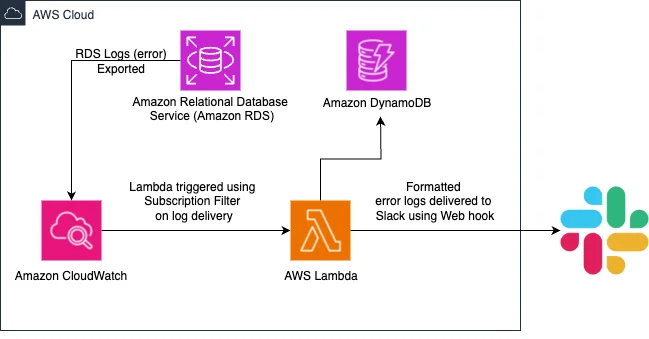
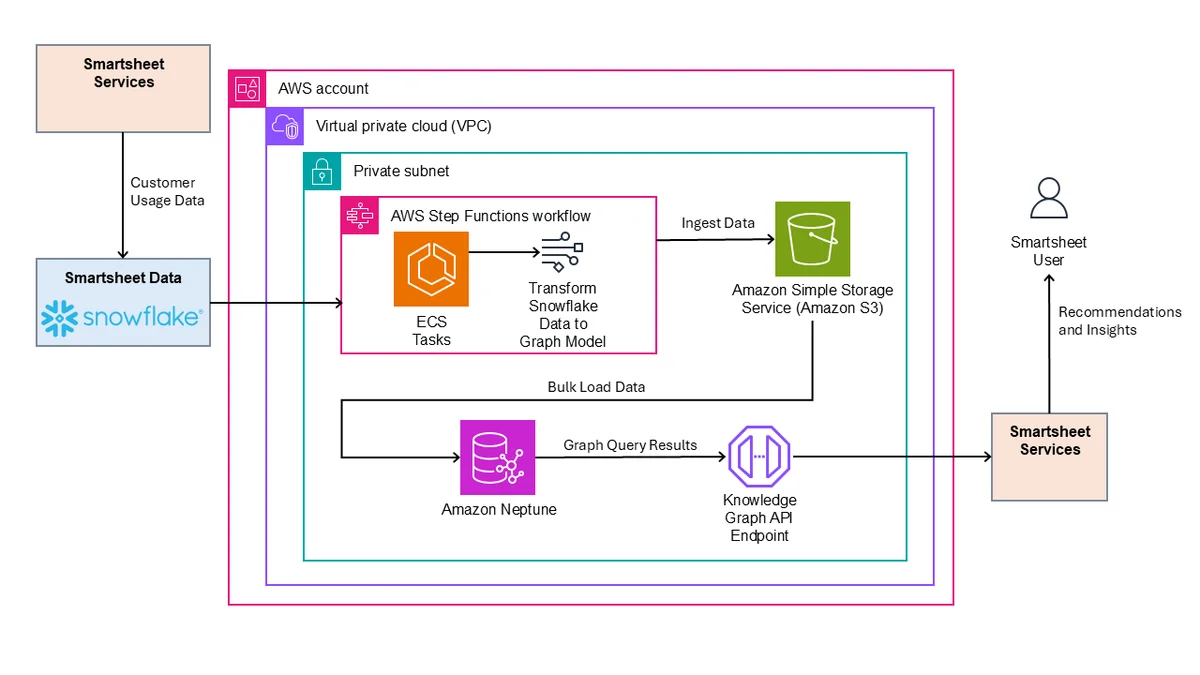
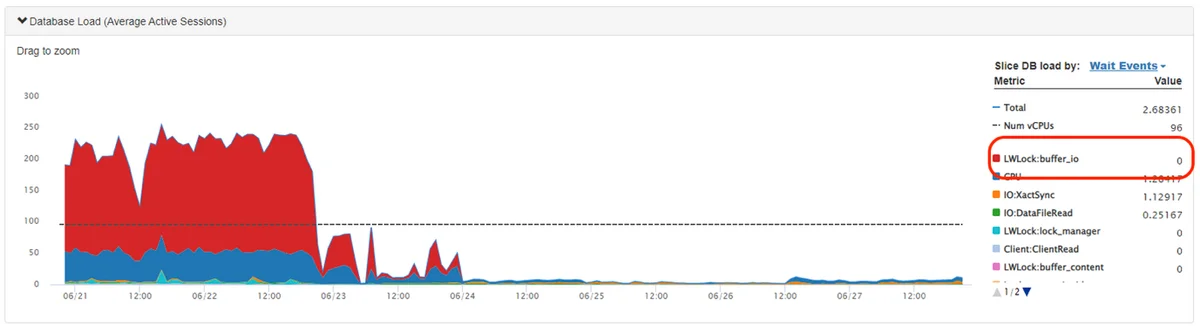
