Verbesserung der Suchrelevanz bei Pinterest mithilfe von großen Sprachmodellen
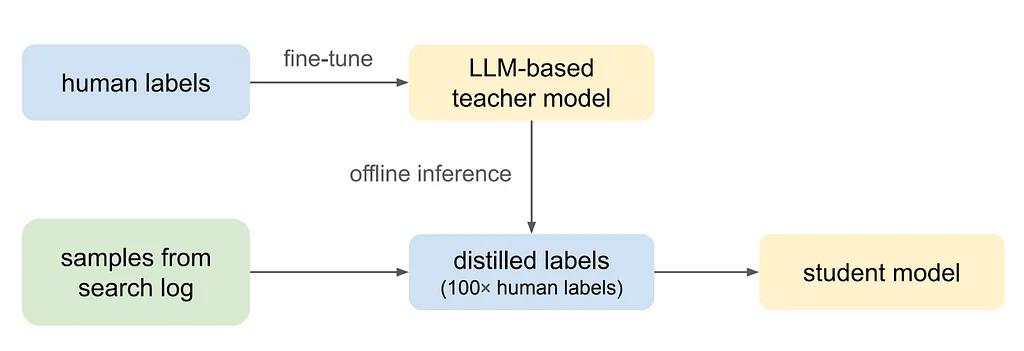
Die Pinterest-Suche ist eine wichtige Oberfläche, auf der Benutzer inspirierende Inhalte entdecken können, die ihren Informationsbedürfnissen entsprechen, und die Suchrelevanz misst, wie gut die Suchergebnisse mit der Suchanfrage übereinstimmen. Um das Suchrelevanzmodell zu verbessern, wird eine 5-Stufen-Richtlinie verwendet, um die Relevanz zwischen Anfragen und Pins zu messen. Ein Cross-Encoder-Sprachmodell wird verwendet, um die Relevanz eines Pins für eine Anfrage vorherzusagen, zusammen mit dem Pin-Text, und die Aufgabe wird als Multiklassen-Klassifizierungsproblem formuliert. Das Modell wird mit menschlich annotierten Daten fein abgestimmt, indem der Kreuzentropieverlust minimiert wird.Um jeden Pin darzustellen, wird eine vielfältige Menge von Textmerkmalen verwendet, einschließlich Pin-Titeln und -Beschreibungen, synthetischen Bildunterschriften, hochengagierten Anfrage-Tokens, benutzerkuratierten Board-Titeln und Link-Titeln und -Beschreibungen. Allerdings ist der Cross-Encoder-LLM-basierte Klassifizierer aufgrund von Echtzeit-Verzögerungen und Kostenüberlegungen für die Pinterest-Suche schwer skalierbar. Daher wird Wissensdestillation verwendet, um das LLM-basierte Lehrermodell in ein leichtes Schüler-Relevanzmodell zu destillieren.Das Schülermodell verwendet Anfrage-merkmalen, Pin-merkmalen und Anfrage-Pin-Interaktionsmerkmalen, um 5-Skalen-Relevanzwerte vorherzusagen. Wissensdestillation und semi-überwachtes Lernen werden eingesetzt, um das Schülermodell zu trainieren, das effektiv eine große Menge an ursprünglich unbeschrifteten Daten nutzt und die Daten auf eine breite Palette von Sprachen aus der ganzen Welt erweitert.Offline-Experimente zeigen die Wirksamkeit jeder Modellierungsentscheidung, einschließlich des Vergleichs von Sprachmodellen, der Bedeutung der Anreicherung von Textmerkmalen und der Skalierung von Trainingslabels durch Destillation. Online-Ergebnisse zeigen eine Verbesserung der Suchrelevanz um +2,18 % im Suchfeed, gemessen durch nDCG@20, und einen deutlichen Anstieg der Sucherfüllungsraten weltweit.Die vorgeschlagene Relevanzmodellierungspipeline verallgemeinert sich effektiv auf Sprachen, die während des Trainings nicht begegnet sind, und das multilinguale LLM-basierte Relevanzlehrmodell verallgemeinert sich auf ungelöste Sprachen. Zukünftige Arbeiten werden die Integration von servierbaren LLMs, vision-and-language-Multimodellmodellen und aktiven Lernstrategien erforschen, um die Qualität der Trainingsdaten dynamisch zu skalieren und zu verbessern.