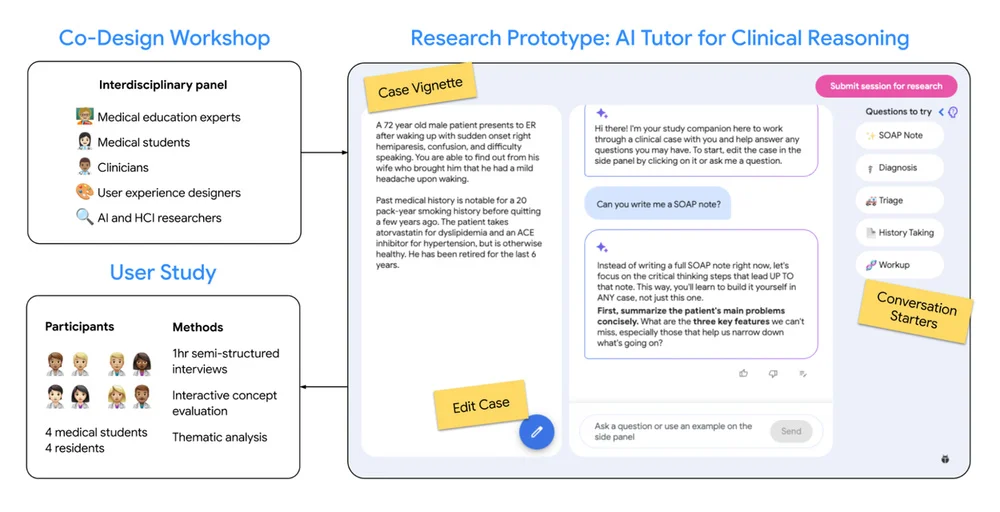
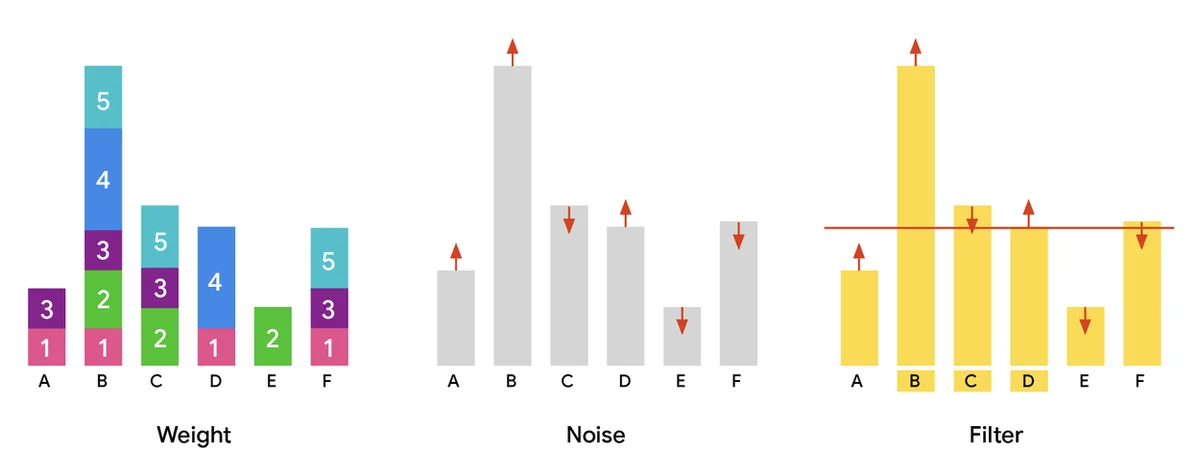
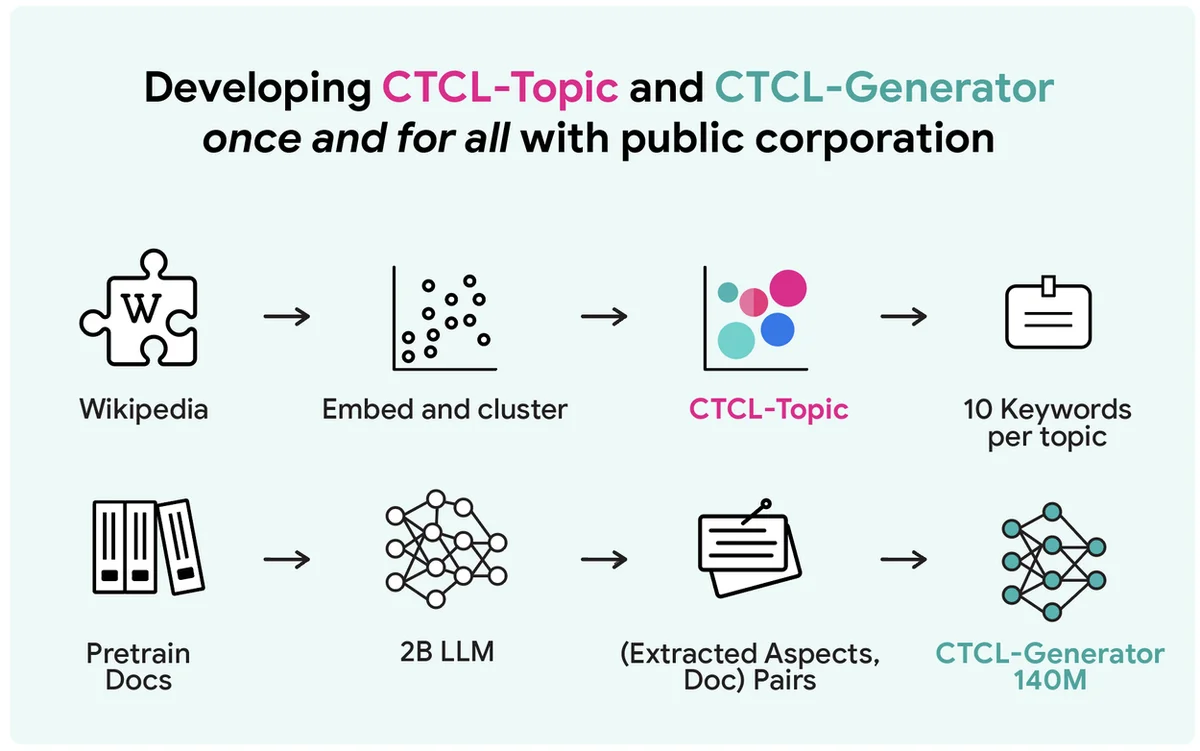
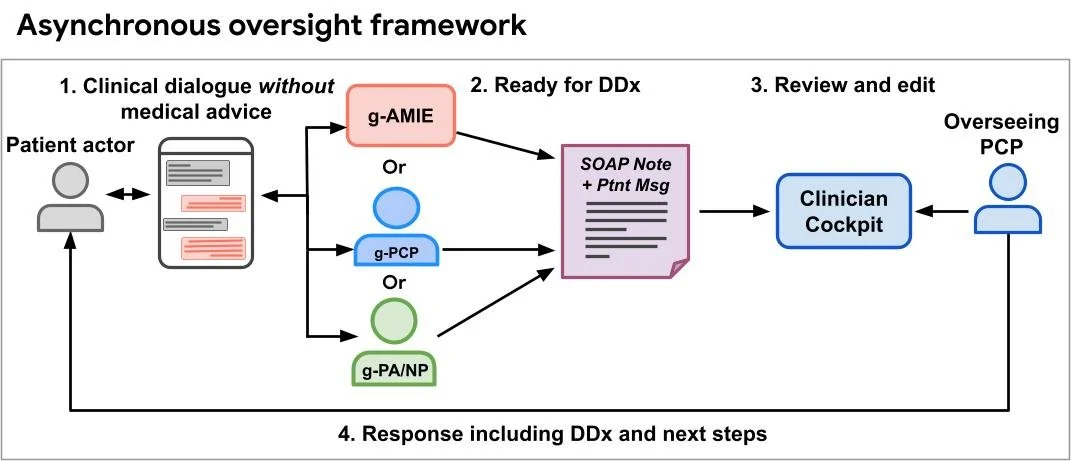
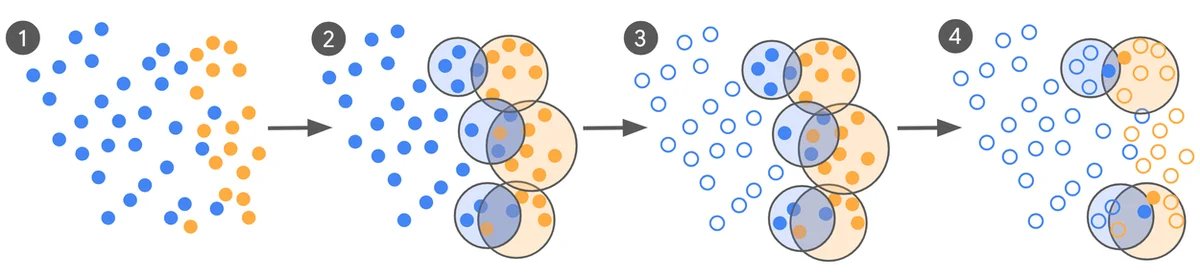
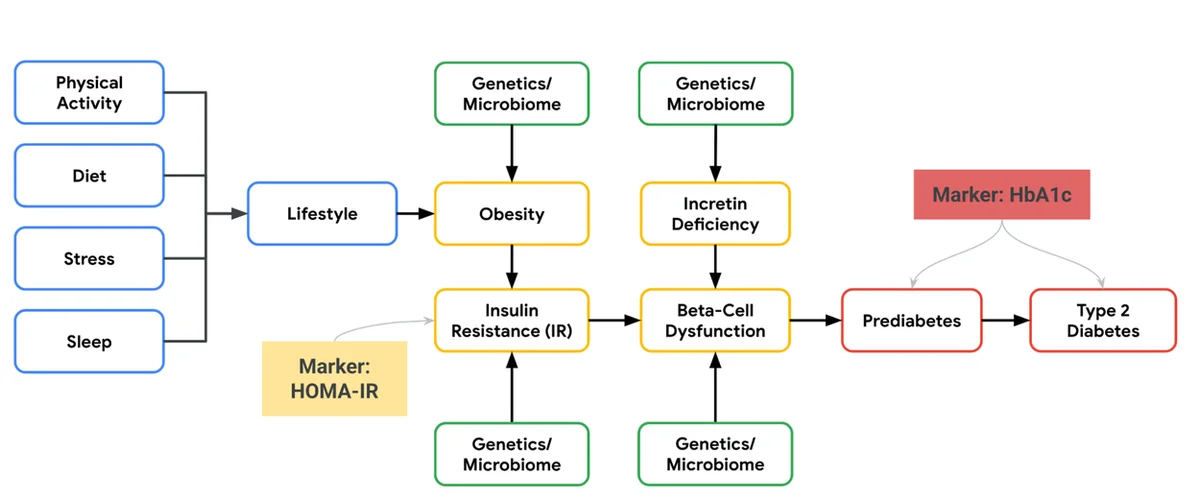
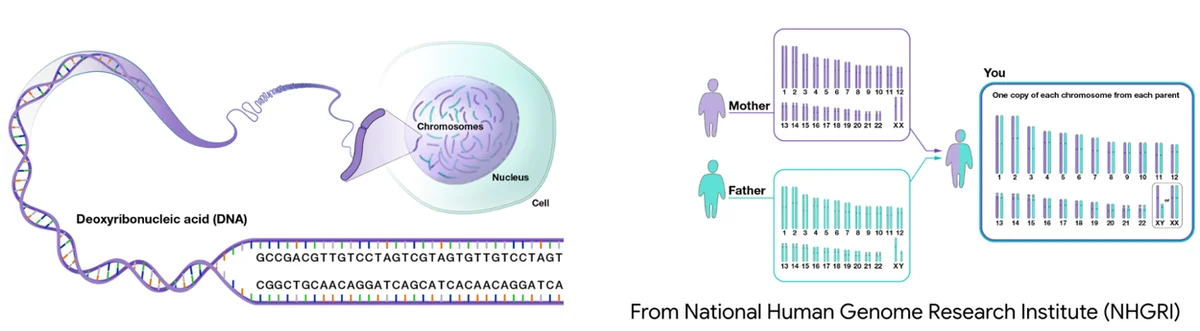
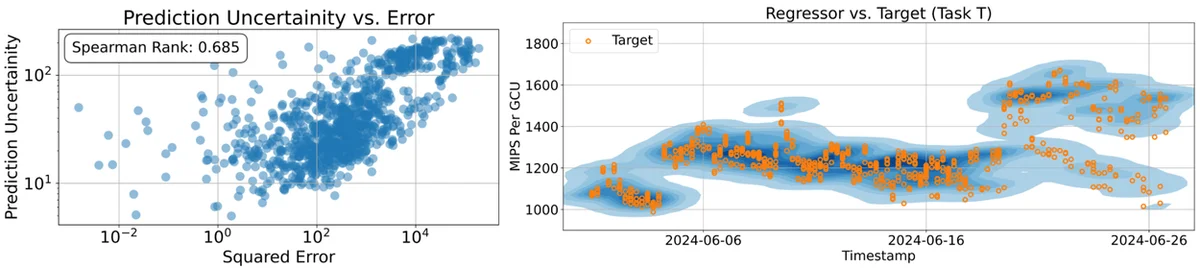