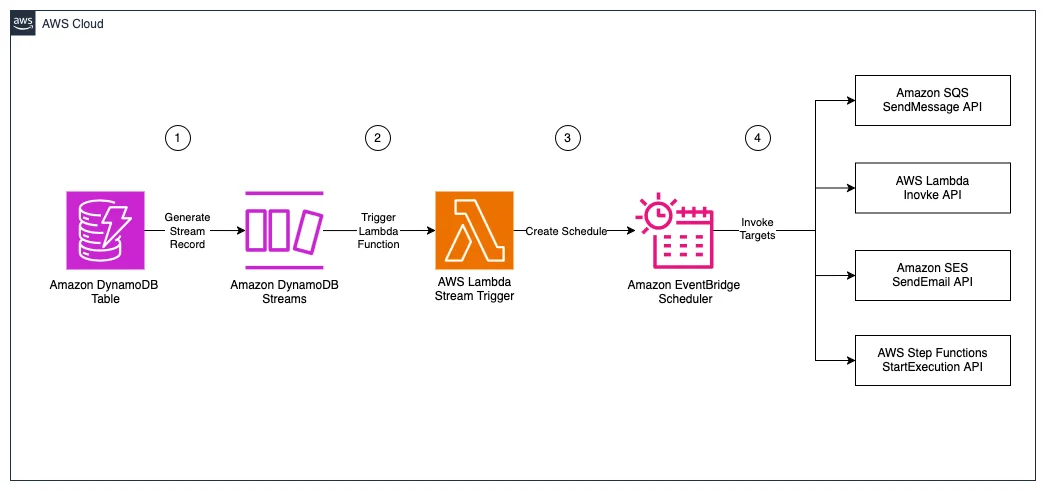
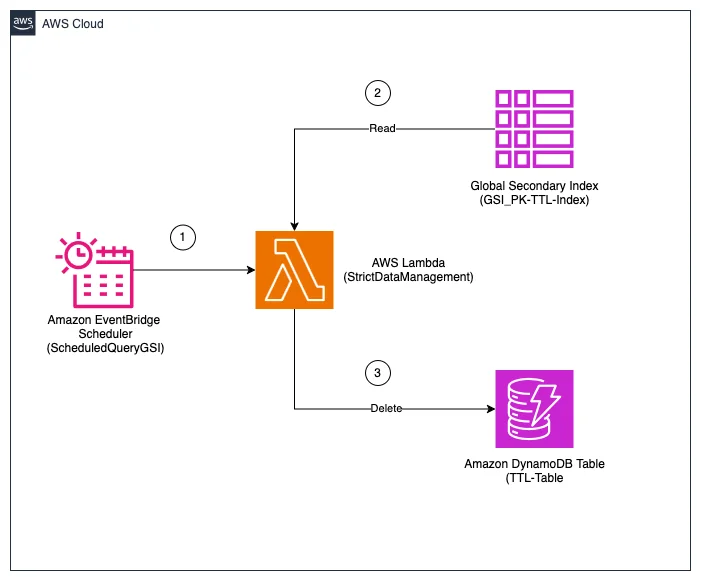
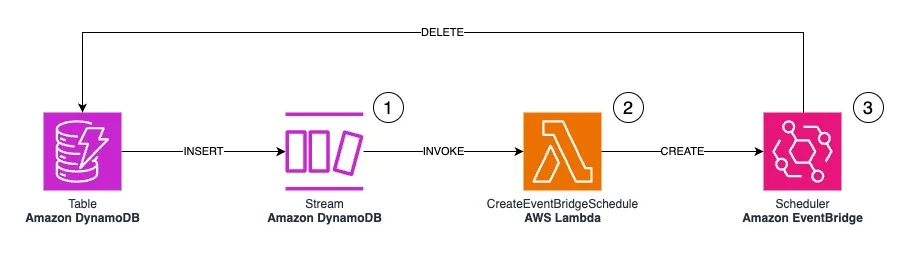
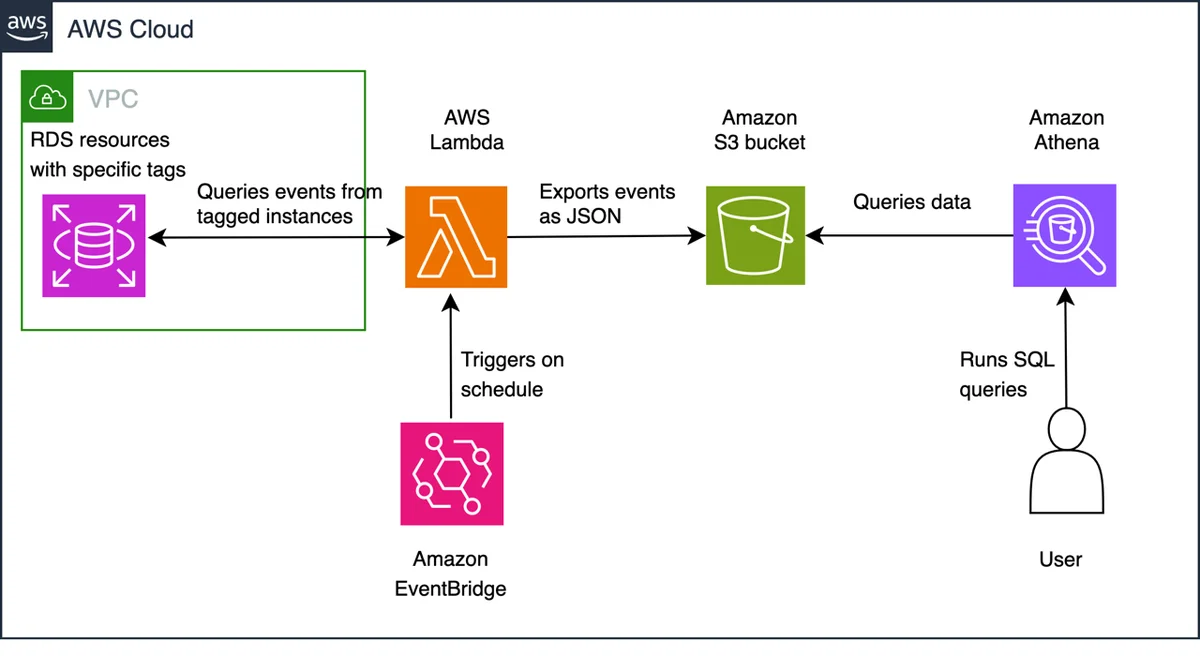
