RSS Google KI-Blog
Folgen
SensorLM: Die Sprache von Wearable-Sensoren lernen
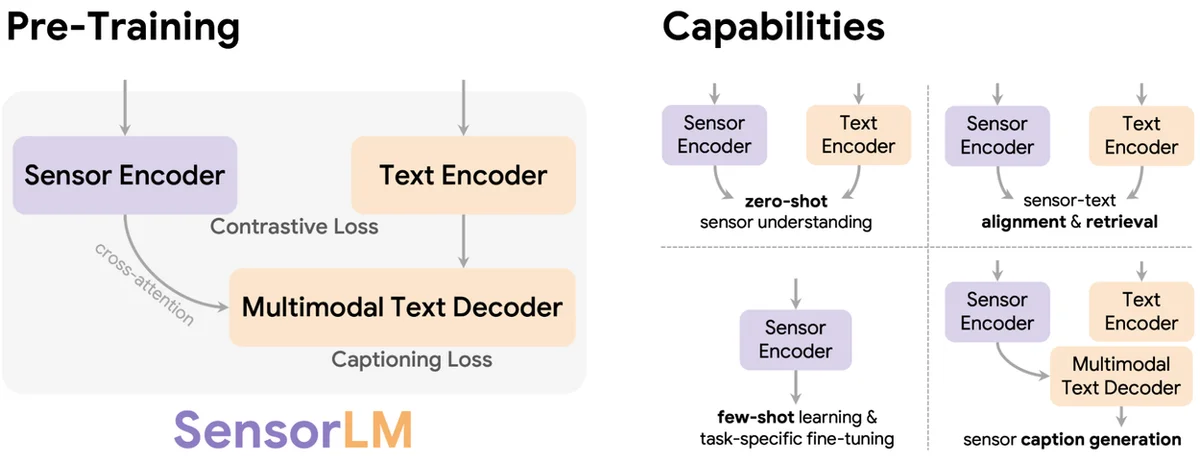
Wearable Geräte sammeln riesige Mengen an persönlichen Gesundheitsdaten, aber das Verständnis des Kontexts hinter diesen Daten war bisher eine Herausforderung. Diese Lücke schränkt das volle Potenzial personalisierter Gesundheitseinblicke ein. Die manuelle Annotation von Sensordaten mit beschreibendem Text ist aufgrund von Kosten und Zeitaufwand unpraktikabel. Um dies zu beheben, wurde SensorLM, eine Familie von Sensor-Sprach-Foundation-Modellen, entwickelt. SensorLM wurde auf beispiellosen 59,7 Millionen Stunden multimodaler Sensordaten von über 103.000 Personen vortrainiert. Dies ermöglicht es ihm, menschenlesbare Beschreibungen von Wearable-Sensordaten zu interpretieren und zu generieren. Eine neuartige hierarchische Pipeline generiert automatisch beschreibende Bildunterschriften und erstellt so den bisher größten Sensor-Sprach-Datensatz. SensorLM bietet Fähigkeiten wie Zero-Shot-Sensorverständnis, Sensor-Text-Abgleich und die Generierung von Sensor-Bildunterschriften. Es zeigt eine Spitzenleistung bei Aufgaben wie der Aktivitätserkennung und zeichnet sich durch die Generierung kohärenter und sachlich korrekter Bildunterschriften aus. Die Leistung des Modells verbessert sich kontinuierlich mit mehr Daten, größeren Modellgrößen und erhöhter Rechenleistung. SensorLM stellt einen bedeutenden Fortschritt dar, um persönliche Gesundheitsdaten verständlich und umsetzbar zu machen und ebnet den Weg für zukünftige digitale Gesundheits-Coaches und Wellness-Anwendungen.