RSS Google KI-Blog
Folgen
Synthetisch und föderiert: Datenschutzfreundliche Domänenanpassung mit LLMs für mobile Anwendungen
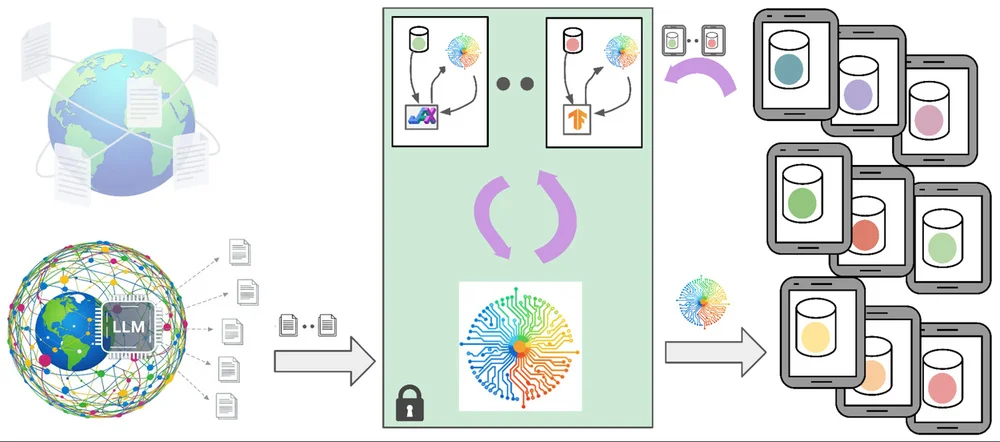
"Googles Gboard verwendet große und kleine Sprachmodelle (LLMs und LMs) für Funktionen wie Tippvorhersage und Rechtschreibprüfung. Das Trainieren dieser Modelle erfordert hochwertige Daten, aber die Verwendung von Benutzerdaten wirft Datenschutzbedenken auf. Um dies anzugehen, setzt Gboard synthetische Daten ein, die von LLMs auf öffentlichen Daten trainiert wurden, um Benutzerinteraktionen nachzuahmen, ohne private Informationen preiszugeben. Diese synthetischen Daten trainieren Modelle vor, verbessern die Leistung vor weiterem Training mit Datenschutz-Techniken wie federiertem Lernen und differentieller Privatsphäre. Dieser Ansatz minimiert Datenschutzrisiken, während er die Modellgenauigkeit signifikant verbessert, was zu Verbesserungen der Gboard-Funktionen führt. Der Prozess umfasst das Auslösen von LLMs, um realistische mobile Tippeingabedaten zu generieren, die dann verwendet werden, um kleinere Modelle vorzutrainieren. Ein "Stützmodul", ein kleines Modell, das auf Benutzerdaten mit differentieller Privatsphäre trainiert wurde, verfeinert die synthetischen Daten für eine bessere Domänenanpassung. Dieser kombinierte Ansatz verbessert sowohl kleine als auch große Modelle, was die Funktionalität von Gboard verbessert, während die Benutzerdatenschutz aufrechterhalten wird. Das System umfasst mehrere Datenschutzsicherungen, einschließlich Datenminimierung und Anonymisierung. Laufende Forschung konzentriert sich auf die Verbesserung der Generierung und Anwendung von Datenschutz-synthetischen Daten für eine noch bessere Modellleistung und eine verbesserte Benutzererfahrung."