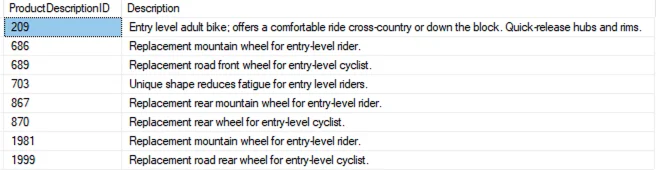
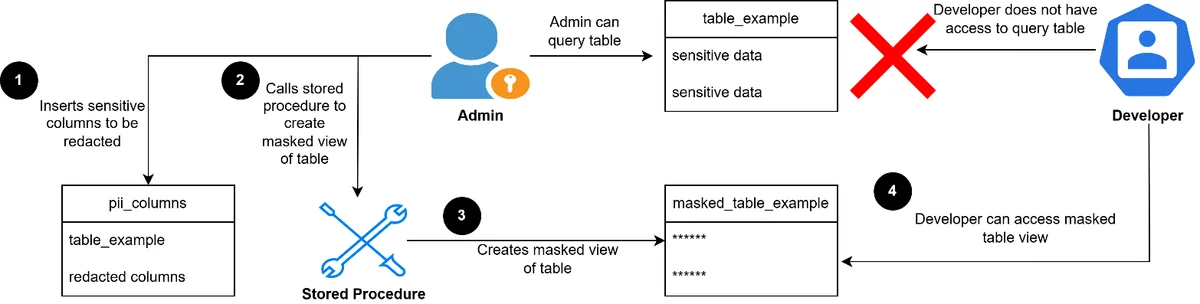
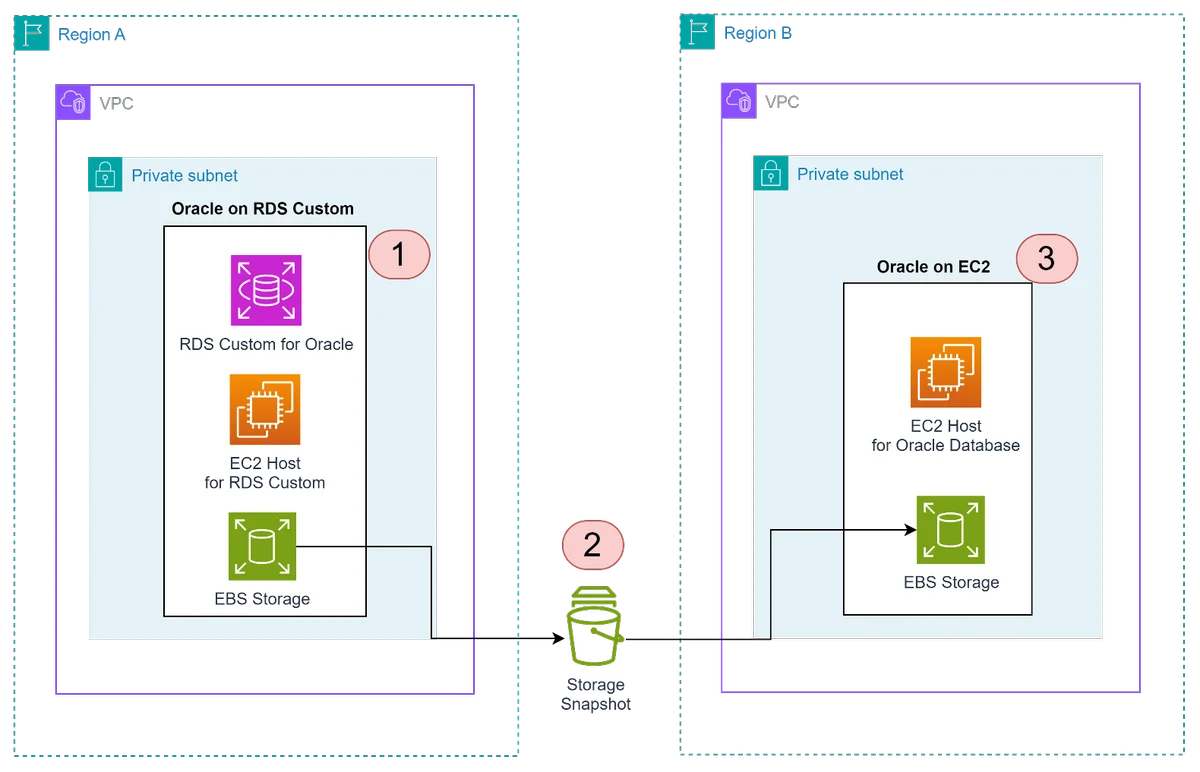
