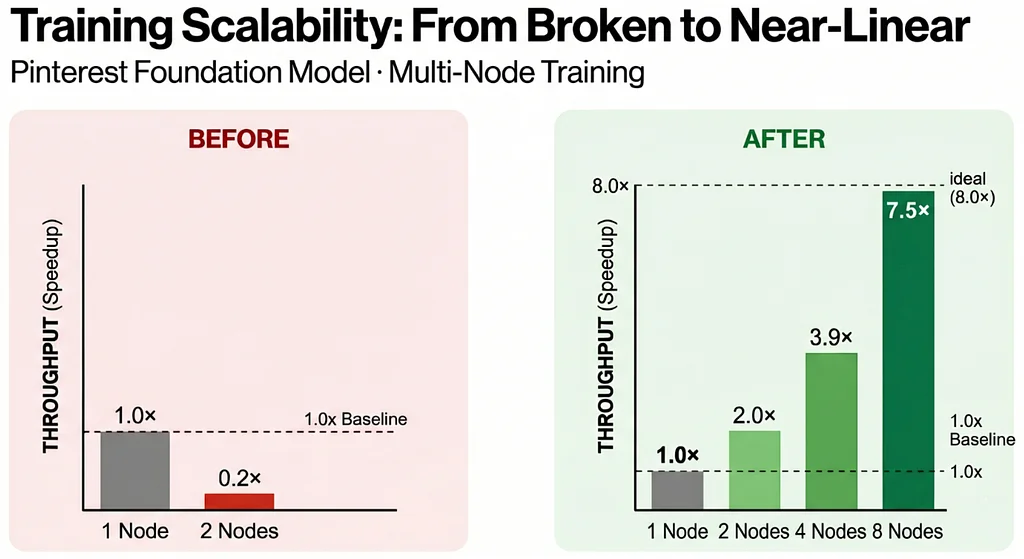
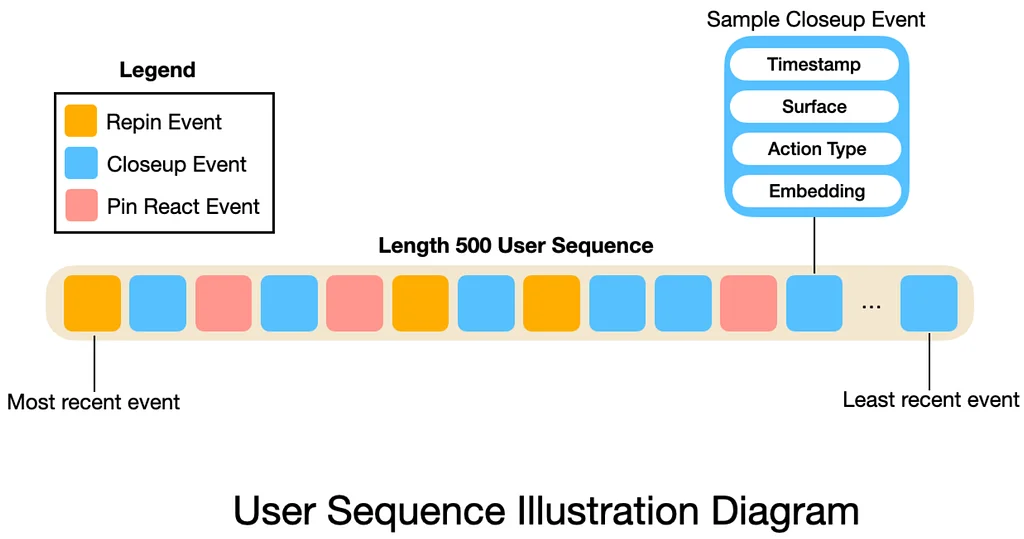
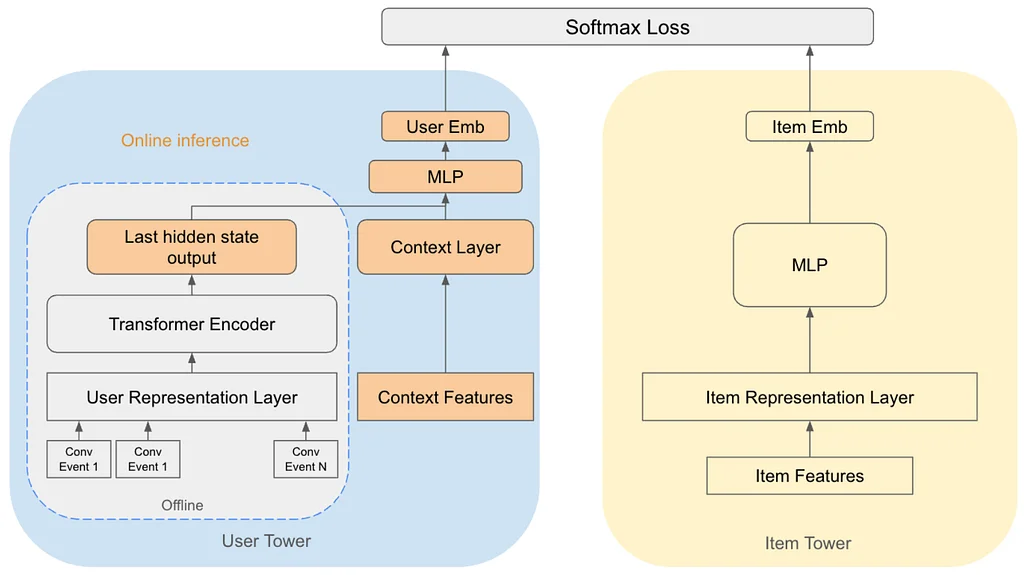
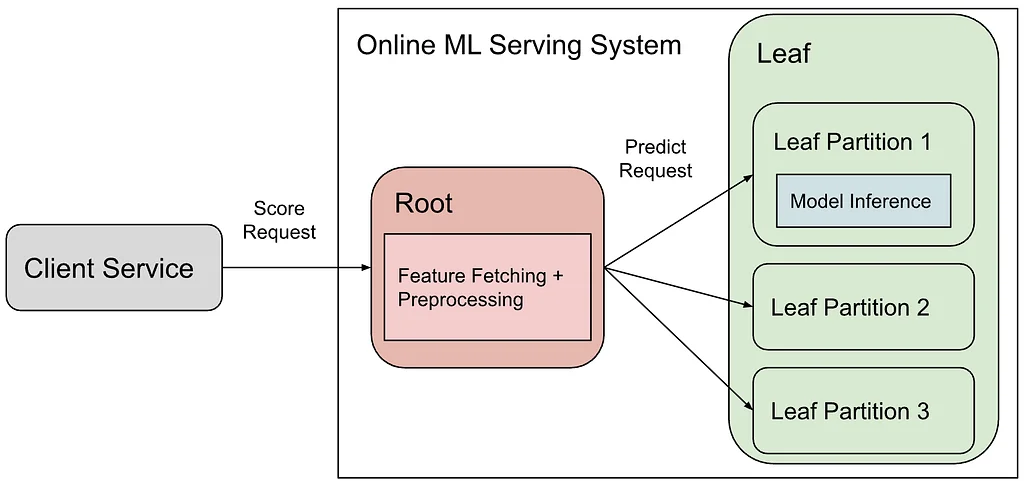
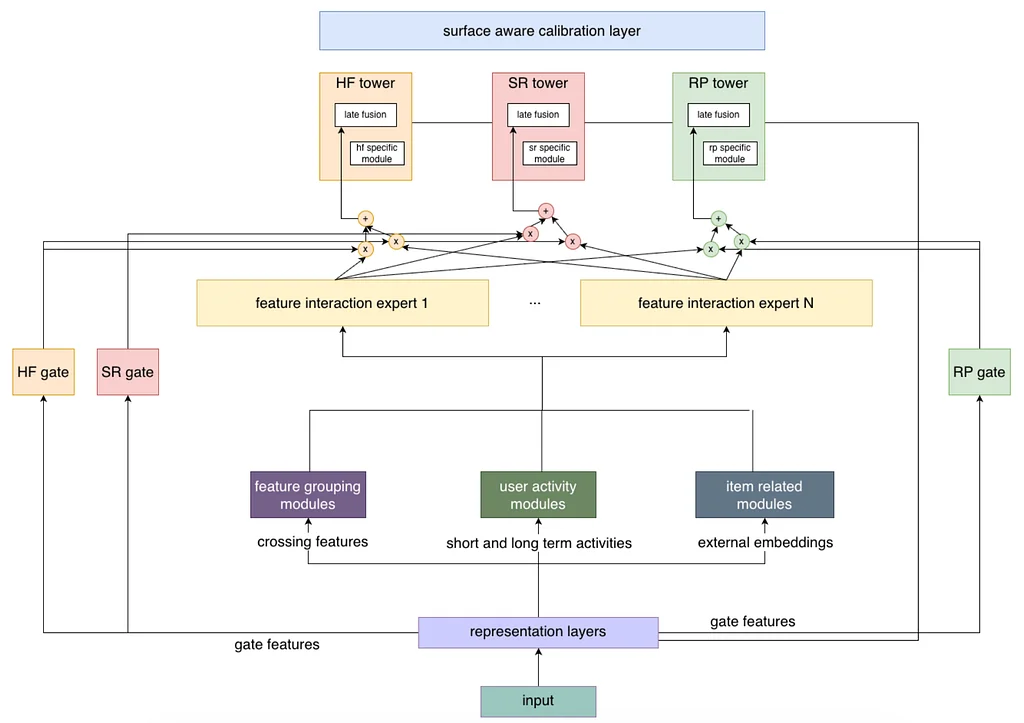
