RSS Google KI-Blog
Folgen
LLMs genauer machen, indem alle ihre Schichten verwendet werden
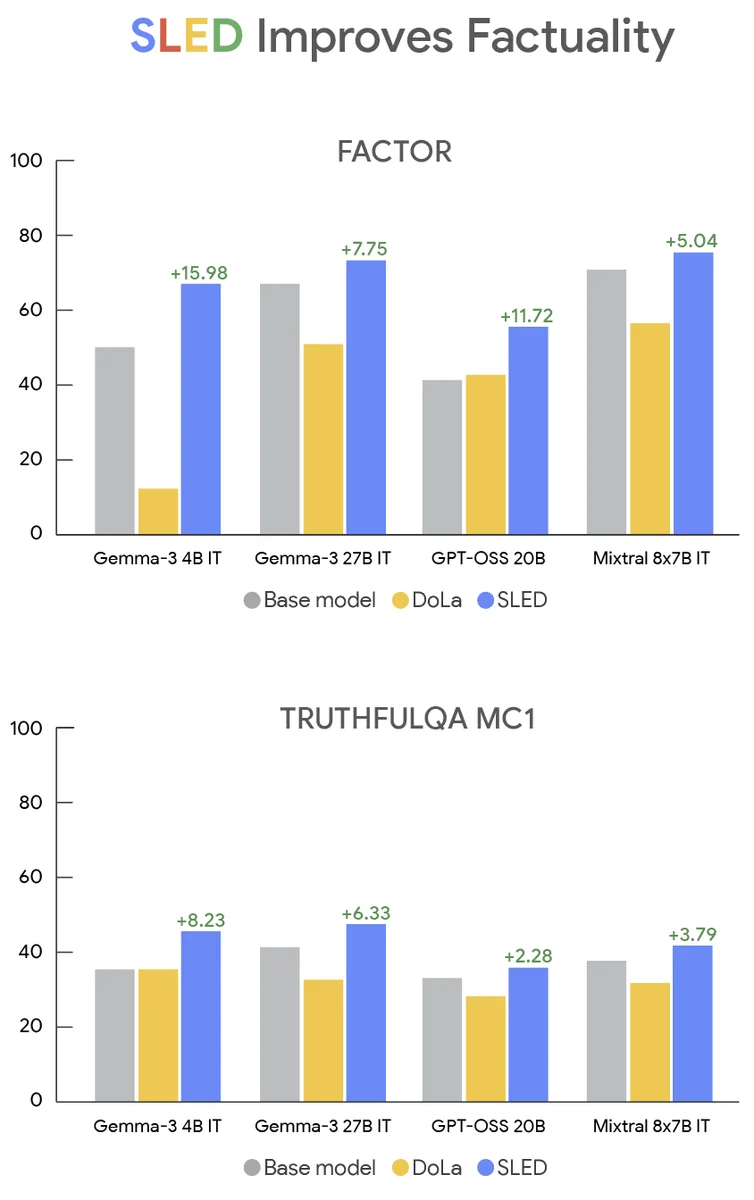
Große Sprachmodelle haben oft Schwierigkeiten mit der Faktenorientierung und halluzinieren manchmal falsche Informationen. Dieses Problem entsteht durch verschiedene Faktoren, darunter verzerrte oder unvollständige Trainingsdaten. Faktenorientierung, die Fähigkeit, wahrheitsgemäße Inhalte zu generieren, ist entscheidend für zuverlässige LLM-Anwendungen. SLED, eine neue Dekodierungsmethode, zielt darauf ab, die Faktenorientierung ohne externe Wissensbasen zu verbessern. SLED nutzt Informationen aus allen Schichten des LLM, nicht nur aus der letzten Schicht, um seine Vorhersagen zu verfeinern. Es berechnet Token-Wahrscheinlichkeiten unter Verwendung früherer Schichten und weist jedem Gewichtungen für eine genauere Ausgabe zu. Experimente mit mehreren Aufgaben und Benchmarks zeigen, dass SLED die faktische Genauigkeit über verschiedene LLMs hinweg verbessert. Beispielsweise kann es Rechenfehler korrigieren oder die richtige Antwort auf eine Multiple-Choice-Frage auswählen. SLED ist einfach zu implementieren, mit verschiedenen LLMs kompatibel und kann mit anderen Methoden kombiniert werden. Sein primärer Kompromiss ist eine minimale Erhöhung der Inferenzzeit im Vergleich zu Alternativen. SLED zeigt state-of-the-art Genauigkeitsverbesserungen, ohne dass eine umfangreiche Feinabstimmung erforderlich ist. Zukünftige Arbeiten könnten die Kombination von SLED mit überwachtem Fine-Tuning und die Anwendung auf andere Aufgaben umfassen.