RSS Google KI-Blog
Folgen
Feinabstimmung von LLMs mit nutzerseitiger differentieller Privatsphäre
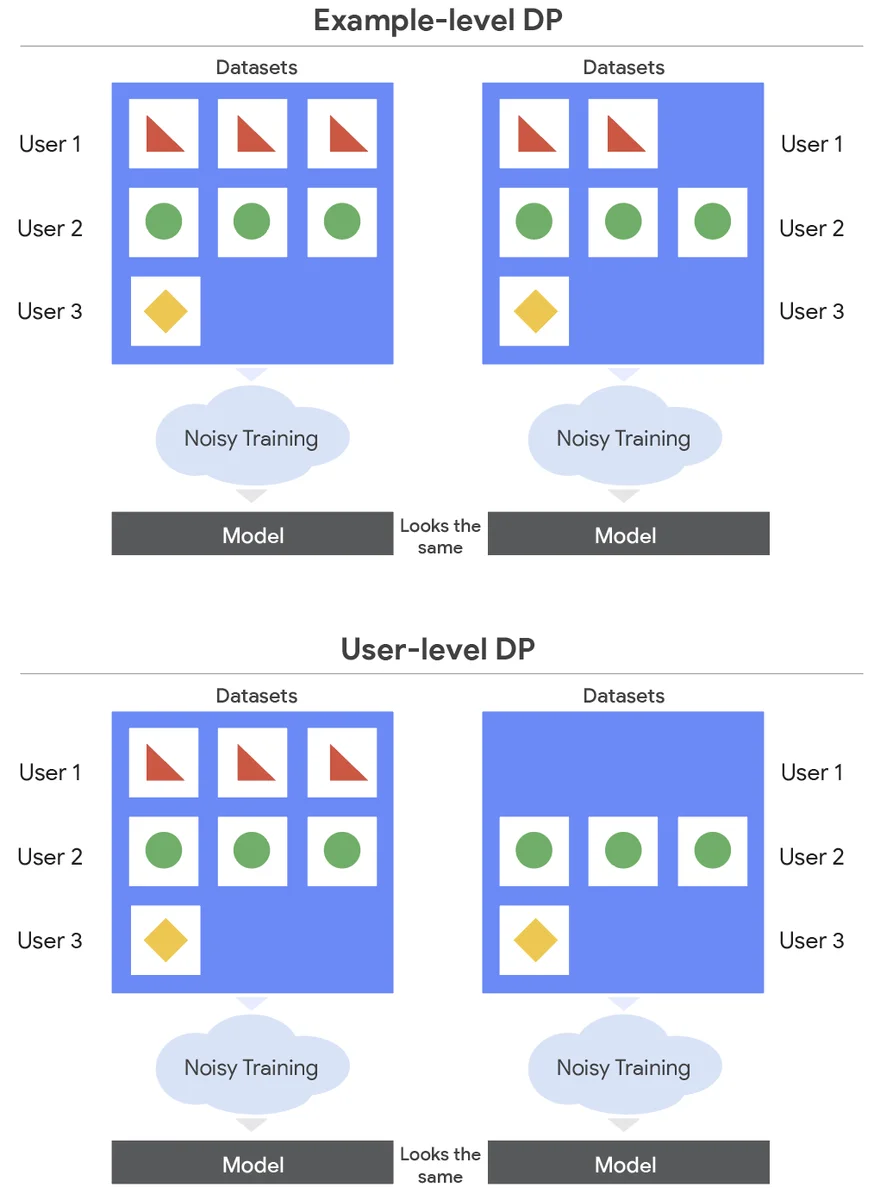
Maschinelles Lernen-Modelle erfordern Feinanpassungen an domänenspezifischen Daten, aber dies kann aufgrund von Datenschutzbedenken problematisch sein. Differenzielle Privatsphäre (DP) ermöglicht das Training von Modellen unter Beachtung der Privatsphäre, aber die meisten Arbeiten konzentrieren sich auf Beispiel-ebene DP, der Nachteile hat. Benutzer-ebene DP ist eine stärkere Form der Privatsphäre, die garantieren kann, dass ein Angreifer keine Informationen über die Daten eines Benutzers erlangen kann, und wird in verteiltem Lernen eingesetzt. Lernen mit Benutzer-ebene DP ist schwieriger und erfordert die Hinzufügung mehr Lärms, der mit größeren Modellen schlechter wird. Der Artikel konzentriert sich auf die Feinanpassung großer Sprachmodelle mit Benutzer-ebene DP im Rechenzentrumstraining. Die Autoren modifizieren den stochastischen Gradientenabstieg (SGD), um Lärm hinzuzufügen und die Auswirkung jedes Benutzers auf das Modell zu begrenzen. Sie vergleichen zwei Methoden, Beispiel-ebene Stichprobenziehung (ELS) und Benutzer-ebene Stichprobenziehung (ULS), die sich in der Art und Weise unterscheiden, wie sie Daten stichproben. Die Autoren optimieren diese Algorithmen für große Sprachmodelle und finden, dass ULS im Allgemeinen besser ist, und beide Methoden besser als kein Feintuning trotz der strengen Datenschutzanforderung ausführen. Die Optimierungen ermöglichen es Modelltrainern, ihre Modelle an sensible Datenbestände anzupassen, während sie starke Benutzerschutzmaßnahmen bereitstellen.