Skalierung der Pinterest-ML-Infrastruktur mit Ray: Von der Ausbildung bis hin zu End-to-End-ML-Pipelines
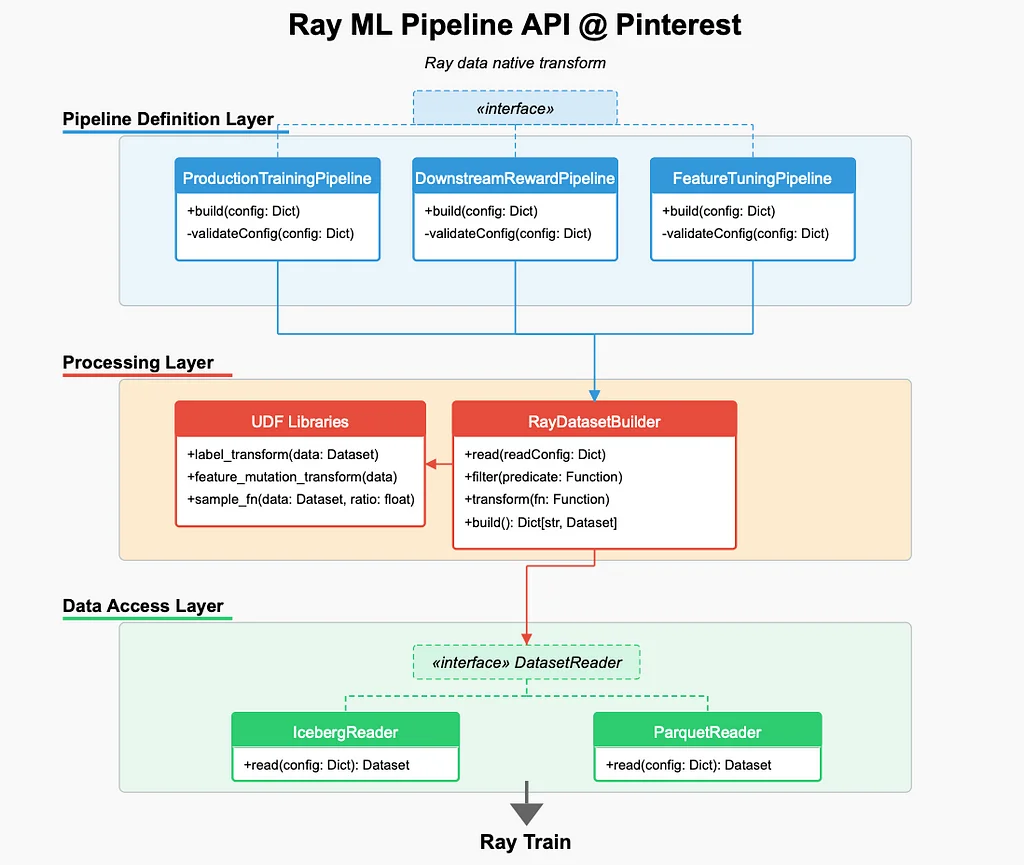
Bei Pinterest stehen ML-Ingenieure vor Herausforderungen bei der Optimierung der Feature-Entwicklung, Sampling-Strategien und Label-Experimenten aufgrund langsamer Daten-Pipelines, kostspieliger Feature-Iterationen und ineffizienter Compute-Nutzung. Um diese Herausforderungen anzugehen, erweiterte Pinterest die Fähigkeiten von Ray über das Training hinaus auf die Feature-Entwicklung, Sampling und Label-Modellierung. Die traditionelle ML-Infrastruktur war durch langsamer Daten-Pipelines, kostspieliger Feature-Iterationen und ineffiziente Compute-Nutzung eingeschränkt. Pinterest führte einen Ray-nativen ML-Infrastruktur-Stack ein, der sich auf vier Hauptverbesserungen konzentrierte: den Bau einer Ray-Daten-nativen Pipeline-API, effizientes Daten-Verbinden mit Iceberg-Bucket-Joins, Daten-Persistenz für effiziente Iteration und Ray-Daten-Optimierungen für große Workloads. Der neue Ray-basierte ML-Workflow reduziert die ML-Iterationszeiten um 10-mal, während die Infrastrukturkosten erheblich gesenkt werden. Die Ray-Daten-native Pipeline-API ermöglicht die Feature-Entwicklung, Sampling und Label-Transformationen nativ in Ray, eliminiert die Notwendigkeit von Spark-Backfills. Iceberg-Bucket-Joins ermöglichen schnelle und effiziente Feature-Verbindungen über verschiedene Quellen ohne vorherige Berechnung großer Tabellen. Daten-Persistenz ermöglicht effiziente Iteration durch Zwischenspeichern transformierter Features und Wiederverwendung, wenn anwendbar. Die Ray-Daten-Optimierungen erreichten eine 2-3-fache Geschwindigkeitssteigerung bei verschiedenen Pipelines, und der neue Workflow hat eine skalierbarere, effizientere und kosteneffektivere ML-Infrastruktur bei Pinterest freigeschaltet.