RSS Google KI-Blog
Folgen
Sicherung von privaten Daten in großem Umfang mit differenzialprivater Partitionselektion
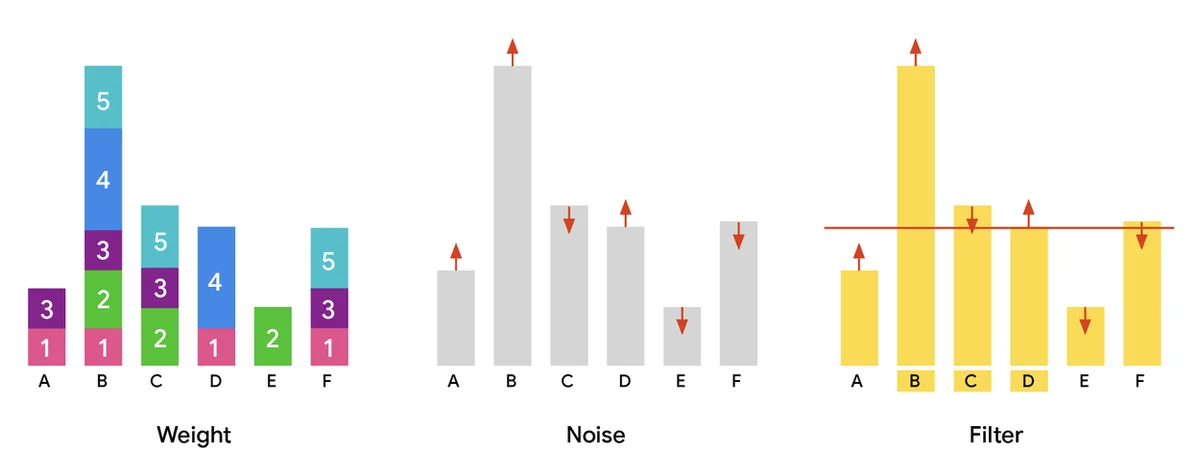
"Große benutzerbasierte Datensätze sind für den Fortschritt der KI, die Verbesserung von Dienstleistungen und die Personalisierung von entscheidender Bedeutung. Das Teilen dieser Datensätze beschleunigt die Forschung, birgt jedoch Datenschutzrisiken. Die differentiell private (DP) Partitionsauswahl identifiziert sichere, gemeinsame Daten-Untermengen, indem sie Rauschen hinzufügt, um individuelle Beiträge zu schützen. Dies ist für Aufgaben wie die Vokabelauswahl und die private Datenanalyse von entscheidender Bedeutung. Die Verarbeitung massiver Datensätze erfordert parallele Algorithmen, nicht nur für die Geschwindigkeit, sondern auch für die Bewältigung enormer Skalen. Unser Beitrag, „Skalierbare private Partitionsauswahl via adaptives Gewichtung“, stellt einen effizienten parallelen Algorithmus für die DP-Partitionsauswahl vor. Dieser Algorithmus skaliert auf Hunderte von Milliarden von Elementen, was die bisherigen Fähigkeiten erheblich übersteigt. Das Ziel ist es, die ausgewählten Elemente zu maximieren, während die Benutzerdatenschutz aufrechterhalten wird, wobei beliebte Daten priorisiert werden. Der Standardansatz umfasst das Gewichten, das Hinzufügen von Rauschen und das Filtern von Elementen basierend auf einem Schwellenwert. Unser neuartiger adaptiver Gewichtungsalgorithmus, MAD, verteilt das "überschüssige Gewicht" von beliebten Elementen auf solche, die knapp unter dem Datenschutzschwellenwert liegen. Dies verbessert die Nützlichkeit, indem mehr Elemente aufgenommen werden, ohne die Datenschutz oder Skalierbarkeit zu beeinträchtigen. Experimente zeigen, dass unser zweistufiger MAD-Algorithmus state-of-the-art-Ergebnisse erzielt, indem er mehr Elemente als andere Methoden mit denselben Datenschutzgarantien ausgibt. Wir stellen unseren Algorithmus als Open-Source bereit, um die Innovation in der Community zu fördern."