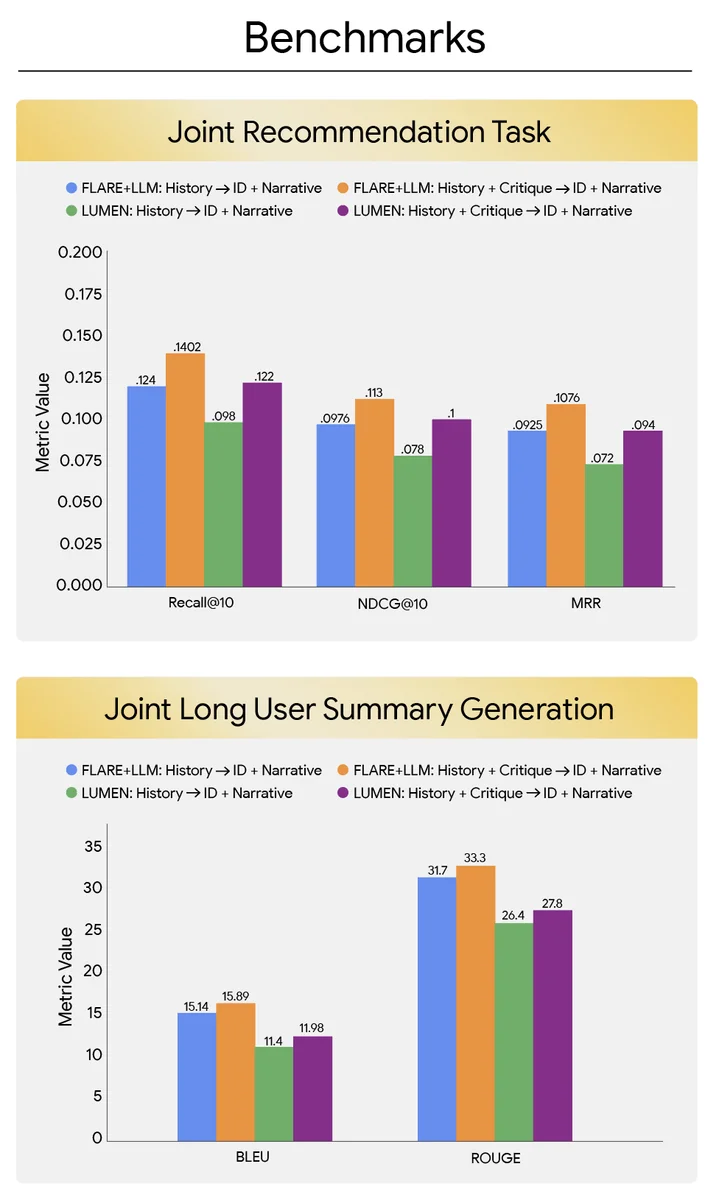
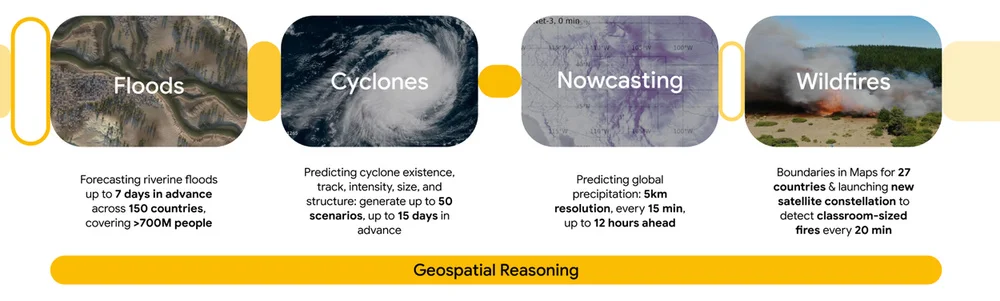
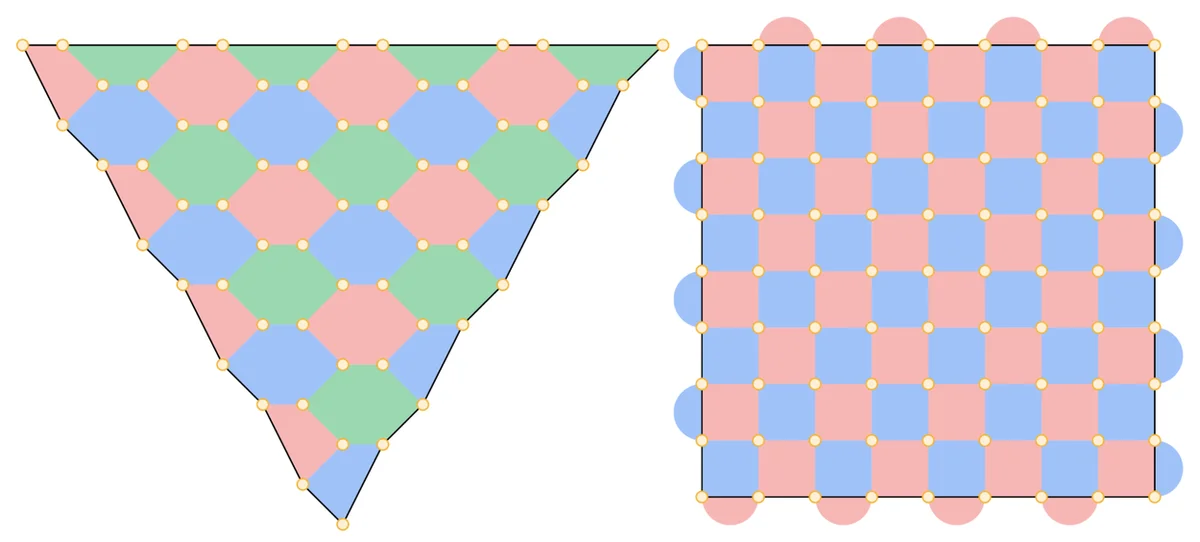
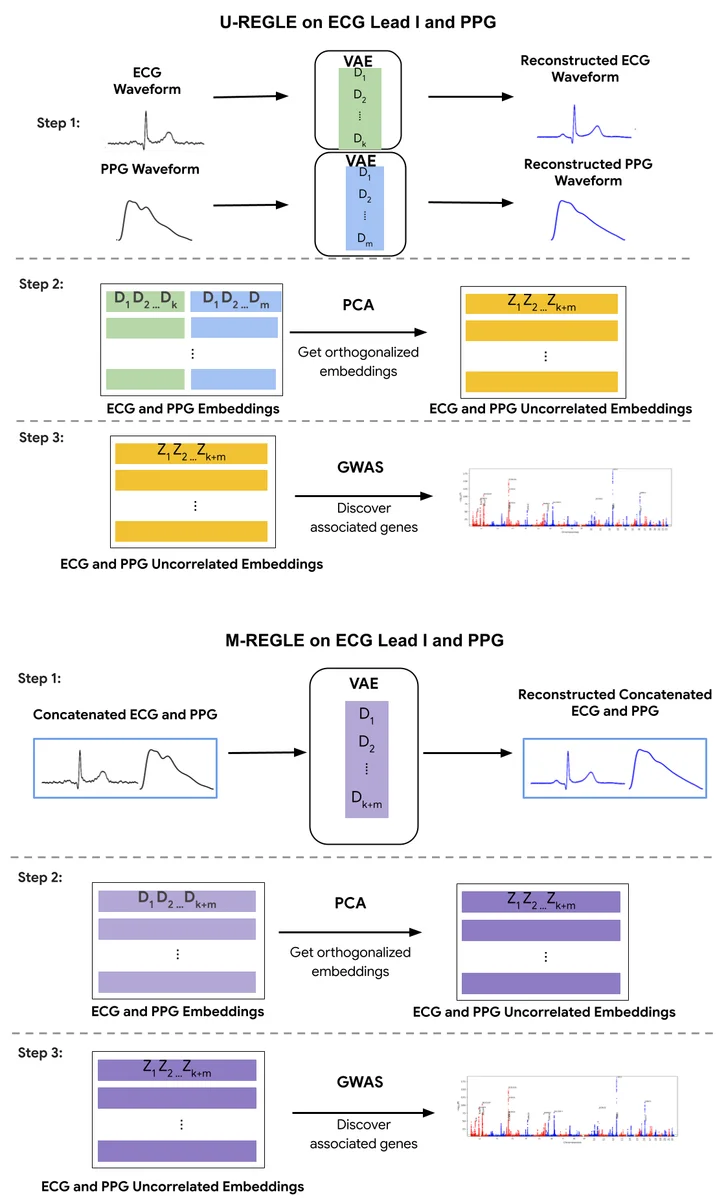
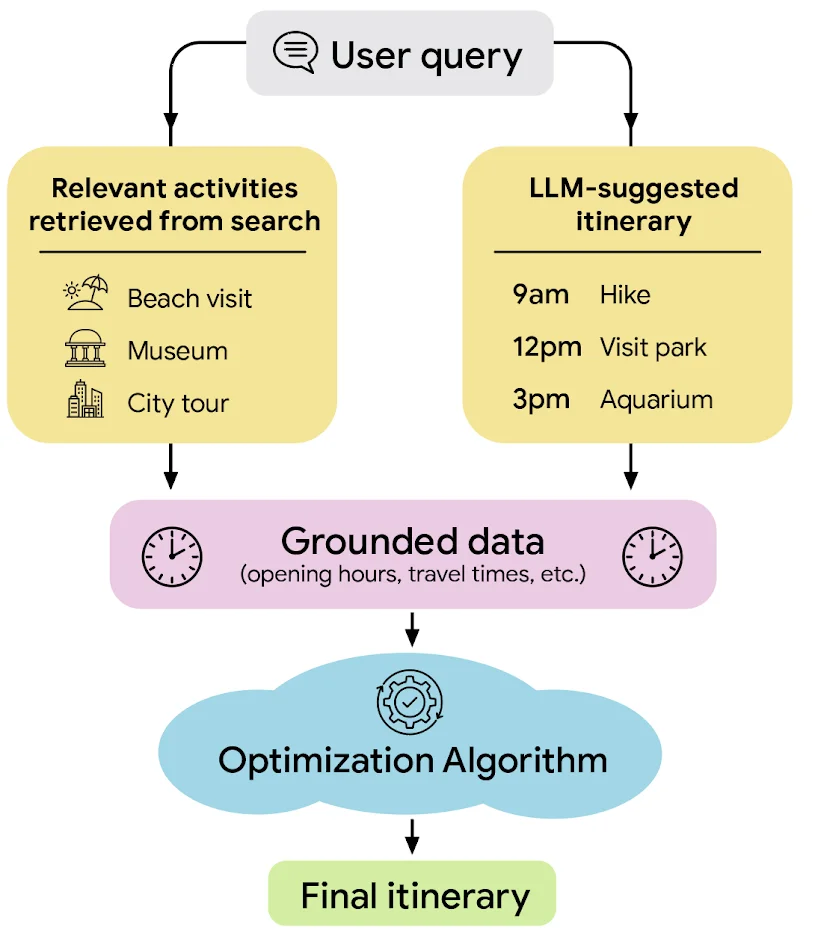
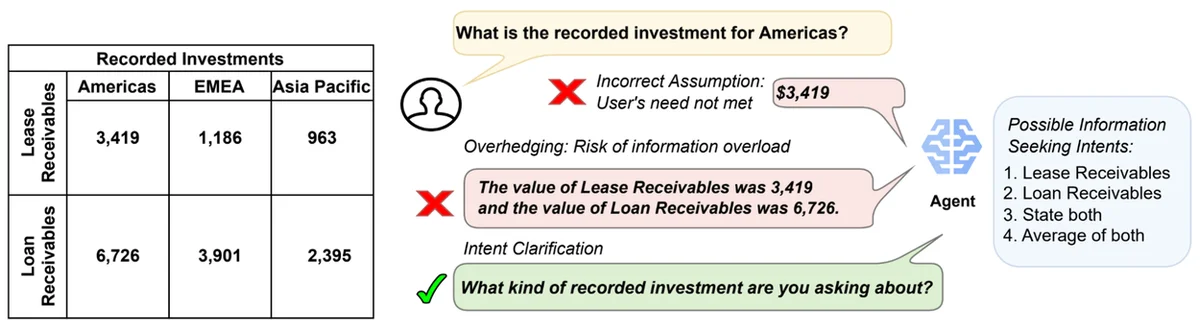
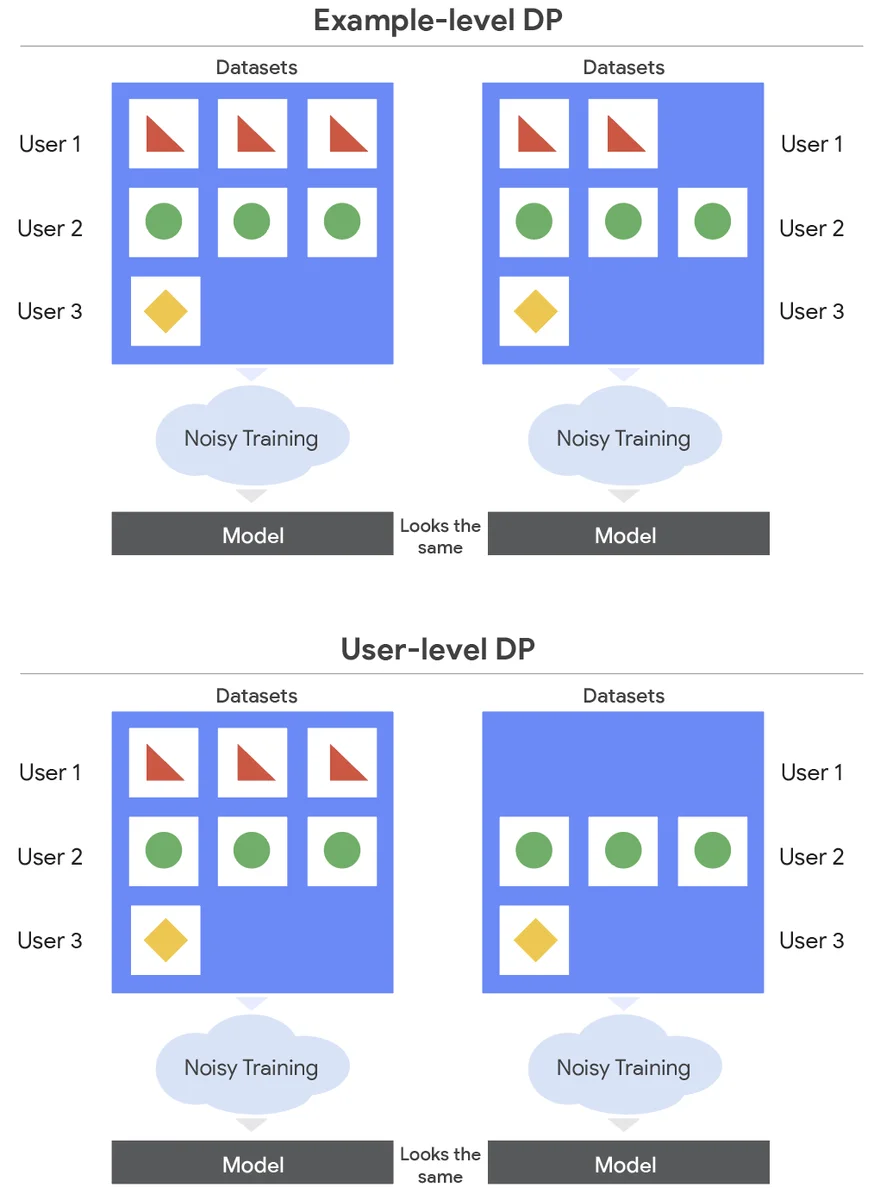
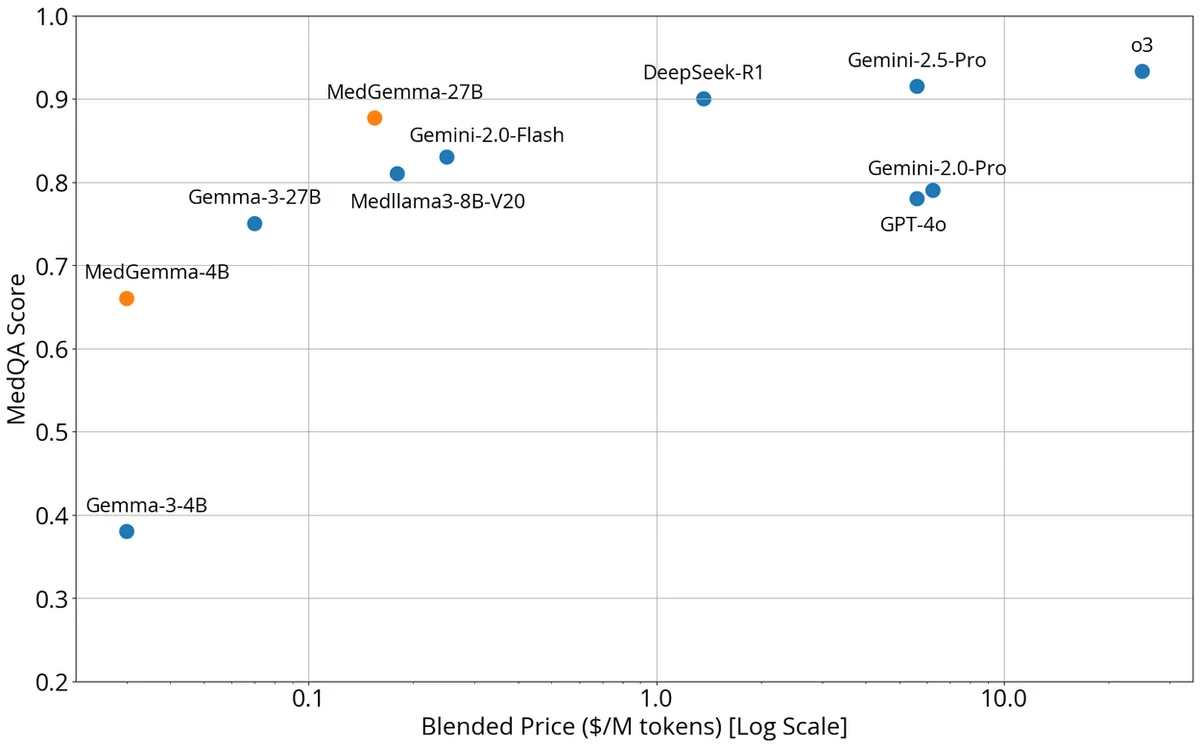