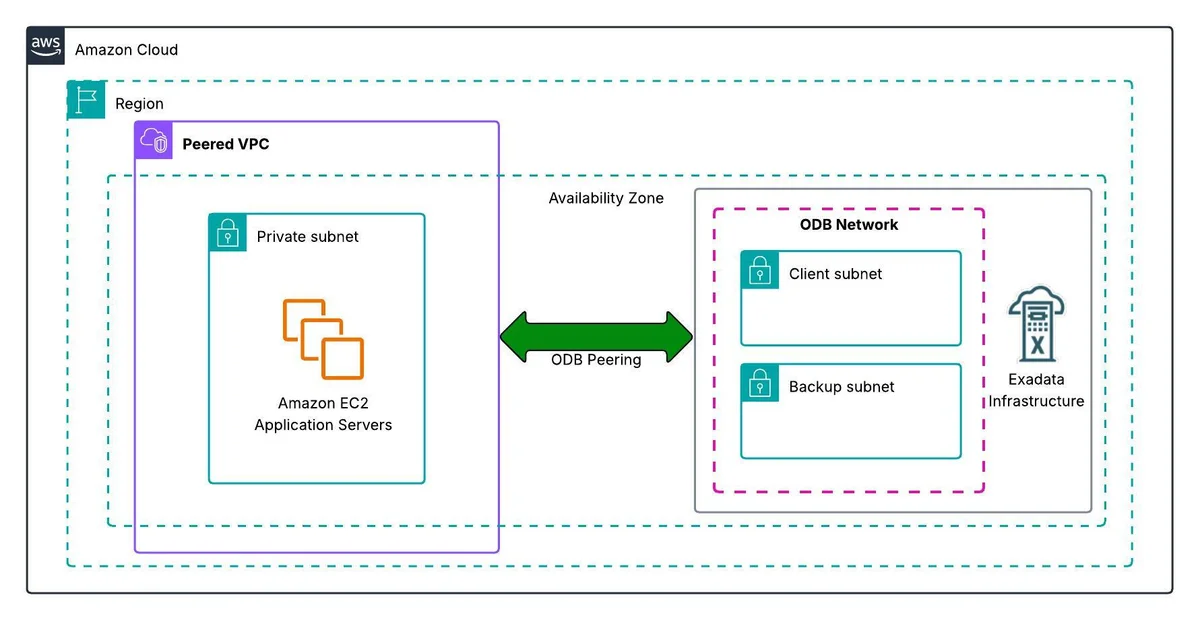
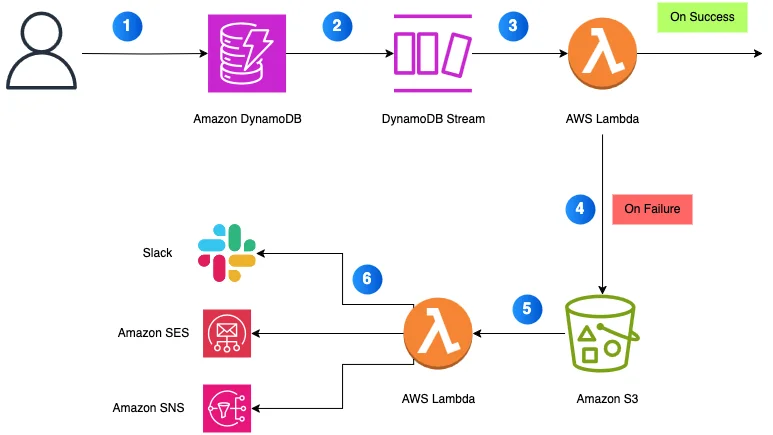
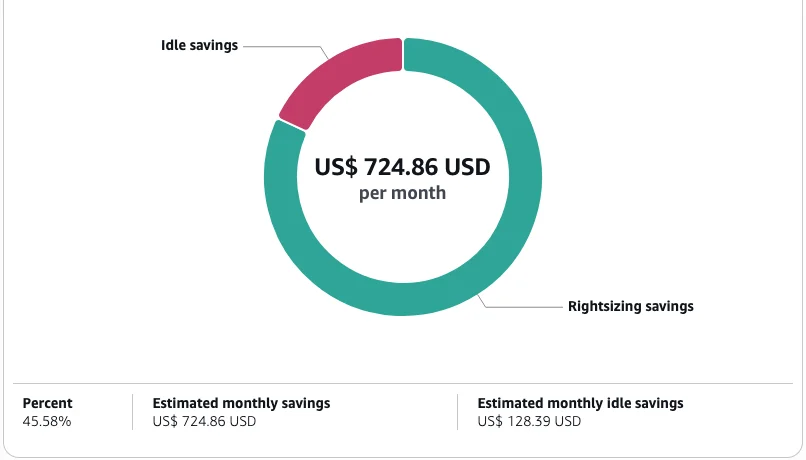
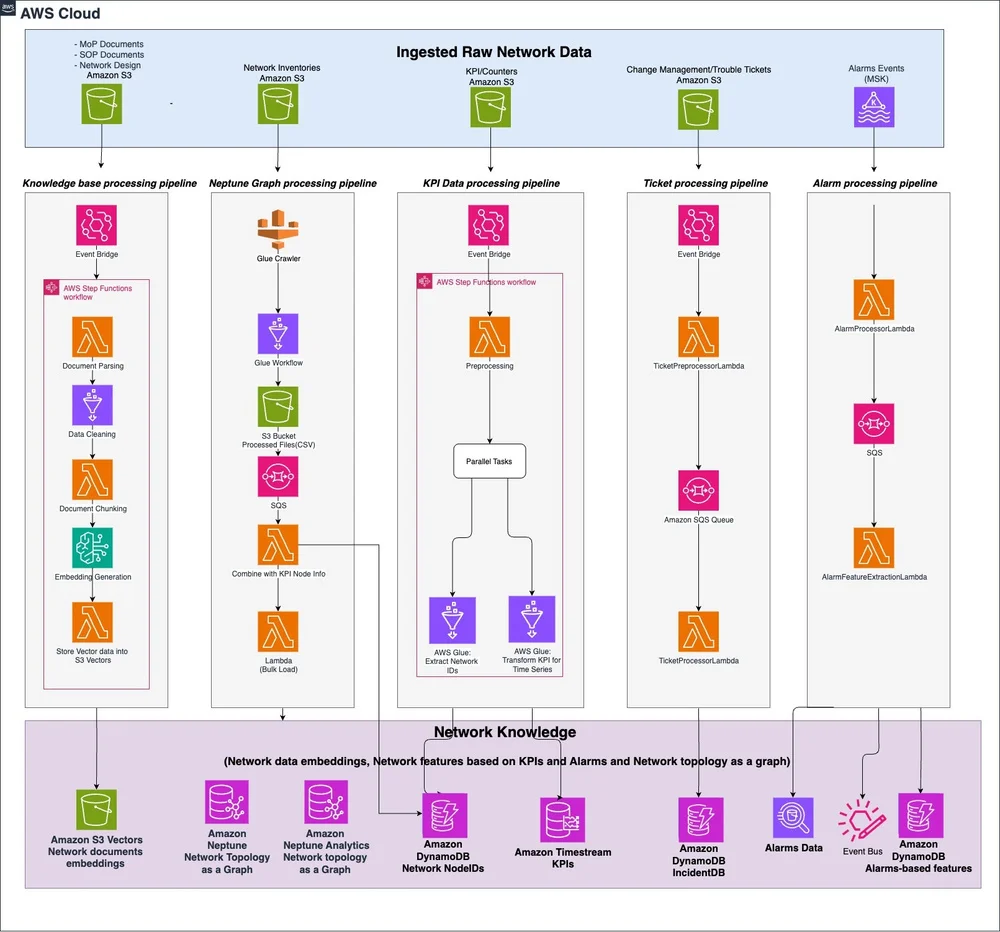
RSS AWS-Datenbank-Blog Folgen
Die Webseite bietet ein Amazon Web Services (AWS)-Blog für Datenbanken, das sich bemüht, Benutzern zu helfen, AWS-Datenbankdienste effizient zu nutzen, indem es nützliche Tutorials, Tipps und Antworten auf häufig gestellte Fragen bereitstellt.