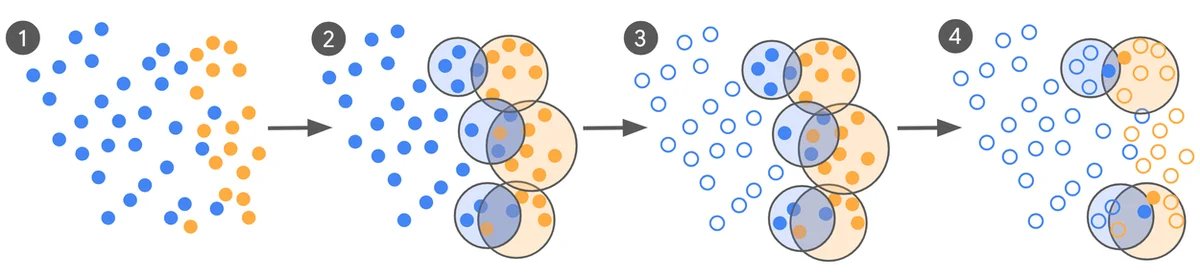
Die Klassifizierung unsicherer Anzeigeninhalte ist eine komplexe Aufgabe, für die große Sprachmodelle (LLMs) aufgrund ihres kontextbezogenen Verständnisses gut geeignet sind. Das Fine-Tuning von LLMs für solche Aufgaben erfordert jedoch hochwertige, groß angelegte Trainingsdaten, deren Zusammenstellung teuer und zeitaufwändig ist. Concept Drift, bei dem sich Sicherheitsrichtlinien ändern, erfordert ein häufiges Neutraining, was die Kosten erhöht. Um dies zu adressieren, reduziert ein neuer Prozess zur Kuratierung durch aktives Lernen die benötigte Menge an Trainingsdaten drastisch und verbessert gleichzeitig die Ausrichtung des Modells auf menschliche Experten. Dieser Prozess identifiziert die wertvollsten Beispiele für die Annotation und reduziert somit erheblich den Datenbedarf. Experimente zeigten eine Reduzierung der Trainingsdaten von 100.000 auf unter 500 Beispiele, wobei sich die Ausrichtung des Modells um bis zu 65 % verbesserte. Der Kuratierungsprozess beginnt mit einem Zero-Shot-LLM, das Daten labelt, gefolgt von Clustering, um verwechselbare Beispiele zu identifizieren. Diese informativen und vielfältigen Beispiele werden dann an menschliche Experten zur Kennzeichnung gesendet. Expertenlabels werden verwendet, um die Modelle iterativ sowohl zu bewerten als auch feinabzustimmen. Der Prozess stützt sich auf Cohen's Kappa, um die Ausrichtung zu messen, da Ground-Truth-Labels oft mehrdeutig sind. Baseline-Modelle, die auf großen crowdsourced Datensätzen feinabgestimmt wurden, schnitten im Vergleich zu kuratierten Modellen weniger gut ab. Die neue Methode zeigt, dass die sorgfältige Kuratierung weniger, aber informativerer Beispiele zu signifikanten Leistungssteigerungen bei drastisch weniger Daten führen kann. Dieser Ansatz ist besonders vorteilhaft für Domänen wie die Anzeigensicherheit mit sich schnell entwickelnden Inhalten.