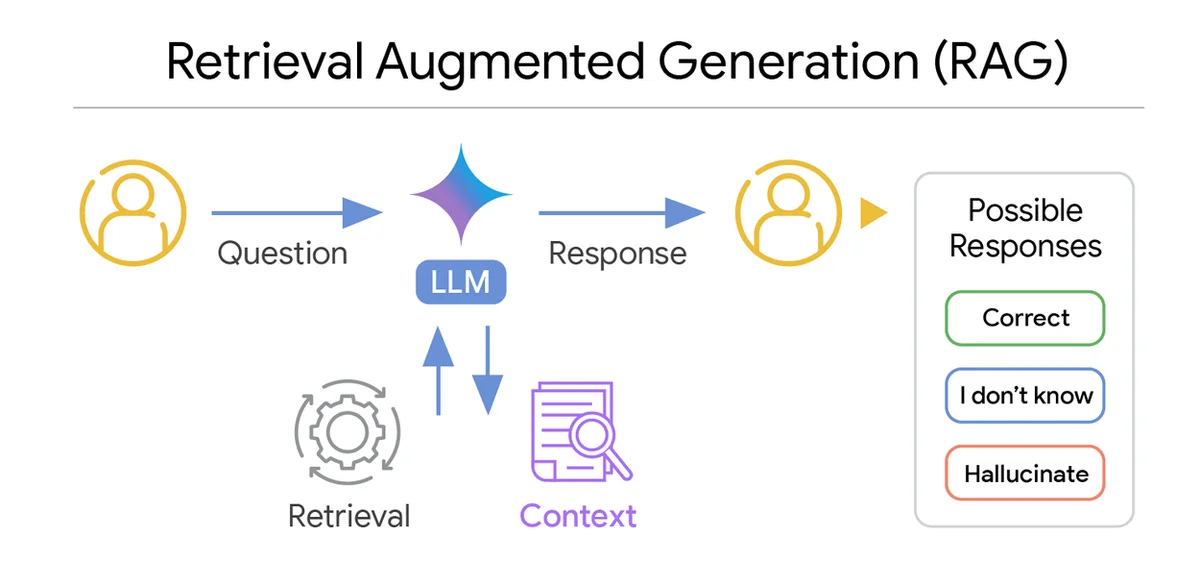
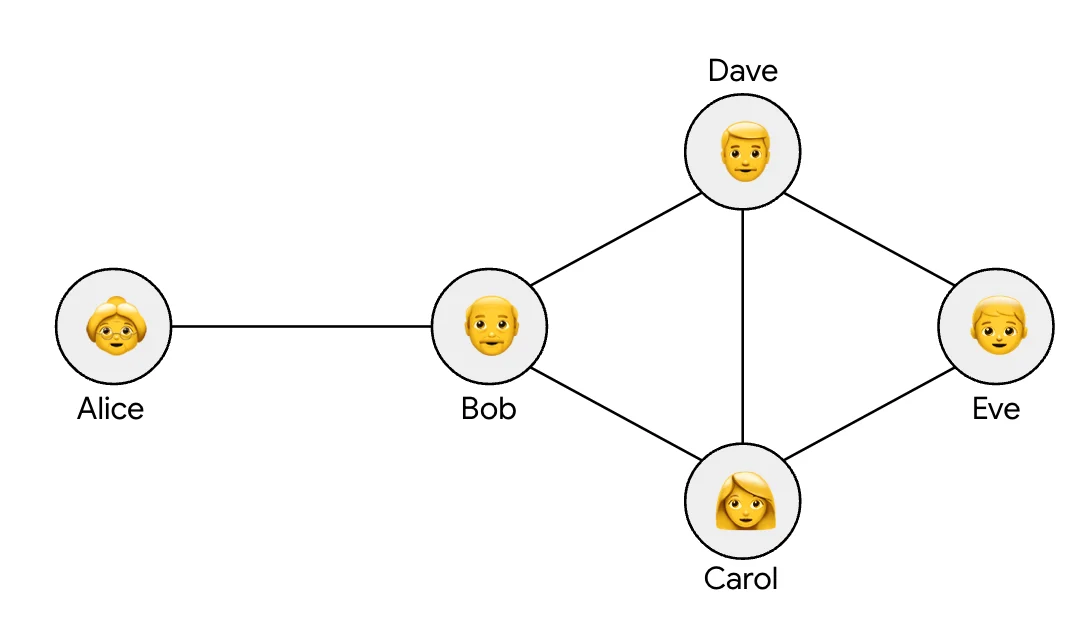
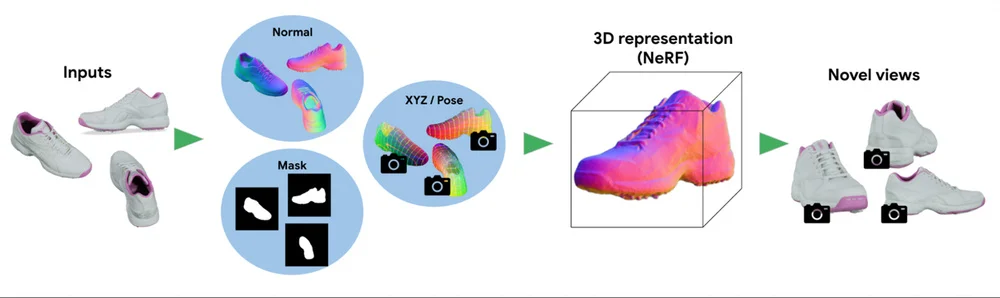
RSS Google KI-Blog Folgen
Google Research ist ein Blog, der sich zum Ziel gesetzt hat, die neuesten Innovationen und Erkenntnisse der wissenschaftlichen Gemeinschaft von Google Research mit dem breiten Publikum