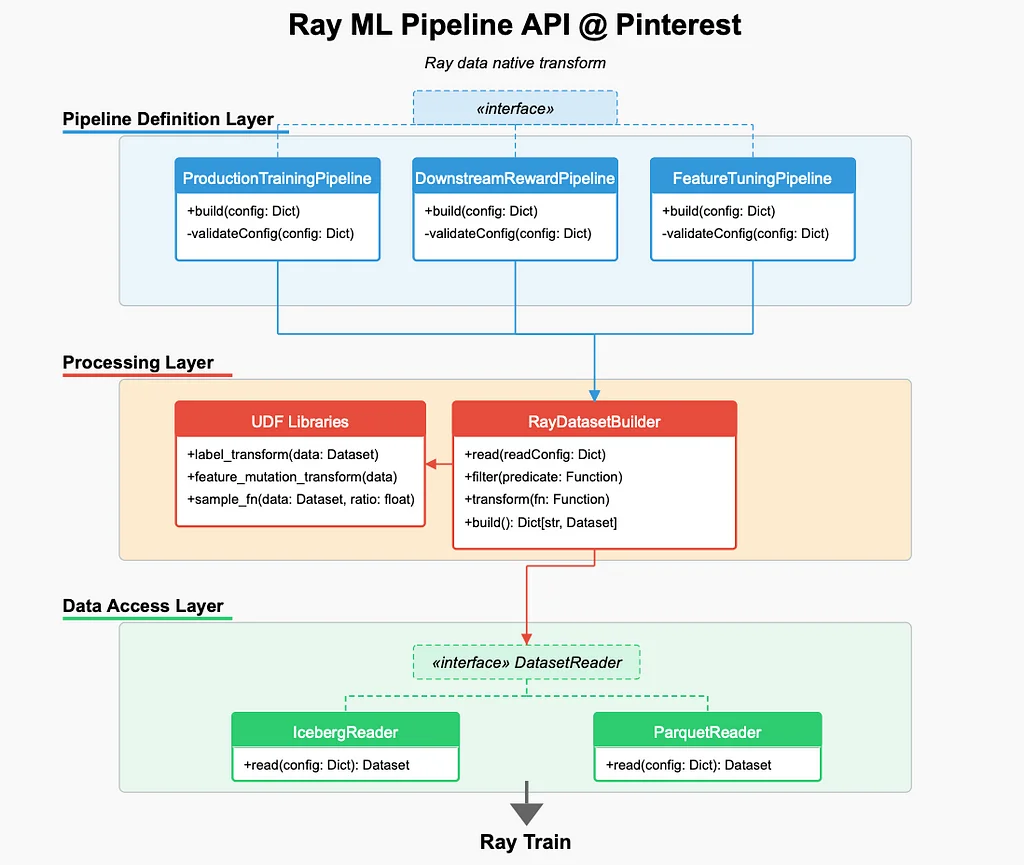
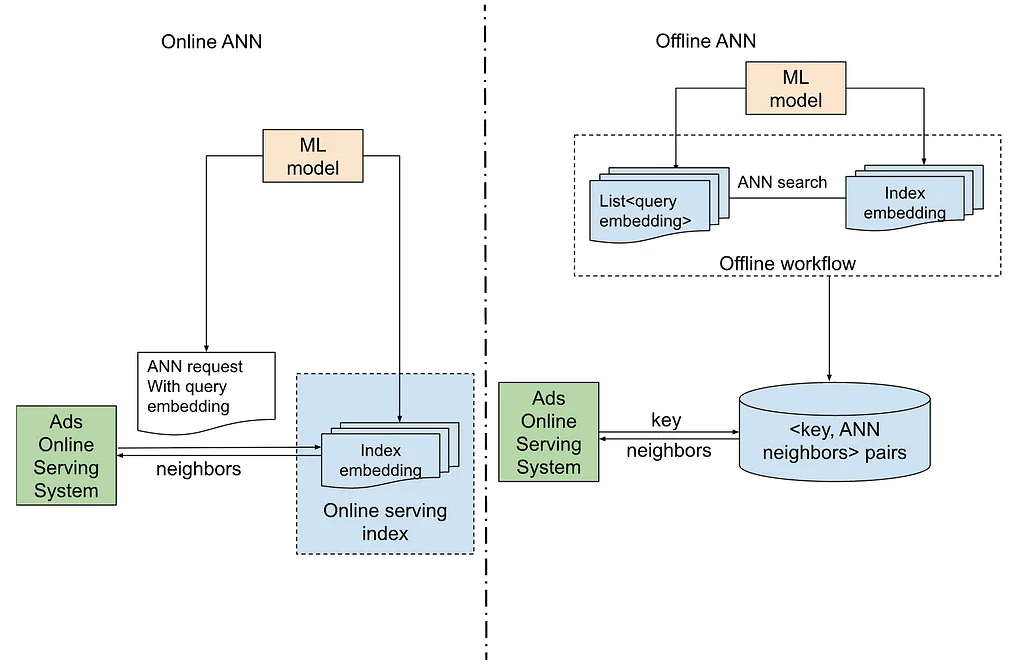
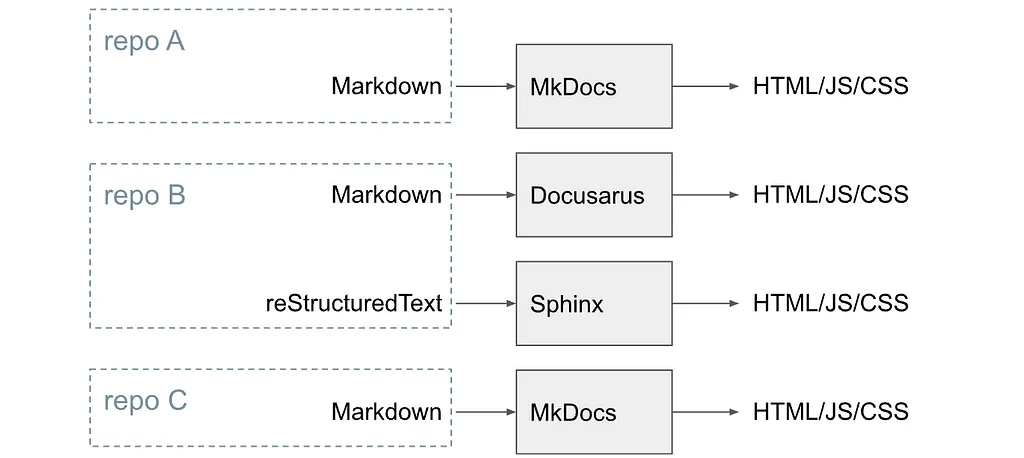
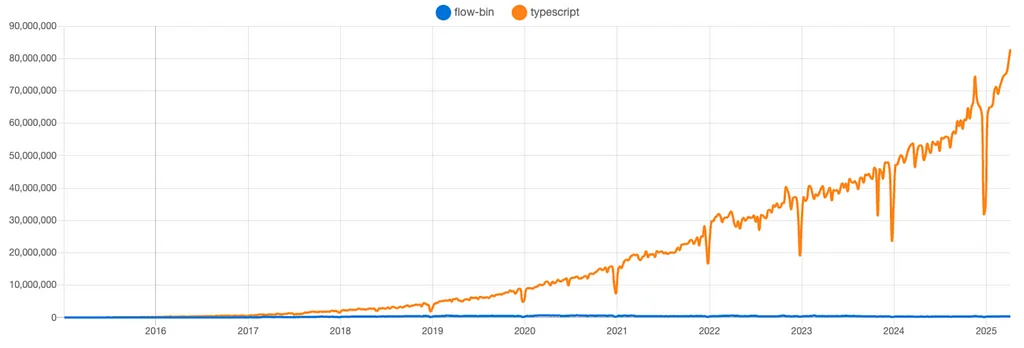
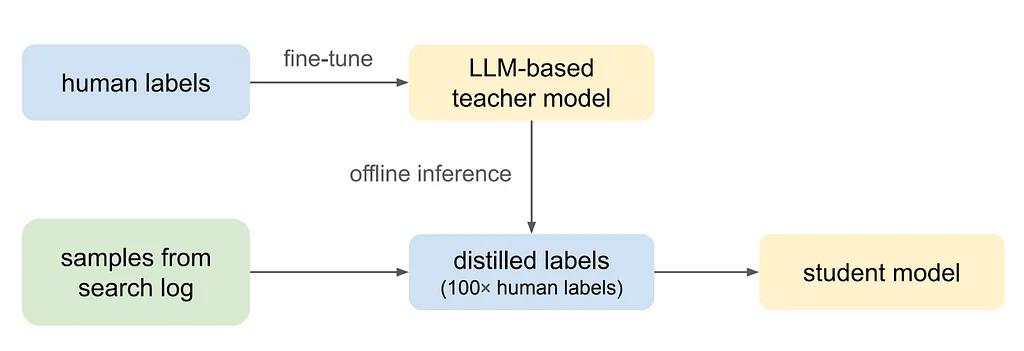
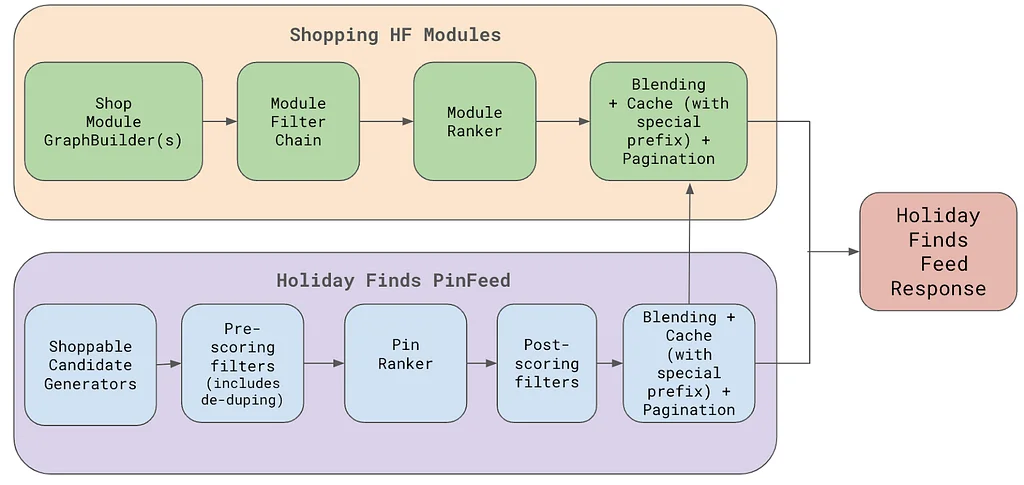
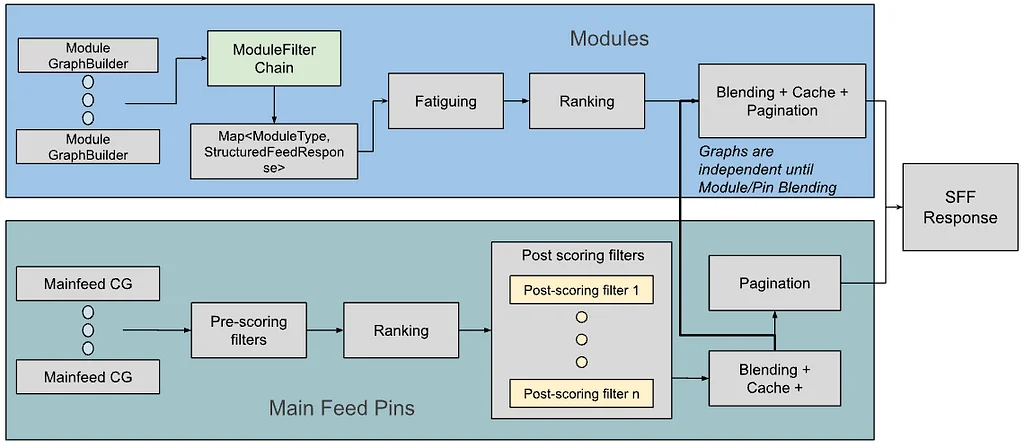
