RSS Google KI-Blog
Folgen
Jenseits von Milliarden-Parameter-Belastungen: Daten-Synthese mit einem bedingten Generator erschließen
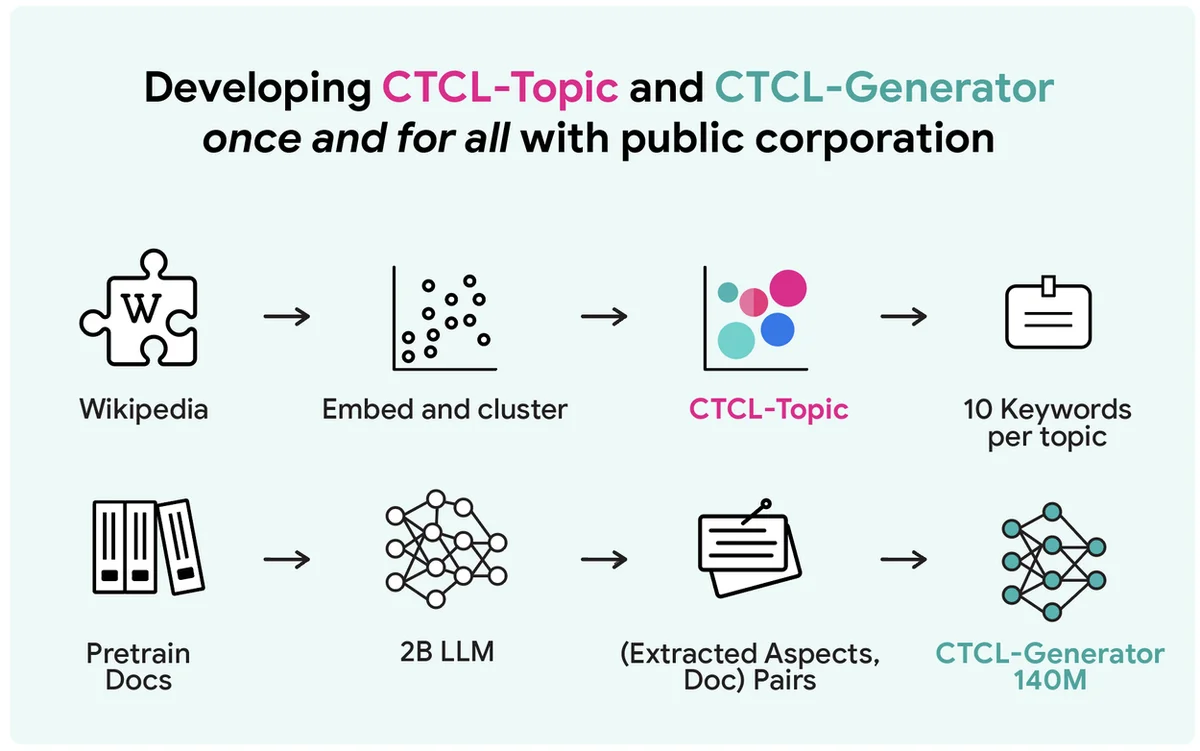
Die Generierung von differenziell privaten synthetischen Textdaten in großem Maßstab steht vor einem Zielkonflikt zwischen Datenschutz, Rechenaufwand und Nützlichkeit. Eine gängige, aber rechenintensive Methode beinhaltet das Fine-Tuning großer Sprachmodelle auf privaten Daten. Bestehende API-basierte Ansätze wie Aug-PE stützen sich auf manuelle Prompts und haben Schwierigkeiten bei der Nutzung privater Informationen. Das vorgeschlagene CTCL-Framework generiert datenschutzfreundliche synthetische Daten, ohne massive LLMs feinzutunen oder aufwändiges Prompt Engineering zu erfordern. Es nutzt ein leichtgewichtiges Modell mit 140 Millionen Parametern, wodurch es für Umgebungen mit begrenzten Ressourcen geeignet ist. CTCL konditioniert die Generierung auf Themeninformationen, um die Verteilungen privater Daten anzupassen. Im Gegensatz zu Aug-PE kann CTCL unbegrenzte synthetische Datenmuster ohne zusätzliche Datenschutz-Kosten erzeugen. Experimente zeigen, dass CTCL die Basislinien übertrifft, insbesondere unter starken Datenschutzgarantien, und demonstriert seine Effektivität bei der Erfassung nützlicher Informationen. Ablationsstudien bestätigen die Bedeutung von Pre-Training und schlüsselwortbasiertem Conditioning für die Leistung und Skalierbarkeit von CTCL. Die Kernidee von CTCL kann auf größere Modelle erweitert werden, um die realen Anwendungen zu verbessern.