RSS Google KI-Blog
Folgen
Simulation großer Systeme mit Regressions- Sprachmodellen
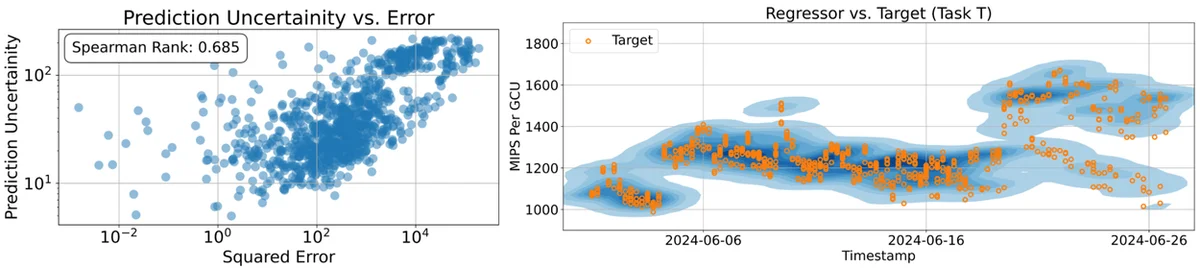
Große Sprachmodelle (LLMs) werden durch das Lernen von menschlichen Präferenzen verbessert, um hilfreichen Text zu generieren. Ein neuartiger Ansatz erweitert dies, indem operationelle Daten verwendet werden, um Belohnungsmodelle für die Vorhersage von Leistungsmetriken zu trainieren. Traditionelle Regression kämpft mit komplexen, unstrukturierten Daten, was aufwendige Feature-Engineering erfordert. Der Artikel führt Regression-Sprachmodelle (RLMs) ein, die Text-zu-Text-Regression durchführen, indem sie Texteingaben direkt in numerische Vorhersagen als Zeichenfolgen verarbeiten. Diese Methode vermeidet Feature-Engineering und ermöglicht eine Anpassung an neue Aufgaben mit wenigen Beispielen. RLMs können Wahrscheinlichkeitsverteilungen von Ergebnissen erfassen und die Vorhersageunsicherheit quantifizieren. Dieser Ansatz wurde angewendet, um die Ressourceneffizienz in Googles großem Recheninfrastruktur Borg vorherzusagen. Das RLM sagte Millionen von Instruktionen pro Sekunde pro Google-RechenEinheit (MIPS pro GCU) effektiv voraus. Dieses neue Paradigma bietet einen skalierbaren und effizienten Weg, um numerische Ergebnisse aus rohem Text vorherzusagen, was universelle System-Simulatoren und fortschrittliche Belohnungsmechanismen ermöglicht.