zu teilen. Diese Plattform dient als Mittel für Forscher, um sich mit Nutzern außerhalb wissenschaftlicher Kreise zu engagieren und über neue und vielversprechende Technologien, Erkenntnisse und Innovationen zu diskutieren.Google Research veröffentlicht regelmäßig Beiträge zu verschiedenen wissenschaftlichen Themen, von künstlicher Intelligenz und Machine Learning bis hin zu Innovationen im Gesundheitswesen. Es geht auch oft auf neue Technologien ein, von selbstfahrenden Autos bis hin zu innovativen medizinischen Diagnose- und Datenanalysetechniken.Ein bemerkenswertes Merkmal des Blogs ist die Mitarbeit von Teammitgliedern. Viele der führenden Technologen und Forscher bei Google verfassen aufschlussreiche Artikel, die ihre vielfältigen Interessen und Fähigkeiten widerspiegeln. Die Webseite bietet die Gelegenheit, erst-hand Accounts der neuesten Fortschritte und Zukunftsvisionen der Technologie-Welt zu lesen.Der Blog enthält ein "Autoren"-Abschnitt, der es Nutzern ermöglicht, Artikel und Erkenntnisse von einzelnen Beiträgern zu lesen. Neben technischen Diskussionen und Innovationen behandelt der Blog auch breitere soziale und philosophische Fragen im Zusammenhang mit neuen Technologien, um Nutzern ein umfassenderes Verständnis davon zu vermitteln, wie Technologie unser tägliches Leben beeinflusst.Insgesamt bietet der Google Research-Blog eine einzigartige Mischung aus technischem Fachwissen, Forschungsergebnissen und gesellschaftlichen Auswirkungen, was ihn zu einer wertvollen Ressource für Technologie-Enthusiasten, Forscher und jeden, der daran interessiert ist, zukünftige Technologien zu verstehen und zu gestalten.