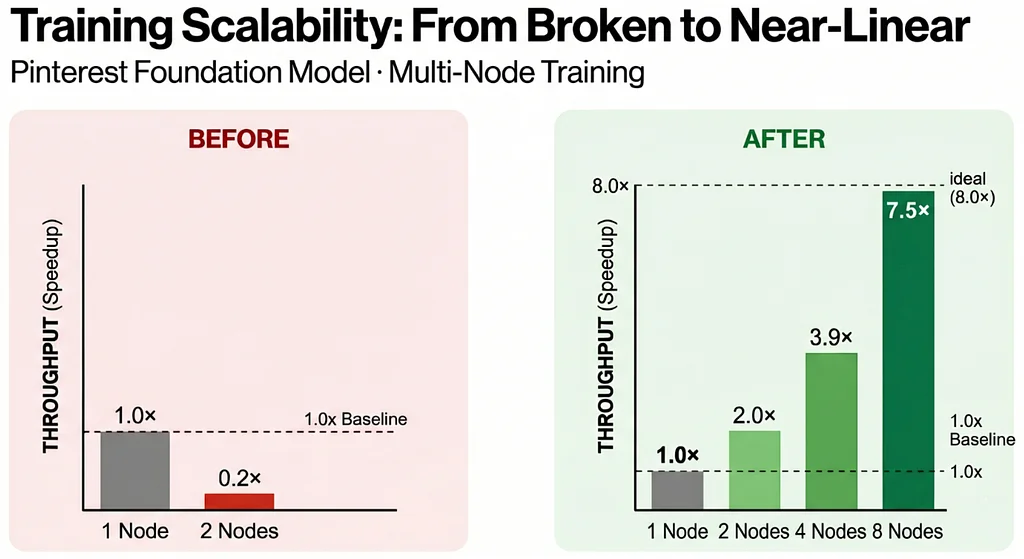
Achieving Near-Linear Training Scalability for Pinterest’s Foundation Models
Pinterest's foundation models are crucial for their recommendation systems, impacting millions of users daily. Initially, multi-node training for these large models performed poorly, with adding more machines drastically slowing down the process. Even with AWS Elastic Fabric Adapter (EFA) for improved networking, scaling remained inefficient. Profiling revealed that distributed embedding lookups caused significant communication bottlenecks, with GPUs waiting on data. The team implemented several optimizations to address this communication overhead. Quantized Communications (QComms) reduced the data payload by compressing embedding tensors. Balanced sharding improved workload distribution across GPUs. Bandwidth-aware embedding optimization halved embedding dimensions to decrease data movement. A key breakthrough was implementing 2D Parallelism, initially optimizing for AllReduce, which improved local communication. Finally, they flipped the 2D Parallelism topology to optimize for All-to-All, keeping expensive operations within nodes and using cheaper AllReduce for cross-node synchronization. This led to near-linear scaling, achieving 2.0x at 2 nodes and 3.9x at 4 nodes, and an impressive 7.5x scaling at 8 nodes. These advancements enabled training larger models, resulting in significant user engagement gains on Pinterest's recommendation surfaces and faster experimentation cycles.