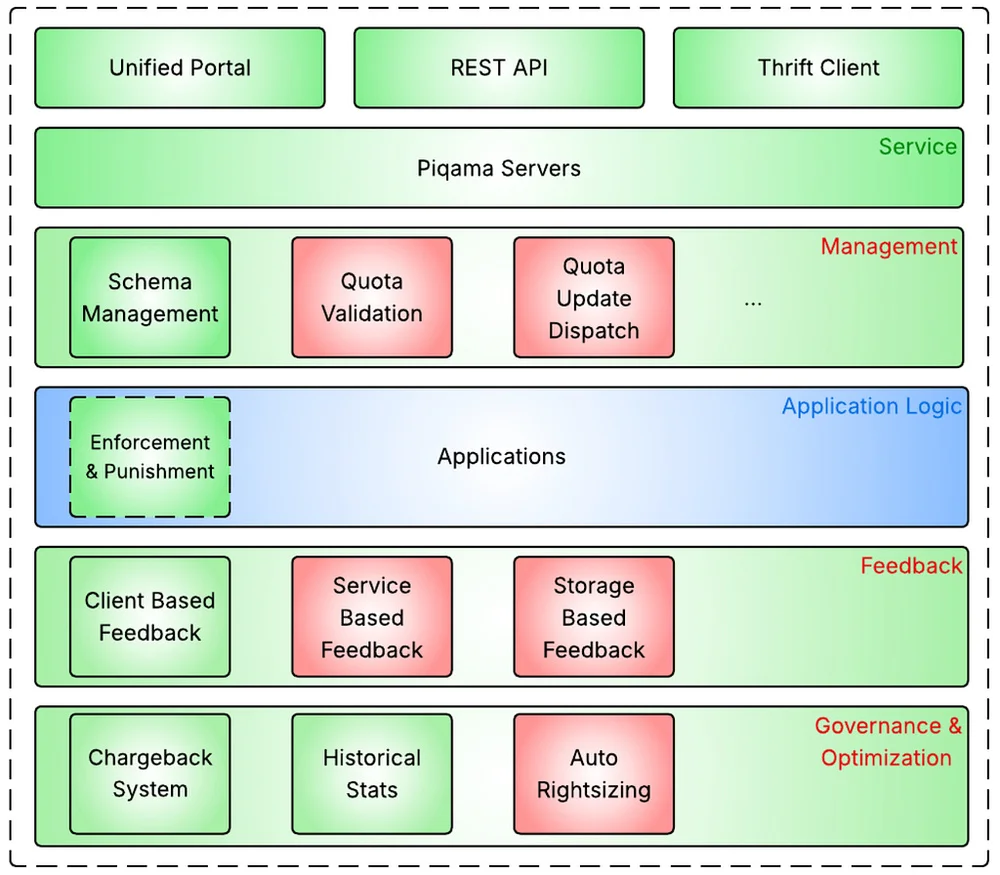
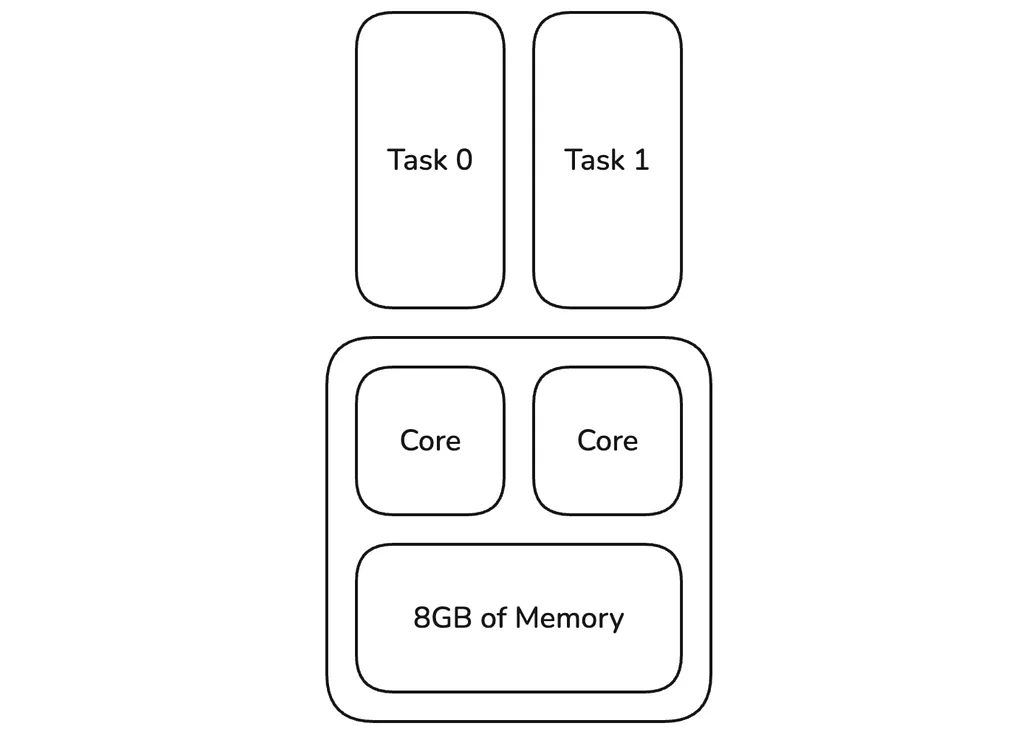
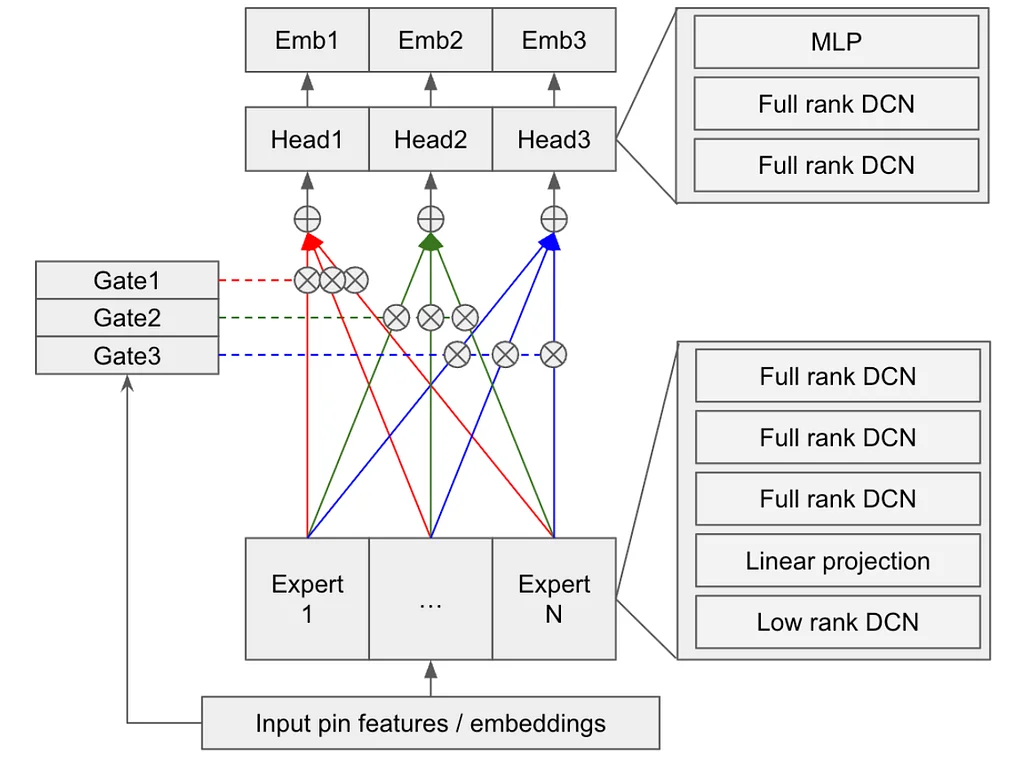
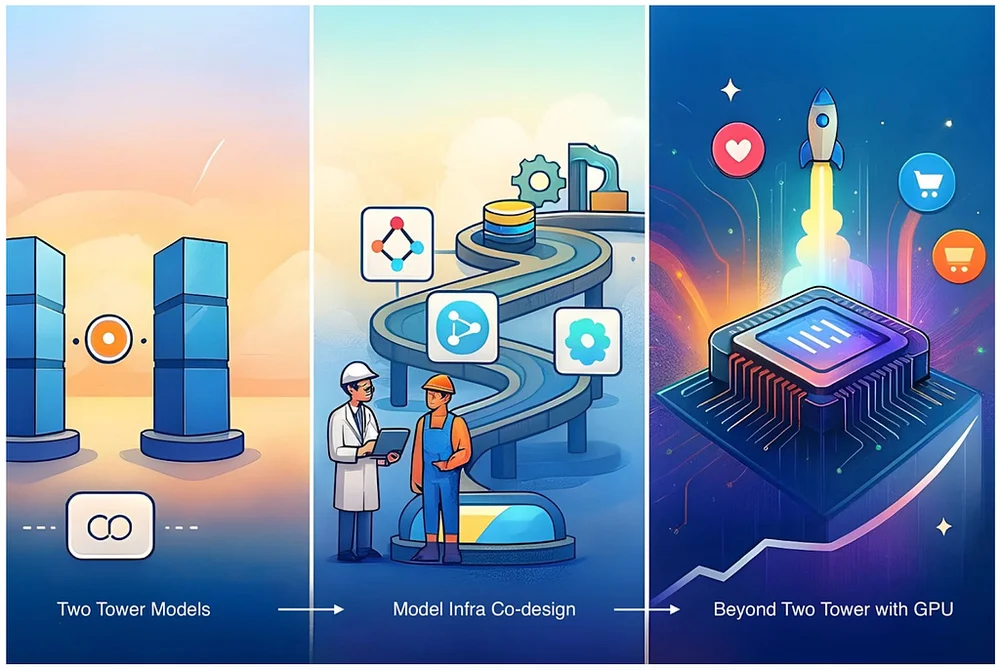
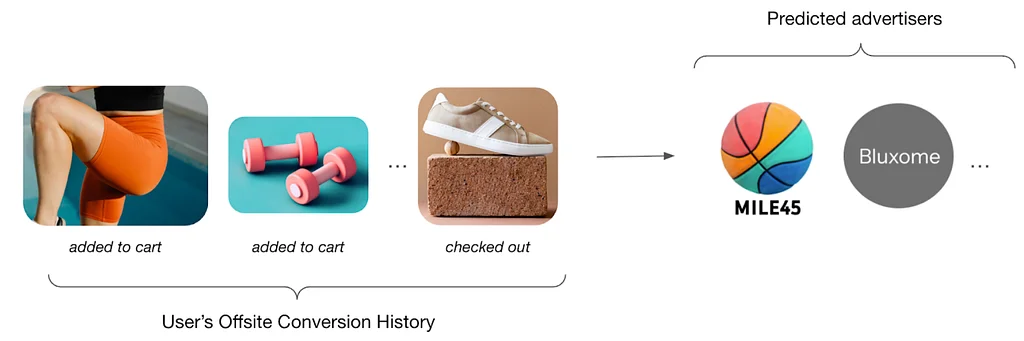
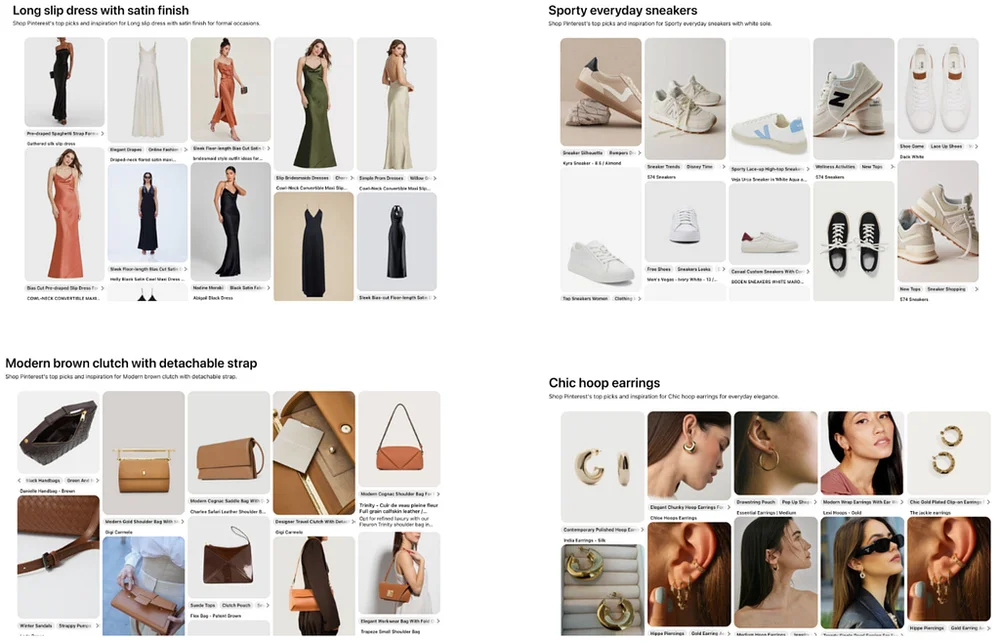