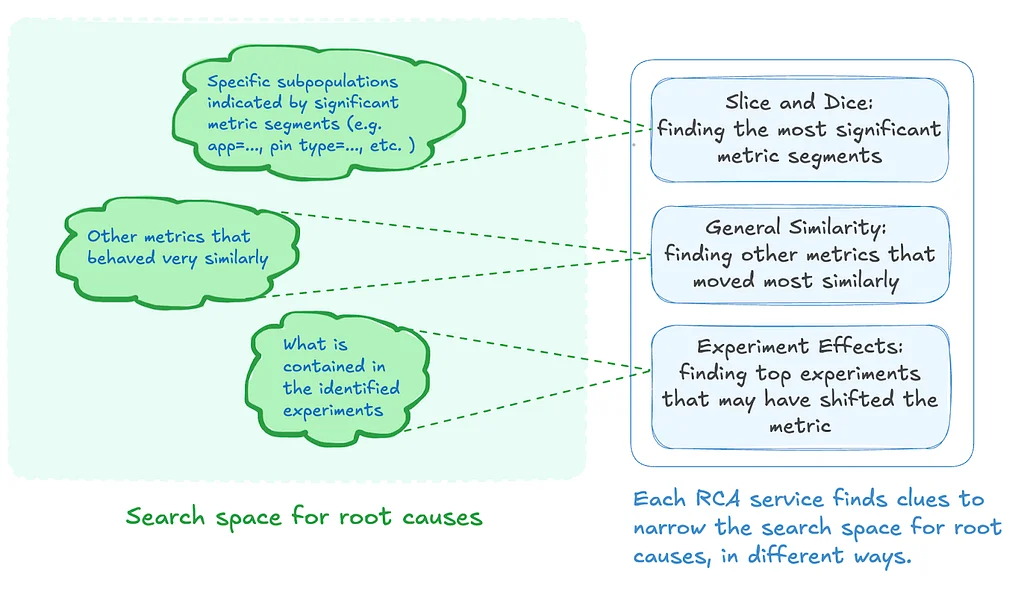
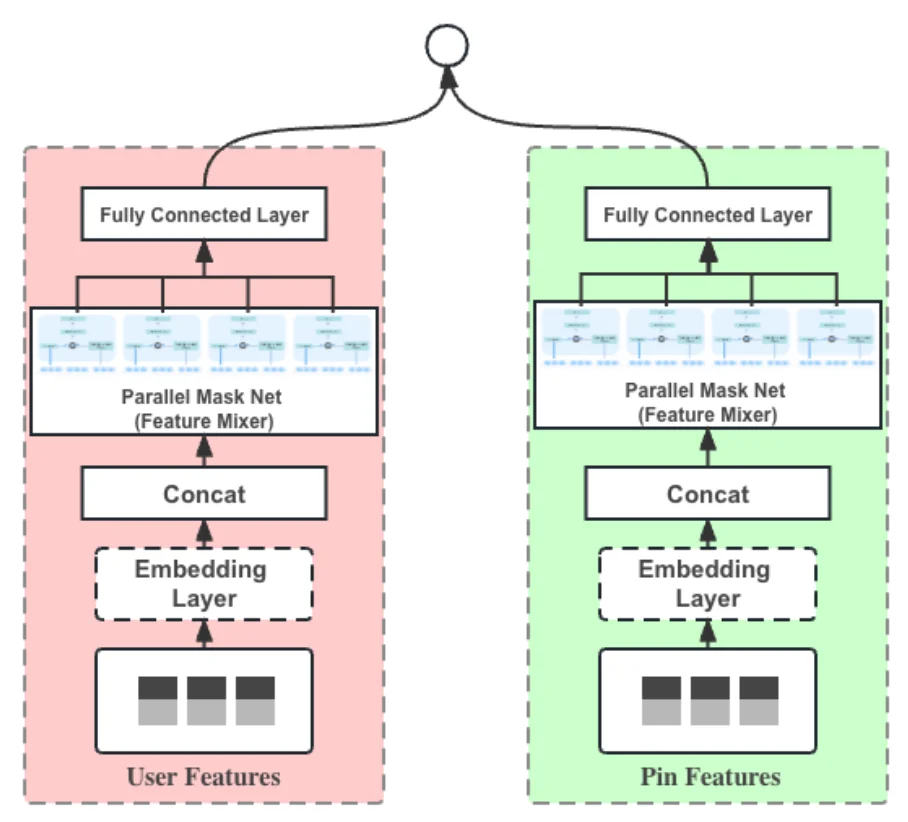
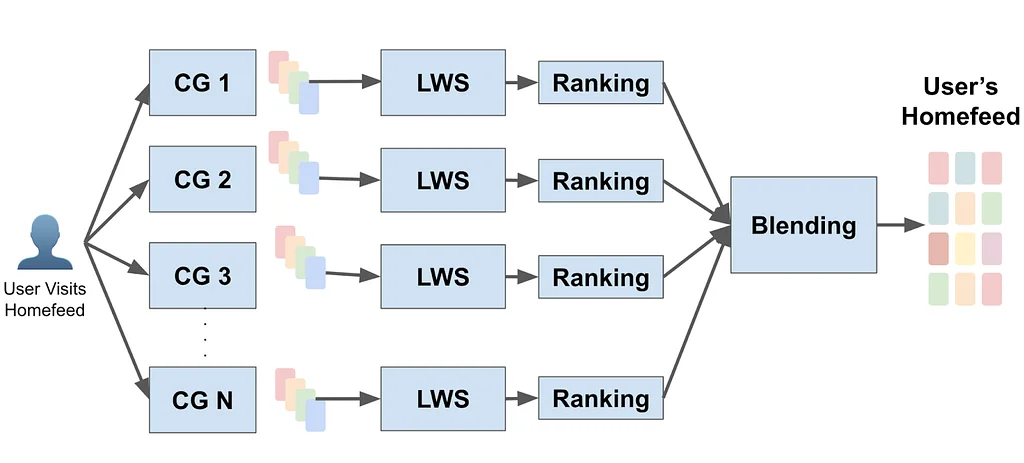
RSS-Geschichten von Pinterest Engineering auf Medium Folgen
Die Pinterest-Technik, auf Medium vorgestellt, bietet einen Blick hinter die Kulissen der technischen Innovationen, die die beliebte visuelle Entdeckungsplattform antreiben. Durch umfassende Artikel teilen Ingenieure Einblicke in ihre Arbeit an Skalierbarkeit, Machine Learning, Dateninfrastruktur und vielem mehr. Die Publikation hebt die Ingenieurkultur von Pinterest hervor, indem sie die Zusammenarbeit, das Experimentieren und die Leidenschaft für die Lösung komplexer Probleme betont. Leser können sich mit Themen wie dem Aufbau von Empfehlungssystemen, der Optimierung der Suchfunktion und der Entwicklung von Tools für Datenanalysen auseinandersetzen. Der Inhalt bietet wertvolle Perspektiven für Ingenieure und Technik-Enthusiasten, die sich für die Feinheiten einer groß angelegten Plattform wie Pinterest interessieren. Ob es um die Herausforderungen der Bilderkennung oder die Entwicklung ihrer Infrastruktur geht, die Pinterest-Technik auf Medium bietet einen faszinierenden Blick auf die technische Seite eines geliebten Online-Ziels.