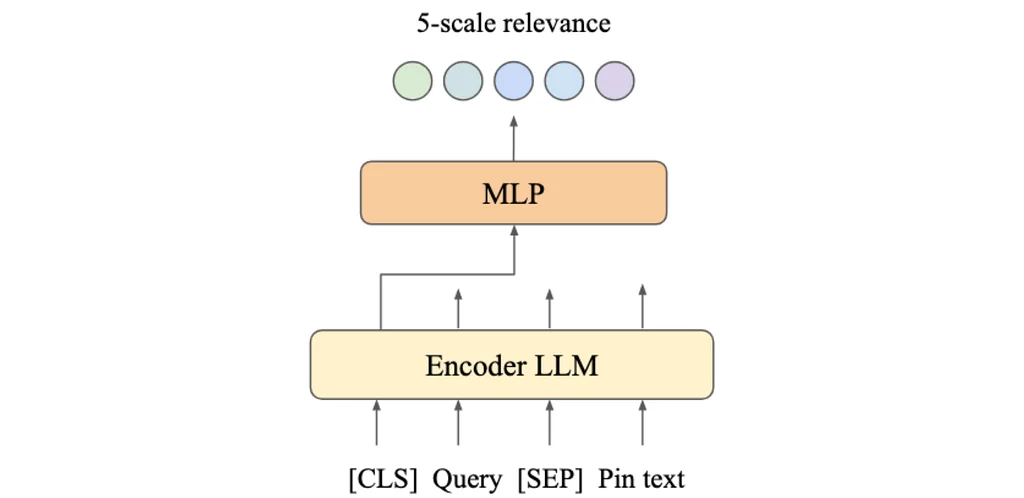
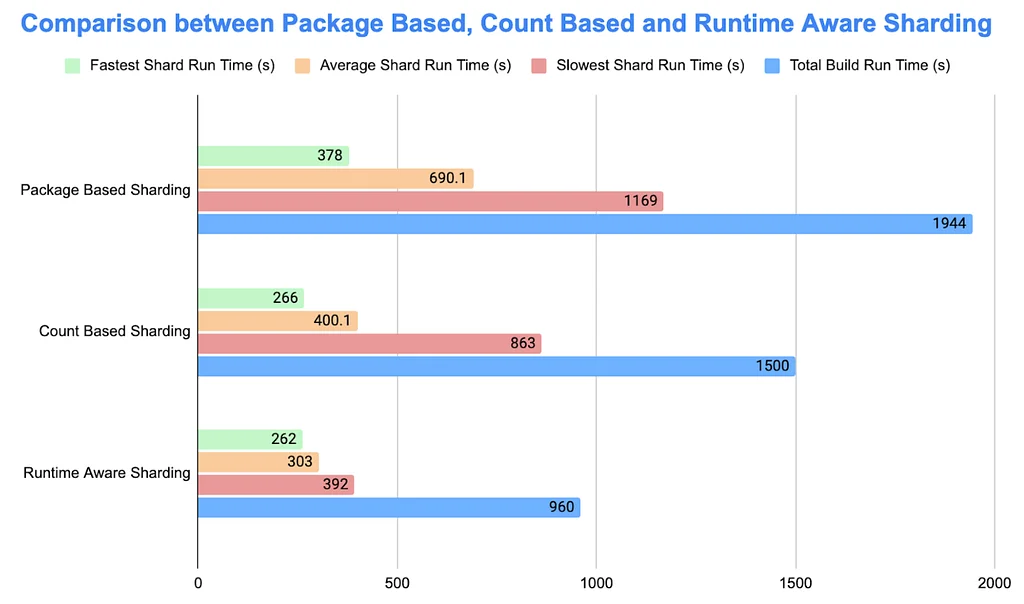
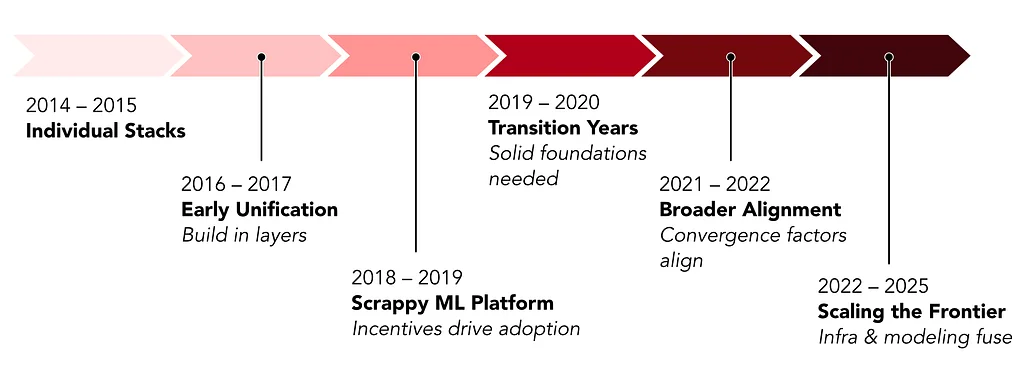
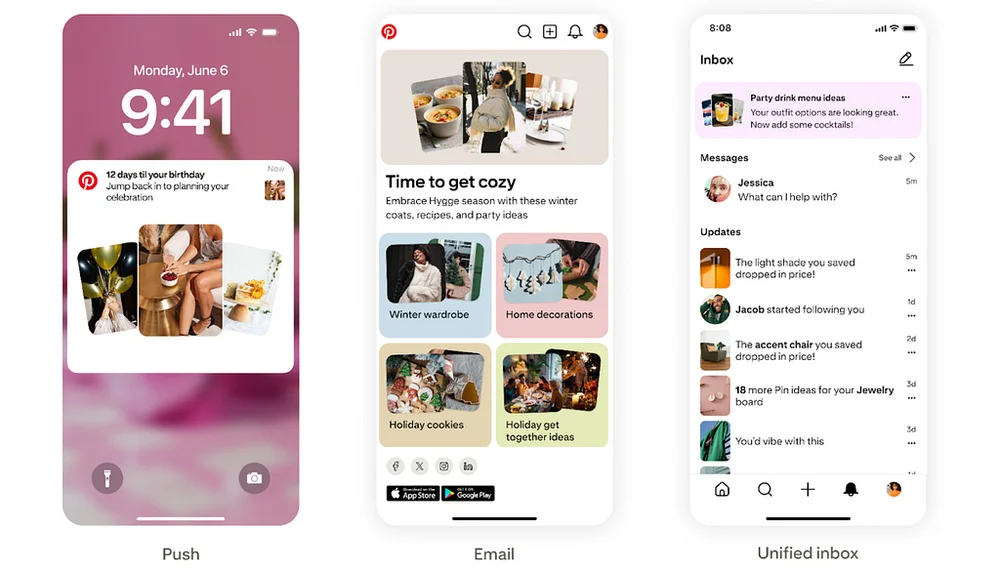
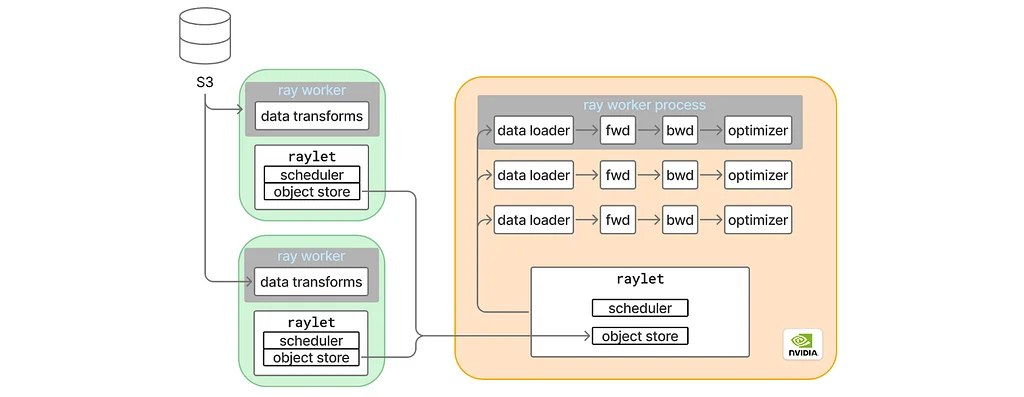
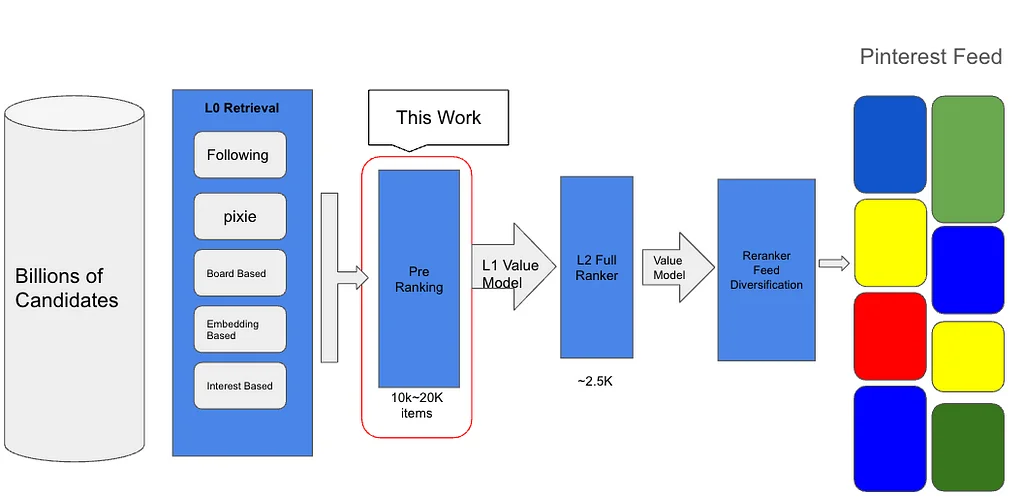
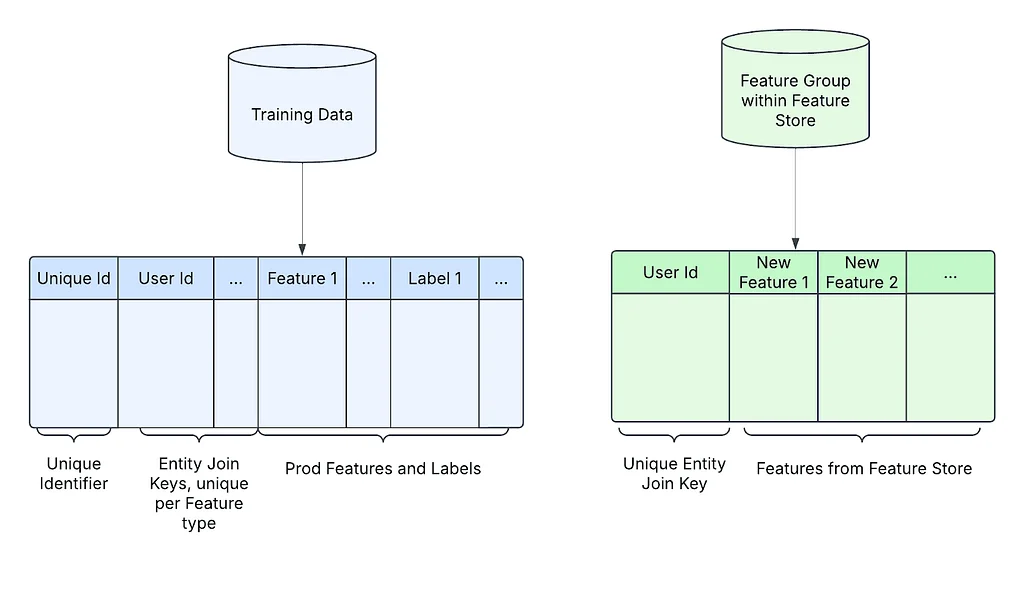
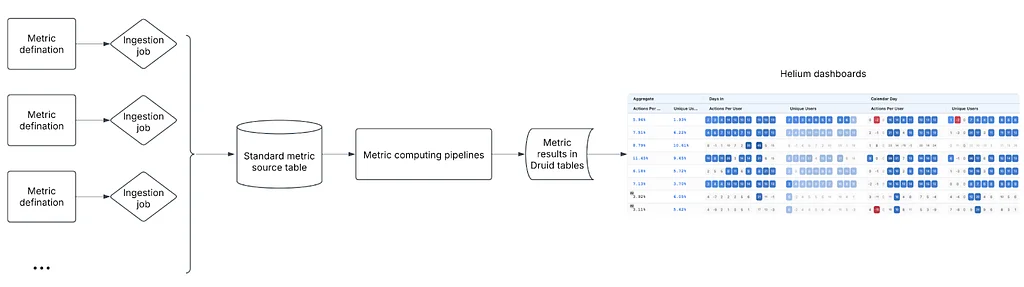
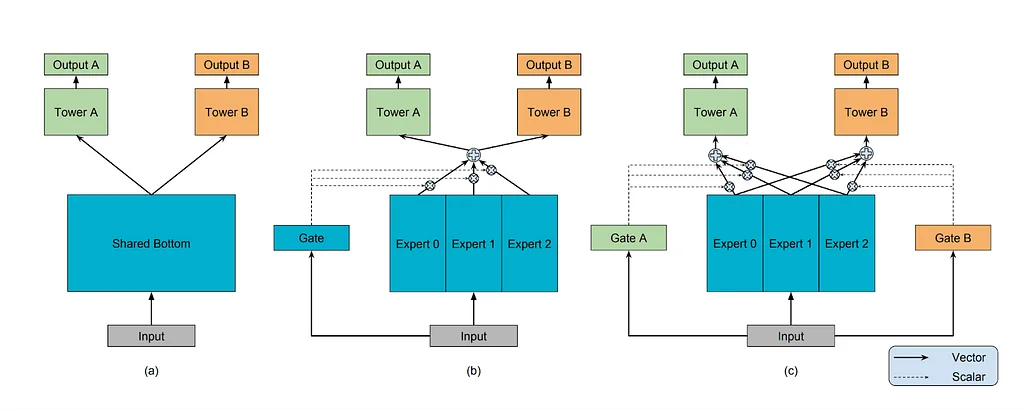
Pinterest Engineering | Medium Follow
Pinterest Engineering, showcased on Medium, provides a behind-the-scenes look at the technological innovations driving the popular visual discovery platform. Through in-depth articles, engineers share insights into their work on scalability, machine learning, data infrastructure, and more. The publication highlights Pinterest's engineering culture, emphasizing collaboration, experimentation, and a passion for solving complex problems. Readers can explore topics like building recommendation systems, optimizing search functionality, and developing tools for data analysis. The content offers valuable perspectives for engineers and tech enthusiasts interested in the intricacies of a large-scale platform like Pinterest. Whether delving into the challenges of image recognition or the evolution of their infrastructure, Pinterest Engineering on Medium provides a fascinating glimpse into the technical side of a beloved online destination.